
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
当德国计算神经学家 Bernd Fritzke 在其 1995 年的开创性论文中提出后来被称为神经气体生长(GNG)的算法时,机器学习还是一个相对较新的领域,并且受到实际神经科学的极大启发。
当时,神经科学正处于一个突破性的时代——这在很大程度上要归功于新的神经成像方法,包括功能性神经成像 (fMRI)、脑磁图 (MEG) 和扩散张量成像 (DTI)。这启发了计算机科学家创建类似于神经元工作方式的模型。
例如,深度学习(尤其是深度卷积神经网络)可能最多受到大脑处理信息的方式的启发,特别是大脑处理“什么”部分(称为腹侧视觉流)的视觉信息,而不是“哪里”部分(由背侧视觉流处理),但最初的灵感来自这些因素。最初的类比足以创建一个具有可行数学类比的模型,然后可以使用实际视觉系统中不存在的东西(例如卷积核)对其进行扩展。
神经气体同样从一种称为赫布学习(hebbian learning)的神经过程中获得了模糊的灵感。这一理论可以追溯到 20 世纪 40 年代末,它试图通过以下事实来解释联想学习现象:如果两个足够接近的神经元倾向于同时激发,那么它们最终将更有可能形成突触连接。
当然,这是一个彻底的简化(如果你对这种情况的程度感兴趣,Rumsey 和 Abbott 在《生理学》上发表的这篇论文是一个很好的介绍),但它启发了人工神经网络中的想法,即神经元之间的连接应该越频繁地同时激活(“同时激发的神经元会连接在一起”),它们之间的连接就越强。
1、神经气体生长算法

神经气体生长(Growing Neural Gas)算法仅用几百步就“学习”了我脸部的拓扑结构。该图由 752 个节点组成,非常容易辨认,不到构成图像的原始 15,564 个蓝点的 5%。
神经气体生长是一种相对简单的算法,就像我们在上一章中遇到的另一个竞争模型一样,它允许学习和表示拓扑。因此,它是一种拓扑表示网络,正如我们在第 1 部分中看到的那样,它能够近似人脸拓扑这样复杂的东西——产生人类观察者可以识别的东西,同时显著减少信息。例如,左侧的动画表明,可以非常高效地近似人脸这样复杂的东西,以创建观察者无法识别的图像。
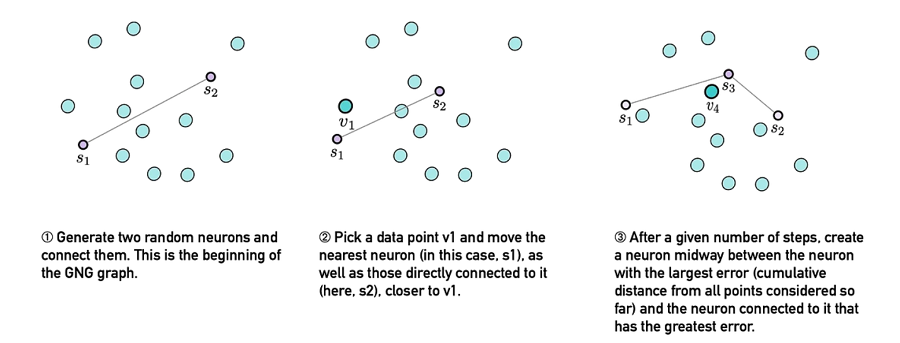
神经气体生长算法的总体思路是:从两个随机放置的神经元开始,每隔一段时间在迄今为止表现最差的神经元和其表现最差的邻居之间添加新的神经元。这个过程会不断迭代,直到达到边界条件(例如最大迭代次数)。请注意,上述解释忽略了边老化和年龄下降。
就像之前的帖子一样,我将把严格的数学留给配套的笔记本,并坚持解释总体思路。就像自组织特征图一样,GNG 是迭代算法。然而,与 SOFM 不同,它们不需要对神经元的数量进行任何初始指定——顾名思义,GNG 是不断增长的,只要算法在运行,新的神经元就会不断增加。
