
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
图神经网络 (GNN) 是深度学习领域最吸引人且发展最快的架构之一。作为旨在处理图结构数据的深度学习模型,GNN 具有非凡的多功能性和强大的学习能力。
在各种类型的 GNN 中,图卷积网络 (GCN) 已成为最流行且应用最广泛的模型。GCN 具有创新性,因为它们能够利用节点的特征及其局部性进行预测,从而提供一种处理图结构数据的有效方法。
在本文中,我们将深入研究 GCN 层的机制并解释其内部工作原理。此外,我们将使用 PyTorch Geometric 作为我们的首选工具,探索其在节点分类任务中的实际应用。
PyTorch Geometric 是 PyTorch 的专用扩展,专为开发和实施 GNN 而创建。它是一个先进但用户友好的库,提供了一套全面的工具来促进基于图的机器学习。要开始我们的旅程,需要安装 PyTorch Geometric。如果你使用的是 Google Colab,PyTorch 应该已经安装完毕,所以我们需要做的就是执行一些额外的命令。
所有代码都可以在 Google Colab 和 GitHub 上找到。
!pip install torch_geometric
import torch
import numpy as np
import networkx as nx
import matplotlib.pyplot as plt现在 PyTorch Geometric 已安装完毕,让我们来探索本教程中将使用的数据集。
1、图数据
图(graph)是表示对象之间关系的基本结构。您可以在众多现实场景中遇到图形数据,例如社交和计算机网络、分子的化学结构、自然语言处理和图像识别等等。
在本文中,我们将研究使用广泛的 Zachary 空手道俱乐部数据集。
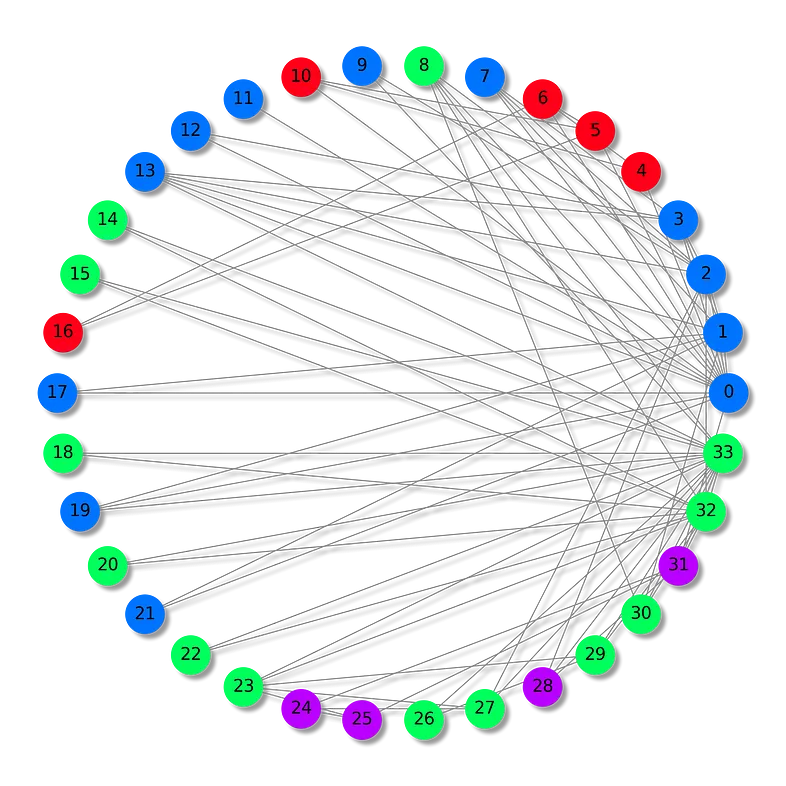
Zachary 的空手道俱乐部数据集体现了 Wayne W. Zachary 在 20 世纪 70 年代观察到的空手道俱乐部内部形成的关系。它是一种社交网络,每个节点代表一名俱乐部成员,节点之间的边代表俱乐部环境之外发生的互动。
在这个特定场景中,俱乐部的成员被分成四个不同的组。我们的任务是根据他们互动的模式为每个成员分配正确的组(节点分类)。
让我们使用 PyG 的内置函数导入数据集,并尝试了解它使用的 Datasets 对象。
from torch_geometric.datasets import KarateClub
# Import dataset from PyTorch Geometric
dataset = KarateClub()
# Print information
print(dataset)
print('------------')
print(f'Number of graphs: {len(dataset)}')
print(f'Number of features: {dataset.num_features}')
print(f'Number of classes: {dataset.num_classes}')输出如下:
KarateClub()
------------
Number of graphs: 1
Number of features: 34
Number of classes: 4该数据集只有 1 个图,其中每个节点都有一个 34 维的特征向量,并且属于四个类(我们的四个组)中的一个。实际上,数据集对象可以看作是数据(图)对象的集合。
我们可以进一步检查我们独特的图以了解更多信息。
# Print first element
print(f'Graph: {dataset[0]}')
Graph: Data(x=[34, 34], edge_index=[2, 156], y=[34], train_mask=[34])Data 对象特别有趣。打印它可以很好地概括我们正在研究的图表:
- x=[34, 34] 是具有形状(节点数、特征数)的节点特征矩阵。在我们的例子中,这意味着我们有 34 个节点(我们的 34 个成员),每个节点都与一个 34 维特征向量相关联。
- edge_index=[2, 156] 表示具有形状(2,有向边数)的图表连通性(节点的连接方式)。
- y=[34] 是节点的真实标签。在此问题中,每个节点都分配给一个类(组),因此每个节点都有一个值。
- train_mask=[34] 是一个可选属性,它使用 True 或 False 语句列表来指示哪些节点应该用于训练。
让我们打印每个张量以了解它们存储的内容。让我们从节点特征开始。
data = dataset[0]
print(f'x = {data.x.shape}')
print(data.x)
x = torch.Size([34, 34])
tensor([[1., 0., 0., ..., 0., 0., 0.],
[0., 1., 0., ..., 0., 0., 0.],
