
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
点云存在许多描述环境或建筑物等物体的 x、y、z 坐标。通过激光技术 (LiDAR) 获取的点云通常带有每个坐标的额外测量值和特征。例如,反射强度、回波次数、回波、扫描角度和 RGB 值。换句话说,点云本质上是大量的数据集。
在本文中,我们使用开源点数据抽象库 (PDAL) 演示了这些大型数据集的大规模处理,并使用 Azure Batch 运行。
1、使用 PDAL 进行处理
LiDAR 数据的处理是通过开源库 PDAL 完成的。使用此库,点云数据可以在许多不同的格式之间进行转换,例如,las、laz、geotif、geojson、ascii、pgpointcloud、hdf5、numpy、tiledDB、ept 等,以及专有数据格式。
此外,该库还可以对数据进行过滤操作,例如重投影、分类、过滤、DEM 和网格创建等。PDAL 可以作为应用程序单独执行,并且还有一个 Python PDAL 扩展,以便 PDAL 可以成为你的Python应用程序。这使得你可以灵活地将自己的处理逻辑或滤波器合并到你的 LiDAR 处理中。
PDAL 扩展可与以 json 格式定义并通过 pdal 实现执行的管道配合使用。下面的管道示例说明了所有依赖于 PDAL 内置功能的以下步骤:

- 使用设置的参考投影读取输入 las 或 laz 文件(此处为 EPSG:28992,荷兰的投影坐标系),
- 应用对地面和非地面点进行分类的filters.csf(布料模拟过滤器,Zhang et al. 2016),
- 应用仅选择地面回波的过滤器,
- 将过滤后的数据写入las文件
该管道使用 AHN3 的示例数据集执行,AHN3 是荷兰南林堡地区全国 LiDAR 开放数据集的第三版。下面,使用 plas.io 创建了两个视觉效果,a)原始数据集,b)使用管道创建的数据集,显示地面回报,基于Zhang等人,2016年的PDAL实现。

2、使用 Azure Batch 进行扩展
由于数据量和应用的算法类型,处理 LiDAR 数据是计算密集型的。扩展处理规模可能是一个挑战。 Azure Batch 是一项在 Azure 中高效运行大规模并行和高性能计算 (HPC) 批处理作业的服务。 Azure Batch 创建和管理计算节点(虚拟机)池,安装要运行的应用程序,并安排作业在节点上运行。在这里,应用程序将是处理 LiDAR 数据的 (Python) 脚本。 Azure Batch 可以通过 Azure 门户、Azure Batch API 和 Azure Batch SDK 进行管理。由于地理空间和地球科学领域的许多开发人员和研究人员都熟悉 Python,因此这里使用 Azure Batch Python SDK。
一般概念如下图所示。通过本地 Python 客户端,Azure Batch 计算池在现有的 Azure 资源组中使用存储帐户和 Azure Batch 帐户进行预配。使用客户端将应用程序/脚本和数据上传到 blob 存储(下图中的 1)。然后,使用提供的 Azure Batch 帐户凭据,将创建一个计算池,并提交任务和作业 (2)。通过这样做,计算池将应用程序和数据拉至计算节点,执行处理,并将结果推回到 blob 存储 (3)。为了更好地理解此概念的实现,本博文附有 Azure Batch 上 PDAL 工作示例的 GitHub 存储库。
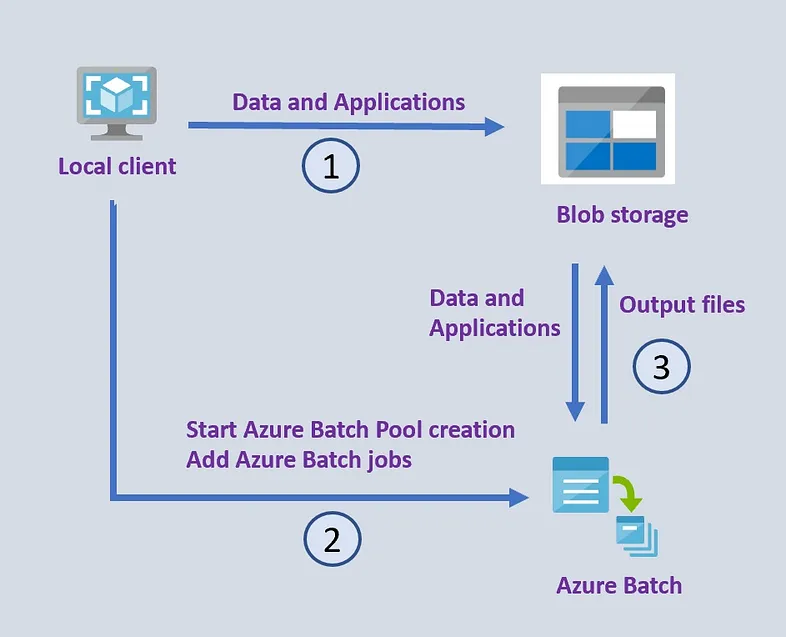
Azure Batch 的常规设置:
- 本地客户端将数据和应用程序文件上传到Azure Blob存储
- 使用Azure Batch的Python SDK,本地客户端开始创建Azure Batch池,然后可以添加Azure批处理作业以在LiDAR文件上运行
- Azure Batch 自动安排作业和任务、执行处理并将输出文件上传到 Azure Blob 存储。
为了与 Azure 存储和 Azure Batch 正确通信,客户端环境需要两个 Python 库,即 azure-batch 和 azure-storage-blob(此处分别使用版本 10.0.0 和 12.8.1)。
针对 LiDAR 数据运行的应用程序/Python 脚本需要 PDAL 库,建议从 conda-forge 安装。在启动 Azure Batch Pool 期间,首先将下载(mini)conda 环境,以静默模式安装并启动,这是通过 StartTask.sh 完成的 - 在上图的步骤 2 中(请参阅存储库以获取技术说明和示例) )。
创建Azure池后,可以提交作业。对于每个输入 LiDAR 文件,将执行 Python 脚本(包括 PDAL 管道),并将输出 las 文件上传到 Azure blob 存储以实现持久性。
根据 LiDAR 文件的大小和数量以及要运行的管道的复杂性,您可以创建小型(1 个节点)到非常大(> 1000 个节点)的 Azure Batch 池,无论是否启用自动缩放选项。这只需要重新缩放池,Azure Batch 确实处理作业调度和管理,因此提供的代码可以用于大型和小型批处理作业,而无需对代码本身进行任何更改。
原文链接:Point clouds in the cloud
BimAnt翻译整理,转载请标明出处