- 每次迭代都从从训练集中选择一个数据点开始。由于 GNG 可以很好地推广到任意数量的维度,因此通常用 𝛿 长度向量 v 来表示它们。
- 最接近 v 的神经元,类似于 SOFM,称为最佳表现单元 (BPU),会移近 v。所有直接连接到 BPU 的神经元也会移近 v。
- 确定第二佳表现单元 (SBPU)。如果 BPU 和 SBPU 已连接,则将此连接的年龄设置为零。如果它们未连接,则将它们连接起来。然后增加从 BPU 发出的所有其他边的年龄。
- 如果边的年龄大于最大年龄 Amax,则删除该边。如果这导致“孤立神经元”(没有边连接的神经元),也会删除这些神经元。
- 每 λ 次迭代,累积误差最大的神经元(每次迭代中与每个数据向量 v 的距离之和)被确定为表现最差的单元 (WPU)。在 WPU 和其表现最差的邻居之间插入一个新神经元,并删除 WPU 和其表现最差的邻居之间的原始边。
- 迭代直到达到某些边界条件,例如最大迭代次数。
理解此算法的工作原理很简单,但值得花一些时间思考它为什么有效。你可能已经从上面的例子中注意到,此方法创建了数据分布空间的分区,并通过近似 Delaunay 三角剖分来实现。事实上,在原始论文中,Fritzke 将 GNG 生成的图称为“诱导 Delaunay 三角剖分”。
神经气体生长算法的理念是,与需要了解表示数据所需的神经元数量 SOFM 不同,GNG 确定模型迄今为止表现最差的区域,并改进该区域。这最终导致模型不能均匀增长,而是扩大图形的大小,不再能以给定的分辨率(神经元数量)覆盖(量化)数据。
2、使用 GNG 来计算聚类
在竞争性神经网络的第一部分介绍中,我已经介绍了 GNG 的一个用例,即作为快速高效的矢量量化算法,可以创建不错的图像近似值。接下来,我们将讨论一些略有不同的内容,即计算不同的对象并量化它们的大小。
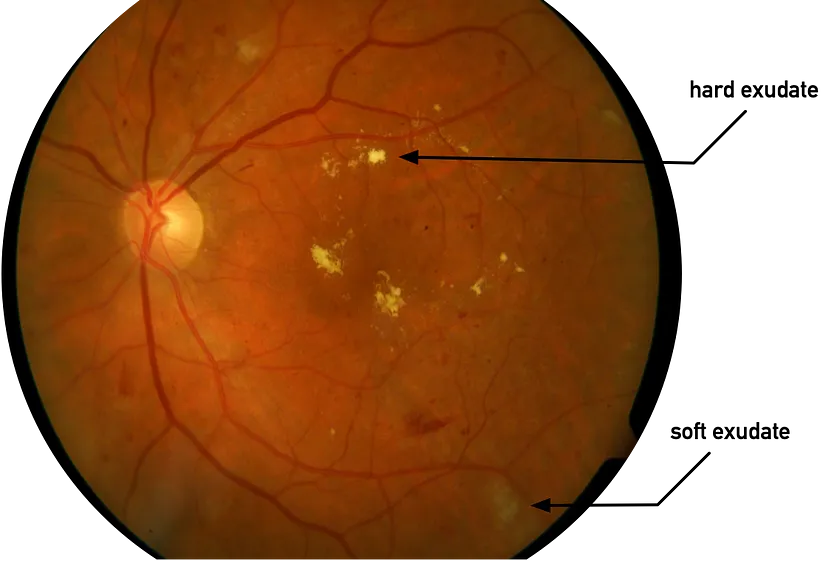
拉彭兰塔理工大学 Kauppi 等人的研究小组的 DIARETDB1 数据集包含 5 名健康志愿者和 84 名患有一定程度糖尿病视网膜病变的人的 89 张数字眼底镜检查图像,即眼底图像。糖尿病视网膜病变是糖尿病的一种并发症,会影响视网膜的小血管,长期血糖控制不足会导致血管损伤、微动脉瘤和渗出物,其中脂质(导致亮黄色硬渗出物)或血液(导致淡黄色、弥漫性软渗出物)积聚在眼底。接下来,我们将使用 GNG 来量化这些异常。DIARETDB1 数据集包含 ROI(感兴趣区域)蒙版,但这些蒙版仅勾勒出显示特定临床特征的区域。我们可以使用 Growing Neural Gas 来计算感兴趣区域中存在多少个硬渗出物簇吗?当然可以!