[0., 0., 1., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 1., 0., 0.],
[0., 0., 0., ..., 0., 1., 0.],
[0., 0., 0., ..., 0., 0., 1.]])这里,节点特征矩阵 x 是一个单位矩阵:它不包含任何与节点相关的信息。它可能包含年龄、技能水平等信息,但此数据集中并非如此。这意味着我们必须通过查看节点的连接来对节点进行分类。
现在,让我们打印边索引。
print(f'edge_index = {data.edge_index.shape}')
print(data.edge_index)
edge_index = torch.Size([2, 156])
tensor([[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1,
1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3,
3, 3, 3, 3, 3, 4, 4, 4, 5, 5, 5, 5, 6, 6, 6, 6, 7, 7,
7, 7, 8, 8, 8, 8, 8, 9, 9, 10, 10, 10, 11, 12, 12, 13, 13, 13,
13, 13, 14, 14, 15, 15, 16, 16, 17, 17, 18, 18, 19, 19, 19, 20, 20, 21,
21, 22, 22, 23, 23, 23, 23, 23, 24, 24, 24, 25, 25, 25, 26, 26, 27, 27,
27, 27, 28, 28, 28, 29, 29, 29, 29, 30, 30, 30, 30, 31, 31, 31, 31, 31,
31, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 33, 33, 33, 33, 33,
33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33],
[ 1, 2, 3, 4, 5, 6, 7, 8, 10, 11, 12, 13, 17, 19, 21, 31, 0, 2,
3, 7, 13, 17, 19, 21, 30, 0, 1, 3, 7, 8, 9, 13, 27, 28, 32, 0,
1, 2, 7, 12, 13, 0, 6, 10, 0, 6, 10, 16, 0, 4, 5, 16, 0, 1,
2, 3, 0, 2, 30, 32, 33, 2, 33, 0, 4, 5, 0, 0, 3, 0, 1, 2,
3, 33, 32, 33, 32, 33, 5, 6, 0, 1, 32, 33, 0, 1, 33, 32, 33, 0,
1, 32, 33, 25, 27, 29, 32, 33, 25, 27, 31, 23, 24, 31, 29, 33, 2, 23,
24, 33, 2, 31, 33, 23, 26, 32, 33, 1, 8, 32, 33, 0, 24, 25, 28, 32,
33, 2, 8, 14, 15, 18, 20, 22, 23, 29, 30, 31, 33, 8, 9, 13, 14, 15,
18, 19, 20, 22, 23, 26, 27, 28, 29, 30, 31, 32]])在图论和网络分析中,节点之间的连接使用各种数据结构来存储。edge_index 就是这样一种数据结构,其中图的连接存储在两个列表中(156 条有向边,相当于 78 条双向边)。这两个列表的原因在于,一个列表存储源节点,而另一个列表标识目标节点。
这种方法称为坐标列表 (COO) 格式,本质上是一种有效存储稀疏矩阵的方法。稀疏矩阵是一种数据结构,可以有效存储大多数为零元素的矩阵。在 COO 格式中,只存储非零元素,从而节省内存和计算资源。
相反,表示图连接的一种更直观、更直接的方法是通过邻接矩阵 A。这是一个方阵,其中每个元素 Aᵢⱼ 指定图中从节点 i 到节点 j 的边的存在与否。换句话说,非零元素 Aᵢⱼ 表示从节点 i 到节点 j 的连接,而零表示没有直接连接。
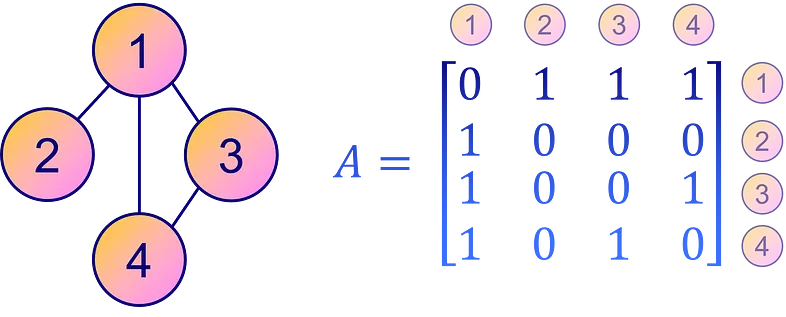
然而,对于稀疏矩阵或边较少的图,邻接矩阵的空间效率不如 COO 格式。不过,为了清晰易懂,邻接矩阵仍然是表示图连通性的流行选择。
可以使用实用函数 to_dense_adj() 从 edge_index 推断出邻接矩阵。
from torch_geometric.utils import to_dense_adj
A = to_dense_adj(data.edge_index)[0].numpy().astype(int)
print(f'A = {A.shape}')
print(A)输出如下:
A = (34, 34)
[[0 1 1 ... 1 0 0]
[1 0 1 ... 0 0 0]
[1 1 0 ... 0 1 0]
...
