
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
大约 20年前,一家名为 Jigsaw 的初创公司开创了一种新的众包模式,用户可以向平台贡献数据,以换取对其服务的访问权。 如今,Jigsaw 基本上已被遗忘,但其所谓的Give-to-Get(付出 - 收获)模式对于需要获取丰富的专有数据集来训练模型的人工智能初创公司来说可能是完美的选择。 这些数据集对于提高人工智能模型的准确性和性能、提供相对于竞争对手的竞争优势、允许针对特定行业需求进行定制和专业化以及减少对第三方数据源的依赖至关重要。 这篇文章将讨论 Jigsaw 模型、它在人工智能中的适用性、获取专有训练数据集的挑战,以及它可以应用的垂直行业。
1、Jigsaw和Give-to-Get模式
Jigsaw Data Corporation 由 Jim Fowler 和 Garth Moulton 于 2004 年创立。 该公司的主要产品是一个大型、众包、可搜索的数据库,其中包含各个行业的数百万个业务联系人。 在每个人都拥有 LinkedIn 个人资料之前的日子里,这对于寻找潜在客户的销售人员来说尤其有价值。
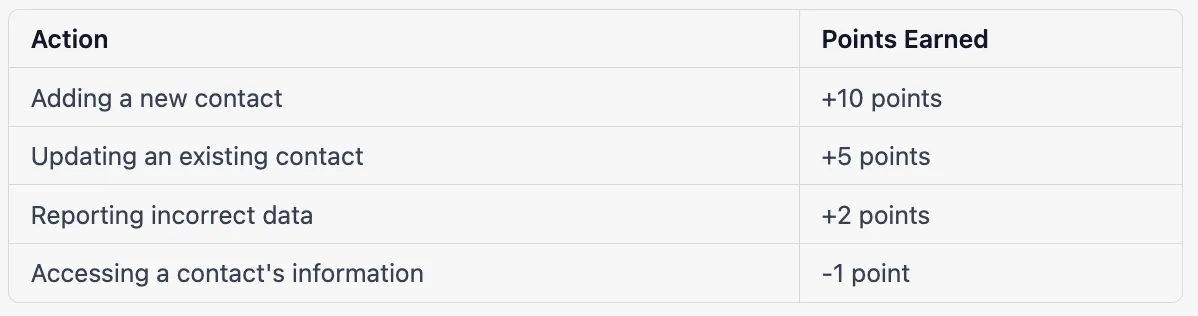
Jigsaw 的众包模式围绕积分系统展开。 用户可以通过贡献自己的业务联系信息在 Jigsaw 平台上创建免费帐户。 他们还可以将新联系人添加到数据库中以赚取积分,然后可以用积分查看其他人发布的联系人。 不想贡献自己数据的用户可以购买积分。 Jigsaw 还鼓励用户验证数据库中联系信息的准确性,每次更正都会奖励积分。
2010年,Salesforce.com以1.42亿美元收购了Jigsaw,将其更名为“Data.com”,并将其与Salesforce.com生态系统整合。 这使得用户可以直接在其 CRM 系统中访问更新的业务联系信息。
2、AI的“Give-to-Get模型
对于AI初创公司来说,Give-to-Get模式可能是一种有效的方法,在这种模式中,用户通过贡献数据来赚取积分,并花费积分来访问基于该数据的服务。 在许多垂直行业中,获取丰富的专有数据集将是生成差异化AI模型的关键挑战。 通过激励该行业的专业人士共享必要的数据,人工智能初创公司可以快速训练和改进他们的模型来为这些专业人士服务。
例如,“AI 建筑师”初创公司可以为贡献建筑计划和 CAD 图纸的用户提供积分。 然后,用户可以通过要求人工智能设计新计划来花费积分。 这种方法可以用于各种行业,这些行业的用户拥有专有数据,并且愿意贡献一些数据以换取利用人工智能功能。
激励用户众包可能是获取大量数据的一种经济有效的方式,因为它利用社区的努力而不是依赖付费数据收集服务。 随着用户贡献更多数据并使用人工智能服务,模型可以迭代改进,从而获得更好的性能和更有价值的见解。
将会有一些重要的问题需要解决。 确保所提供数据的质量和准确性至关重要。 初创公司可能需要实施验证流程,例如同行评审或专家验证,以保持数据质量。 处理专有数据还需要解决隐私和知识产权问题。 初创公司可能需要确保某些数据仅用于培训目的,并在如何使用贡献的数据方面保持透明。 遵守行业特定法规也至关重要。
最后,货币化的需要必须与基于积分的系统相平衡;否则,用户可能更愿意通过贡献数据而不是付费服务来永久免费使用该平台。 积分可以受到限制,以便用户获得折扣或获得更多查询,而不是完全免费获得服务。
3、不同行业的机会
Give-to-Get模式的众包数据收集方法可以应用于目标用户拥有培训数据的许多垂直行业。 以下是此方法有用的一些示例:
- 医疗和健康数据:AI模型可以从访问不同的患者数据中受益匪浅,例如电子健康记录、医学成像和基因组数据。 用户(患者或医疗保健专业人员)可能愿意分享匿名数据以换取积分,然后可以使用积分来获取人工智能驱动的健康见解、个性化治疗建议或早期疾病检测。
- 法律文件分析:律师事务所和法律专业人士通常可以访问大量法律文件,例如合同、法院裁决或专利申请。 通过共享这些文档,用户可以为训练用于法律文档分析的AI模型做出贡献,作为回报,可以获得AI驱动的法律研究工具或合同审查服务。
- 艺术和创意作品:艺术家和设计师可能拥有大量自己的艺术品、草图或设计收藏。 共享这些数据可以帮助训练AI模型以进行艺术风格转移、生成艺术或设计辅助。 然后,用户可以访问AI驱动的创意工具或个性化设计建议。
- 金融和投资:金融专业人士和投资者可以访问专有的交易算法、投资组合数据或市场分析报告。 通过共享这些数据,他们可以为用于财务分析和预测的AI模型做出贡献。 作为回报,用户可以获得AI驱动的投资建议、风险评估或市场预测工具。
- 科学研究数据:各个领域的研究人员可能可以获得通过实验或模拟生成的有价值的数据集。 通过共享这些数据,他们可以帮助训练AI模型,以在各自领域进行数据分析、模式识别或预测建模。 然后,用户可以访问AI驱动的研究工具或个性化的研究建议。
- 制造和生产数据:参与制造和生产的公司可能拥有有关生产流程、质量控制和设备性能的专有数据。 共享这些数据可以改进用于预测性维护、流程优化和质量保证的AI模型。 然后,用户可以获得AI驱动的优化建议或设备监控服务。

4、结束语
对于希望为垂直行业创建AI模型的初创公司来说,获得丰富的专有训练数据集将是关键挑战。 从这些行业工作的专业人士那里众包这些数据可能是解决这个问题的一个很好的方法。 此外,众包应该创建一个飞轮:当用户向模型贡献数据时,模型会变得更加智能、能力更强,从而吸引下一组用户,而这些用户又会提供下一组数据。 这种数据网络效应应该在业务周围形成强大的护城河。 也就是说,初创公司必须主动解决与Give-to-Get模型相关的潜在风险或缺点,例如数据质量、隐私和知识产权问题,以确保其AI模型的长期成功。
原文链接:The Give-to-Get Model for AI Startups
BimAnt翻译整理,转载请标明出处