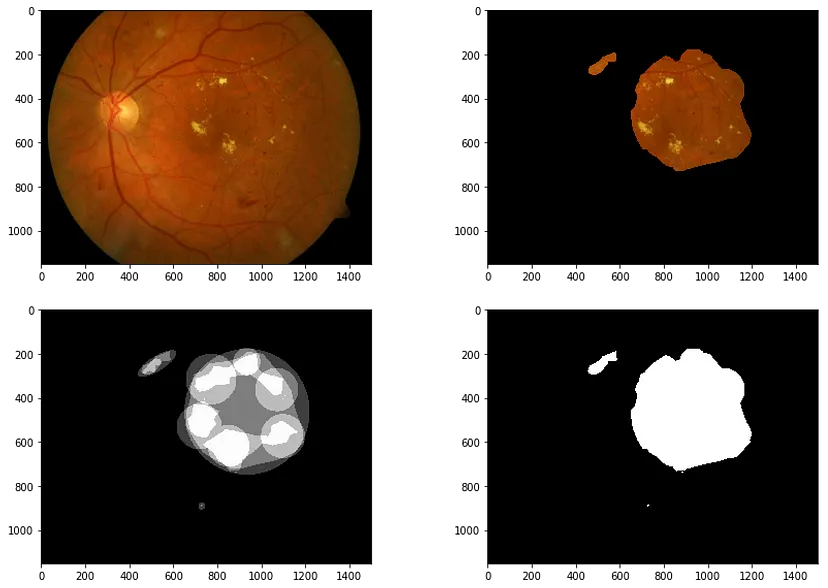
使用共识掩码隔离 ROI:根据原始 ROI 注释(左下)生成至少两位专家投票的共识掩码(右下)。此掩码用于将感兴趣的区域与眼底检查图像(左上)隔离,从而生成掩码图像(右上)。
我们从一些图像处理开始,即细化感兴趣的区域。每张图像都由四位专家标记,从而创建了一个蒙版。我们可以对蒙版进行阈值处理,以要求一定数量的专家达成共识,这是带注释的研究图像中广泛使用的技巧(如果您不熟悉它,请滚动到底部!)。然后,我们使用硬性渗出液相对突出的亮黄色将它们转换为 GNG 可以开始表征的数据点(有关细节,请参阅配套笔记本,其中解释了一些额外的技巧,包括一些形态变换)。
接下来,我们利用脂质渗出液具有非常可识别的黄色这一事实,通过使用 OpenCV 的 inRange 函数对其进行阈值处理。此时,我们上面执行的 ROI 蒙版派上了用场,因为视神经盘(血管进入的亮黄色圆形结构,神经节神经元的轴突离开视网膜加入视神经)通常具有相似的颜色,具体取决于照明。使用 inRange 时,通常将图像转换为 HSV(色调、饱和度和明度)格式,因为这样可以更轻松地指定特定色调范围内的颜色。在 HSV 中,色调(“颜色”)占据颜色向量的单个元素(通常指定为色环上的度数),因此指定所有黄色就像指定黄色的近似色调角(大约 60°)并排除低饱和度(浅色,趋向于白色)或低明度(深色,趋向于黑色)边缘一样简单。对于 RGB 中的大多数颜色,这会复杂得多!幸运的是,OpenCV 及其 Python 绑定具有出色的颜色空间转换功能。
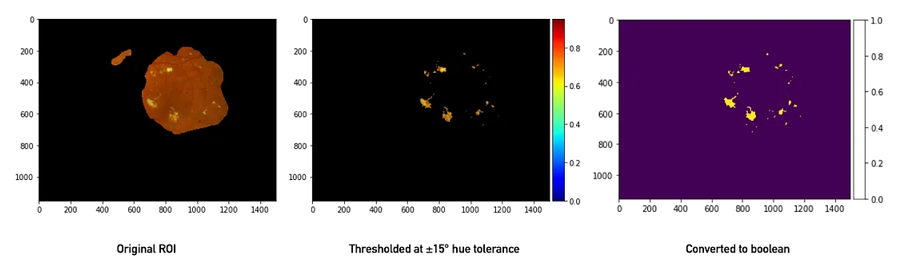
使用 OpenCV 的颜色阈值功能从原始 ROI 中提取硬脂质渗出物。只有落在特定色调角度范围内的值才会被保留。经过一些形态学操作以消除噪音后,我们留下了一个布尔图像,该图像将转换为二进制网格格式,以供 GNG 进行训练。