[1 0 0 ... 0 1 1]
[0 0 1 ... 1 0 1]
[0 0 0 ... 1 1 0]]对于图数据,节点密集连接的情况相对少见。如你所见,我们的邻接矩阵 A 是稀疏的(填充了零)。
在许多现实世界的图中,大多数节点仅连接到少数其他节点,导致邻接矩阵中存在大量零。存储这么多零一点也不高效,这就是 PyG 采用 COO 格式的原因。
相反,真实标签很容易理解。
print(f'y = {data.y.shape}')
print(data.y)
y = torch.Size([34])输出如下:
tensor([1, 1, 1, 1, 3, 3, 3, 1, 0, 1, 3, 1, 1, 1, 0, 0, 3, 1, 0, 1, 0, 1, 0, 0,
2, 2, 0, 0, 2, 0, 0, 2, 0, 0])存储在 y 中的节点真实标签只是对每个节点的组号 (0、1、2、3) 进行编码,这就是我们有 34 个值的原因。
最后,让我们打印训练掩码。
print(f'train_mask = {data.train_mask.shape}')
print(data.train_mask)
train_mask = torch.Size([34])输出如下:
tensor([ True, False, False, False, True, False, False, False, True, False,
False, False, False, False, False, False, False, False, False, False,
False, False, False, False, True, False, False, False, False, False,
False, False, False, False])训练掩码显示哪些节点应该用于训练,并带有 True 语句。这些节点代表训练集,而其他节点可以视为测试集。这种划分有助于模型评估,因为它提供了未见过的测试数据。
但我们还没有完成!Data 对象还有很多东西可以提供。它提供了各种实用函数,可以调查图的几个属性。例如:
is_directed()告诉你图是否有向。有向图表示邻接矩阵不对称,即边的方向对节点之间的连接很重要。isolated_nodes()检查某些节点是否未连接到图的其余部分。由于缺乏连接,这些节点可能会在分类等任务中带来挑战。has_self_loops()表示至少有一个节点是否连接到自身。这与循环的概念不同:循环意味着从同一节点开始和结束的路径,遍历其间的其他节点。
在 Zachary 的空手道俱乐部数据集的上下文中,所有这些属性都返回 False。这意味着该图不是有向的,没有任何孤立节点,并且其节点都不与自身相连。
print(f'Edges are directed: {data.is_directed()}')
print(f'Graph has isolated nodes: {data.has_isolated_nodes()}')
print(f'Graph has loops: {data.has_self_loops()}')输出如下:
Edges are directed: False
Graph has isolated nodes: False
Graph has loops: False最后,我们可以使用 to_networkx 将 PyTorch Geometric 中的图形转换为流行的图库 NetworkX。这对于使用 networkx 和 matplotlib 可视化小图形特别有用。
让我们用不同的颜色为每个组绘制数据集。
from torch_geometric.utils import to_networkx
G = to_networkx(data, to_undirected=True)
plt.figure(figsize=(12,12))
plt.axis('off')
nx.draw_networkx(G,
pos=nx.spring_layout(G, seed=0),
with_labels=True,
node_size=800,
node_color=data.y,
cmap="hsv",
vmin=-2,
vmax=3,
width=0.8,
edge_color="grey",
font_size=14
)
plt.show()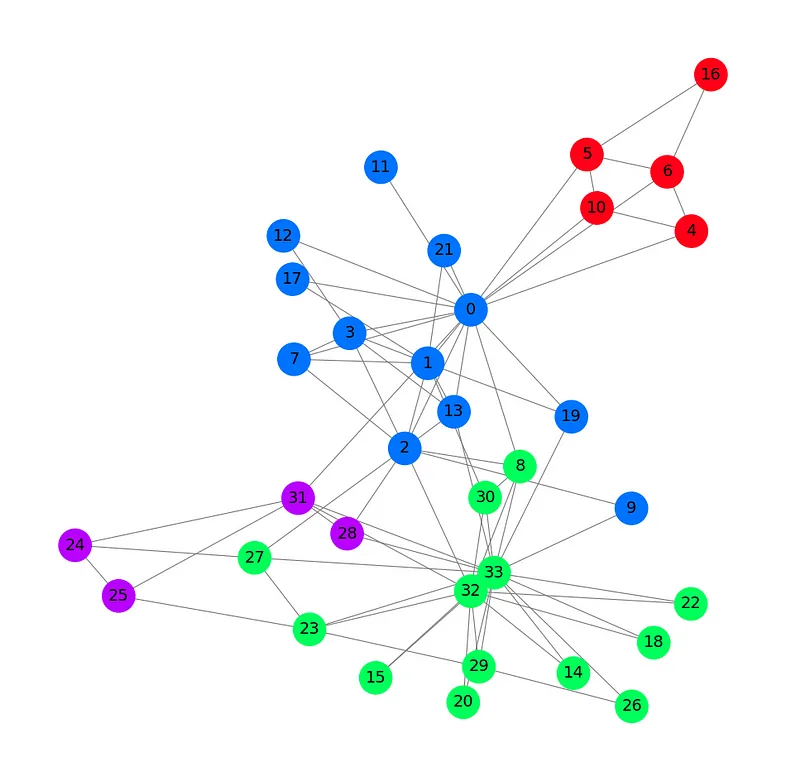
Zachary 空手道俱乐部的这个图展示了我们的 34 个节点、78 条(双向)边和 4 个带有 4 种不同颜色的标签。现在我们已经了解了使用 PyTorch Geometric 加载和处理数据集的基本知识,我们可以介绍图卷积网络架构了。
2、 图卷积网络
本节旨在从头开始介绍和构建图卷积层。
在传统神经网络中,线性层对传入数据应用线性变换。此变换通过使用权重矩阵 𝐖 将输入特征 x 转换为隐藏向量 h。暂时忽略偏差,这可以表示为:

对于图形数据,通过节点之间的连接增加了一层复杂性。这些连接很重要,因为在网络中,通常假设相似的节点比不相似的节点更有可能相互链接,这种现象称为网络同质性(network homophily)。
我们可以通过将节点的特征与其邻居的特征合并来丰富我们的节点表示。此操作称为卷积(convolution)或邻域聚合(neighborhood aggregation)。让我们将节点 i 的邻域(包括自身)表示为 Ñ。
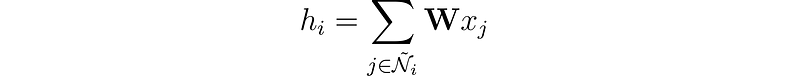
与卷积神经网络 (CNN) 中的过滤器不同,我们的权重矩阵 𝐖 是唯一的,并且在每个节点之间共享。但还有另一个问题:节点没有像像素那样固定数量的邻居。
我们如何处理一个节点只有一个邻居,而另一个节点有 500 个邻居的情况?如果我们简单地将特征向量相加,那么对于有 500 个邻居的节点,得到的嵌入 h 会大得多。为了确保所有节点的值范围相似且它们之间具有可比性,我们可以根据节点的度对结果进行归一化,其中度是指节点具有的连接数。
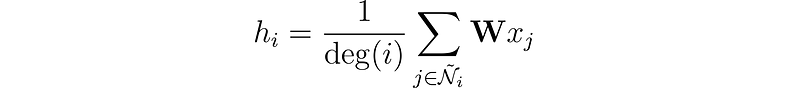
我们快到了!由 Kipf 等人 (2016) 引入的图卷积层还有最后一个改进。
作者观察到,来自具有众多邻居的节点的特征比来自更孤立节点的特征传播得更容易。为了抵消这种影响,他们建议为来自邻居较少的节点的特征分配更大的权重,从而平衡所有节点的影响。此操作写为:
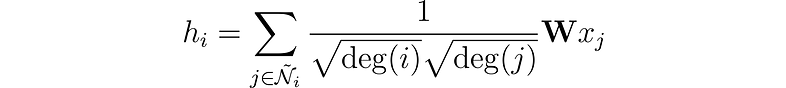
请注意,当 i 和 j 具有相同数量的邻居时,它相当于我们自己的层。现在,让我们看看如何使用 PyTorch Geometric 在 Python 中实现它。
3、实现 GCN
PyTorch Geometric 提供了 GCNConv 函数,它直接实现了图卷积层。
在此示例中,我们将创建一个基本的图卷积网络,其中包含单个 GCN 层、ReLU 激活函数和线性输出层。这个输出层将产生四个对应于我们四个类别的值,其中最高值确定每个节点的类别。
在下面的代码块中,我们用一个三维隐藏层定义 GCN 层:
from torch.nn import Linear
from torch_geometric.nn import GCNConv
class GCN(torch.nn.Module):