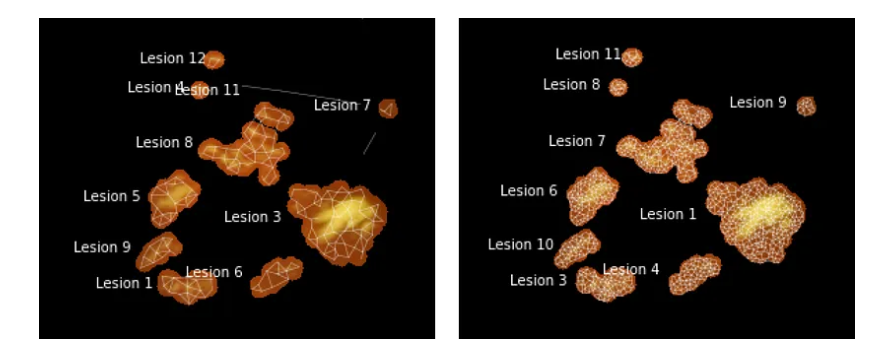
终端神经元数量越多,形状近似越准确,但运行时间也越长(左:200 个神经元,右:1,000 个神经元)。
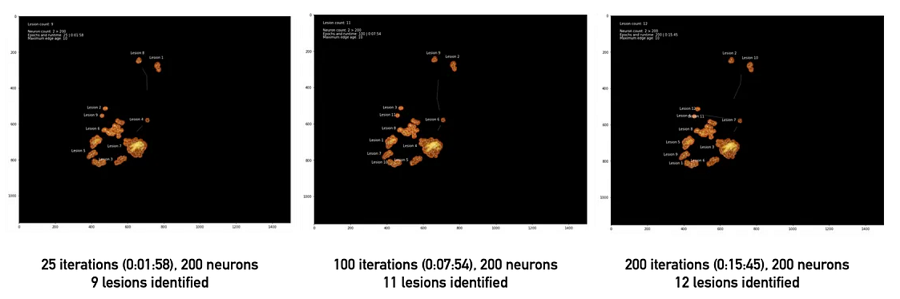
使用 GNG 计算聚类簇时,一些设置至关重要。特别是,值得从大量初始神经元开始。在第 1 部分中提到的图像矢量量化示例中,我们从两个神经元开始。这样做的结果是一个图,该图在大多数时间将保持完全连接(回想一下,对于 GNG 来说,生成新神经元比删除现有神经元要容易得多)。这是一个问题,因为我们依靠计算断开连接的子图来确定不同病变的数量。最简单的解决方案是创建大量初始神经元(几千个,即比预期的不同簇数量多 2-3 个数量级)。虽然延长了训练时间,但一段时间后确实会导致分割越来越准确——最重要的是,与初始神经元数量较少的分割不同,它们不太可能具有需要多次迭代才能分离的连接段。
3、结束语
基于生长神经气体的模型不仅擅长矢量量化,还能从所有数据点的一小部分创建可行、可理解的数据表示。它们还可以找到未知数量的连贯拓扑。如果有时间收敛,这些模型不仅可以识别不同拓扑的数量,还可以量化它们的相对和绝对面积。
竞争神经网络至今仍是一种未得到充分利用的技术,但最近的高效实现,如 Tensorflow SOFM 层和基于 Tensorflow 的 GNG 实现,有望促进竞争神经网络的复兴,无论是单独实现还是作为更大神经网络图的一部分。
原文链接:Quantifying hard retinal exudates using Growing Neural Gas algorithms
BimAnt翻译整理,转载请标明出处