def __init__(self):
super().__init__()
self.gcn = GCNConv(dataset.num_features, 3)
self.out = Linear(3, dataset.num_classes)
def forward(self, x, edge_index):
h = self.gcn(x, edge_index).relu()
z = self.out(h)
return h, z
model = GCN()
print(model)输出如下:
GCN(
(gcn): GCNConv(34, 3)
(out): Linear(in_features=3, out_features=4, bias=True)
)如果我们添加第二个 GCN 层,我们的模型不仅会聚合来自每个节点的邻居的特征向量,还会聚合来自这些邻居的邻居的特征向量。
我们可以堆叠多个图层来聚合更多更远的值,但有一个问题:如果我们添加太多层,聚合会变得非常激烈,以至于所有嵌入最终看起来都一样。这种现象称为过度平滑,当层数过多时可能会成为一个真正的问题。
现在我们已经定义了 GNN,让我们用 PyTorch 编写一个简单的训练循环。我选择了常规的交叉熵损失,因为它是一个多类分类任务,使用 Adam 作为优化器。在本文中,我们不会实现训练/测试拆分以保持简单,而是专注于 GNN 如何学习。
训练循环是标准的:我们尝试预测正确的标签,并将 GCN 的结果与存储在 data.y 中的值进行比较。误差由交叉熵损失计算得出,并通过 Adam 反向传播以微调我们的 GNN 的权重和偏差。最后,我们每 10 个时期打印一次指标。
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.02)
# Calculate accuracy
def accuracy(pred_y, y):
return (pred_y == y).sum() / len(y)
# Data for animations
embeddings = []
losses = []
accuracies = []
outputs = []
# Training loop
for epoch in range(201):
# Clear gradients
optimizer.zero_grad()
# Forward pass
h, z = model(data.x, data.edge_index)
# Calculate loss function
loss = criterion(z, data.y)
# Calculate accuracy
acc = accuracy(z.argmax(dim=1), data.y)
# Compute gradients
loss.backward()
# Tune parameters
optimizer.step()
# Store data for animations
embeddings.append(h)
losses.append(loss)
accuracies.append(acc)
outputs.append(z.argmax(dim=1))
# Print metrics every 10 epochs
if epoch % 10 == 0:
print(f'Epoch {epoch:>3} | Loss: {loss:.2f} | Acc: {acc*100:.2f}%')输出如下:
Epoch 0 | Loss: 1.40 | Acc: 41.18%
Epoch 10 | Loss: 1.21 | Acc: 47.06%
Epoch 20 | Loss: 1.02 | Acc: 67.65%
Epoch 30 | Loss: 0.80 | Acc: 73.53%
Epoch 40 | Loss: 0.59 | Acc: 73.53%
Epoch 50 | Loss: 0.39 | Acc: 94.12%
Epoch 60 | Loss: 0.23 | Acc: 97.06%
Epoch 70 | Loss: 0.13 | Acc: 100.00%
Epoch 80 | Loss: 0.07 | Acc: 100.00%
Epoch 90 | Loss: 0.05 | Acc: 100.00%
Epoch 100 | Loss: 0.03 | Acc: 100.00%
Epoch 110 | Loss: 0.02 | Acc: 100.00%
Epoch 120 | Loss: 0.02 | Acc: 100.00%
Epoch 130 | Loss: 0.02 | Acc: 100.00%
Epoch 140 | Loss: 0.01 | Acc: 100.00%
Epoch 150 | Loss: 0.01 | Acc: 100.00%
Epoch 160 | Loss: 0.01 | Acc: 100.00%
Epoch 170 | Loss: 0.01 | Acc: 100.00%
Epoch 180 | Loss: 0.01 | Acc: 100.00%
Epoch 190 | Loss: 0.01 | Acc: 100.00%
Epoch 200 | Loss: 0.01 | Acc: 100.00%太棒了!不出所料,我们在训练集(完整数据集)上的准确率达到了 100%。这意味着我们的模型学会了正确地将空手道俱乐部的每个成员分配到正确的组中。
我们可以通过动画图表来制作一个简洁的可视化效果,并查看 GNN 在训练过程中的预测演变。
%%capture
from IPython.display import HTML
from matplotlib import animation
plt.rcParams["animation.bitrate"] = 3000
def animate(i):
G = to_networkx(data, to_undirected=True)
nx.draw_networkx(G,
pos=nx.spring_layout(G, seed=0),
with_labels=True,
node_size=800,
node_color=outputs[i],
cmap="hsv",
vmin=-2,
vmax=3,
width=0.8,
edge_color="grey",
font_size=14
)
plt.title(f'Epoch {i} | Loss: {losses[i]:.2f} | Acc: {accuracies[i]*100:.2f}%',
fontsize=18, pad=20)
fig = plt.figure(figsize=(12, 12))
plt.axis('off')
anim = animation.FuncAnimation(fig, animate, \
np.arange(0, 200, 10), interval=500, repeat=True)
html = HTML(anim.to_html5_video())
display(html)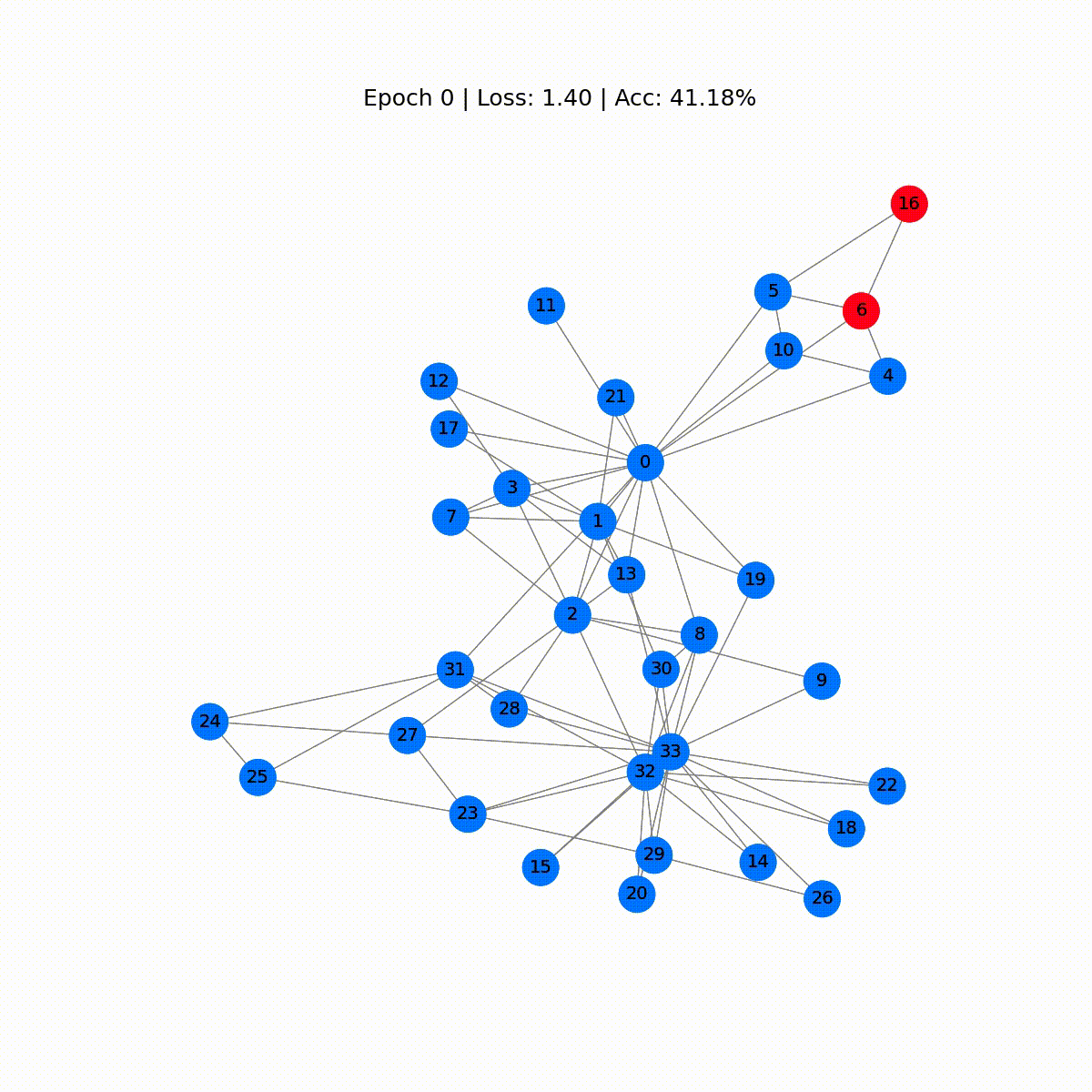
最初的预测是随机的,但一段时间后,GCN 完美地标记了每个节点。事实上,最终的图表与我们在第一部分末尾绘制的图表相同。但 GCN 真正学到了什么?
通过聚合来自相邻节点的特征,GNN 学习网络中每个节点的向量表示(或嵌入)。在我们的模型中,最后一层只是学习如何使用这些表示来产生最佳分类。然而,嵌入是 GNN 的真正产物。
让我们打印模型学习到的嵌入。
# Print embeddings
print(f'Final embeddings = {h.shape}')
print(h)输出如下:
Final embeddings = torch.Size([34, 3])
tensor([[1.9099e+00, 2.3584e+00, 7.4027e-01],
[2.6203e+00, 2.7997e+00, 0.0000e+00],
[2.2567e+00, 2.2962e+00, 6.4663e-01],
[2.0802e+00, 2.8785e+00, 0.0000e+00],
[0.0000e+00, 0.0000e+00, 2.9694e+00],
[0.0000e+00, 0.0000e+00, 3.3817e+00],
[0.0000e+00, 1.5008e-04, 3.4246e+00],
[1.7593e+00, 2.4292e+00, 2.4551e-01],
[1.9757e+00, 6.1032e-01, 1.8986e+00],
[1.7770e+00, 1.9950e+00, 6.7018e-01],
[0.0000e+00, 1.1683e-04, 2.9738e+00],
[1.8988e+00, 2.0512e+00, 2.6225e-01],
[1.7081e+00, 2.3618e+00, 1.9609e-01],
[1.8303e+00, 2.1591e+00, 3.5906e-01],
[2.0755e+00, 2.7468e-01, 1.9804e+00],
[1.9676e+00, 3.7185e-01, 2.0011e+00],
[0.0000e+00, 0.0000e+00, 3.4787e+00],
[1.6945e+00, 2.0350e+00, 1.9789e-01],
[1.9808e+00, 3.2633e-01, 2.1349e+00],
[1.7846e+00, 1.9585e+00, 4.8021e-01],
[2.0420e+00, 2.7512e-01, 1.9810e+00],
[1.7665e+00, 2.1357e+00, 4.0325e-01],
[1.9870e+00, 3.3886e-01, 2.0421e+00],
[2.0614e+00, 5.1042e-01, 2.4872e+00],
...
[2.1778e+00, 4.4730e-01, 2.0077e+00],
[3.8906e-02, 2.3443e+00, 1.9195e+00],
[3.0748e+00, 0.0000e+00, 3.0789e+00],
[3.4316e+00, 1.9716e-01, 2.5231e+00]], grad_fn=<ReluBackward0>)如你所见,嵌入不需要具有与特征向量相同的维度。在这里,我选择将维度数 dataset.num_features从 34减少到 3,以获得良好的 3D 可视化效果。
让我们在进行任何训练之前(即第 0 个时期)绘制这些嵌入。
# Get first embedding at epoch = 0
embed = h.detach().cpu().numpy()
fig = plt.figure(figsize=(12, 12))
ax = fig.add_subplot(projection='3d')
ax.patch.set_alpha(0)
plt.tick_params(left=False,
bottom=False,
labelleft=False,
labelbottom=False)
ax.scatter(embed[:, 0], embed[:, 1], embed[:, 2],
s=200, c=data.y, cmap="hsv", vmin=-2, vmax=3)
plt.show()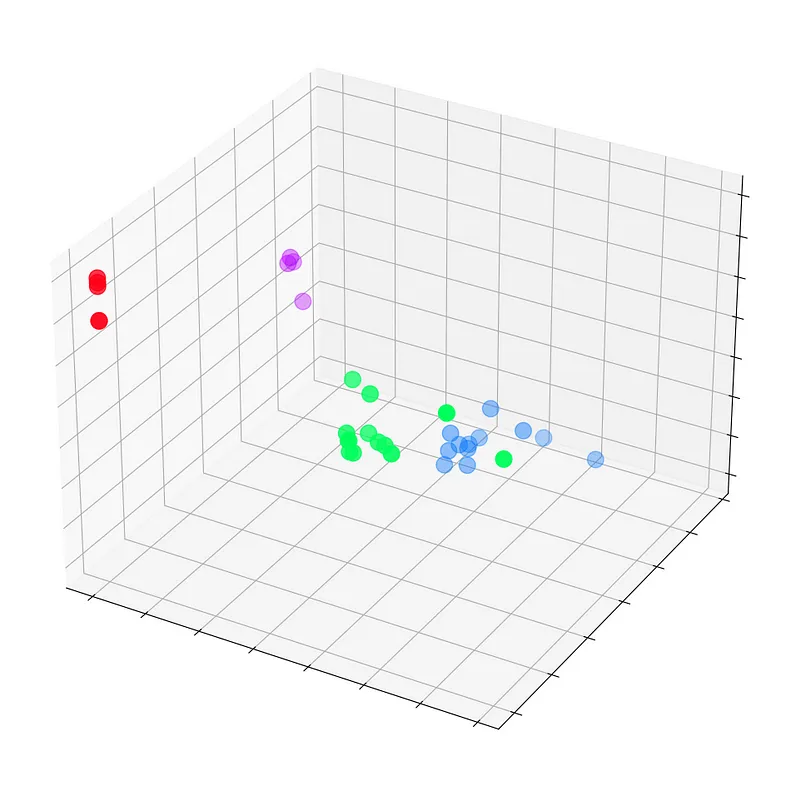
我们可以看到 Zachary 空手道俱乐部的每个节点都有其真实标签(而不是模型的预测)。目前,由于 GNN 尚未训练,因此它们到处都是。但如果我们在训练循环的每个步骤中绘制这些嵌入,我们将能够直观地看到 GNN 真正学到了什么。
随着 GCN 在对节点进行分类方面越来越好,让我们看看它们如何随着时间的推移而演变。
%%capture
def animate(i):
embed = embeddings[i].detach().cpu().numpy()
ax.clear()
ax.scatter(embed[:, 0], embed[:, 1], embed[:, 2],
s=200, c=data.y, cmap="hsv", vmin=-2, vmax=3)
plt.title(f'Epoch {i} | Loss: {losses[i]:.2f} | Acc: {accuracies[i]*100:.2f}%',
fontsize=18, pad=40)
fig = plt.figure(figsize=(12, 12))
plt.axis('off')
ax = fig.add_subplot(projection='3d')
plt.tick_params(left=False,
bottom=False,
labelleft=False,
labelbottom=False)
anim = animation.FuncAnimation(fig, animate, \
np.arange(0, 200, 10), interval=800, repeat=True)
html = HTML(anim.to_html5_video())
display(html)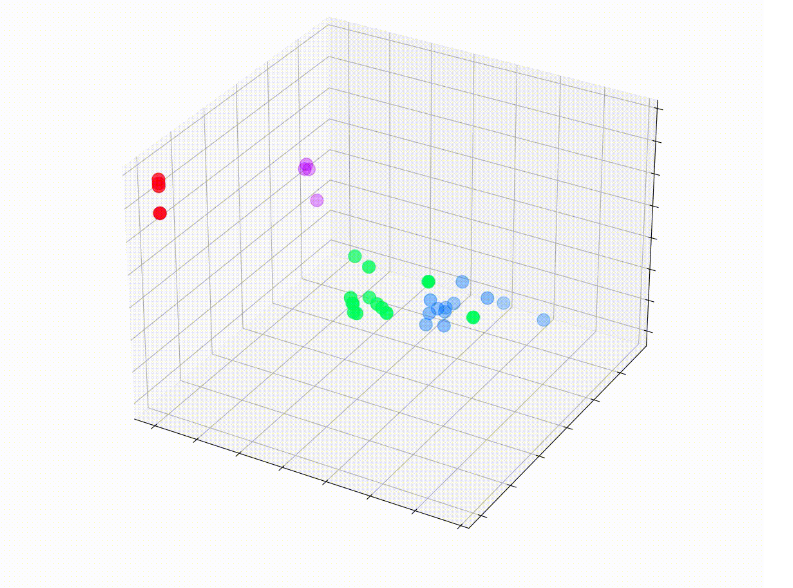
我们的图卷积网络 (GCN) 已经有效地学习了将相似节点分组到不同簇中的嵌入。这使得最终的线性层能够轻松地将它们区分为不同的类。
嵌入并非 GNN 所独有:它们在深度学习中随处可见。它们也不必是 3D 的:实际上,它们很少是 3D 的。例如,像 BERT 这样的语言模型会生成 768 甚至 1024 维的嵌入。
额外的维度存储了更多关于节点、文本、图像等的信息,但它们也会创建更大的模型,更难训练。这就是为什么尽可能长时间保持低维嵌入是有利的。
4、结束语
图卷积网络是一种用途极为广泛的架构,可应用于许多环境。在本文中,我们熟悉了 PyTorch Geometric 库和 Datasets 和 Data 等对象。然后,我们从头开始成功地重建了一个图卷积层。接下来,我们通过实现 GCN 将理论付诸实践,这让我们了解了实际方面以及各个组件如何相互作用。最后,我们将训练过程可视化,并清楚地了解了这种网络涉及的内容。
Zachary 的空手道俱乐部是一个过于简单的数据集,但它足以理解图形数据和 GNN 中最重要的概念。虽然我们在本文中只讨论了节点分类,但 GNN 还可以完成其他任务:链接预测(例如,推荐朋友)、图形分类(例如,标记分子)、图形生成(例如,创建新分子)等等。
除了 GCN,研究人员还提出了许多 GNN 层和架构。在下一篇文章中,我们将介绍图形注意网络 (GAT) 架构,它使用注意机制动态计算 GCN 的归一化因子和每个连接的重要性。
原文链接:Graph Convolutional Networks: Introduction to GNNs
BimAnt翻译整理,转载请标明出处





