
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
当像 ChatGPT 这样的人工智能软件写作时,它会考虑每个单词的许多选项,同时考虑到它迄今为止所写的回复和被问到的问题。ChatGPT 建立在所谓的大型语言模型之上,然后选择一个得分高的词,然后继续下一个词。
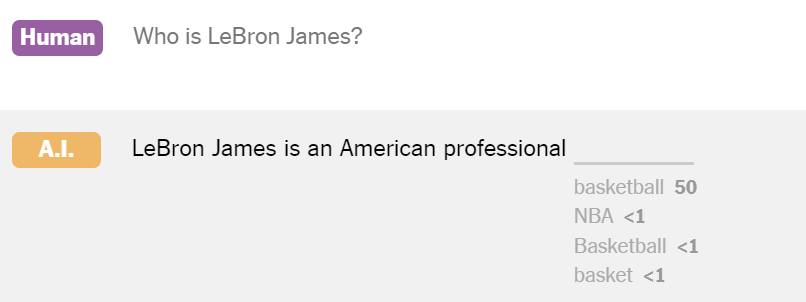
该模型的输出通常非常复杂,以至于聊天机器人看起来好像听懂了它在说什么——但事实并非如此。它做出的每一个选择都是由复杂的数学和大量数据决定的。 如此之多以至于它经常产生既连贯又准确的文本。
但是当 ChatGPT 说出不真实的话时,它本质上并没有意识到这一点。

判断推文、文章或新闻文章是否是由人工智能软件编写的,这可能很快就会变得很普遍。 可能会对给定作品的作者身份提出质疑,例如在学术环境中,或者质疑文章的真实性。 如果一个误导性的想法突然出现在互联网上的帖子中,它是自然传播的,还是这些帖子是由人工智能生成的?
用于识别一段文本是否由 A.I. 编写的工具 最近几个月开始出现,其中包括由 ChatGPT 背后的公司 OpenAI 创建的工具。 该工具可以发现AI生成的文本和人工编写的文本之间的差异。 该公司当时表示,它已经发布了实验检测器,“以获取关于像这样不完善的工具是否有用的反馈。”
专家表示,随着像 ChatGPT 这样的软件不断进步,生成的文本越来越像人类,识别生成的文本变得越来越困难。 OpenAI 现在正在试验一种技术,可以将特殊词插入到 ChatGPT 生成的文本中,以便以后更容易检测到。 该技术被称为加水印。
OpenAI 正在探索的水印方法类似于马里兰大学研究人员最近在一篇论文中描述的方法,OpenAI 负责人 Jan Leike 说。 下面是它的工作原理。
想象一下你知道的每个单词的列表,以及你在撰写论文、电子邮件或短信时可能使用的每个独特单词。现在假设这些单词中有一半属于一个特殊的列表(蓝色)。
如果你写了几段话,从统计上讲,你使用的大约一半的单词可能会出现在特殊列表中(本文摘自《纽约时报》2022 年关于塞雷娜·威廉姆斯的文章):

当语言模型或聊天机器人写作时,它可以通过在特殊列表中选择比人们预期使用的更多的单词来插入水印。
上面的示例文本是由撰写水印论文的马里兰大学的研究人员生成的。 他们使用了一种技术,从本质上提高了特殊列表中单词的分数,使生成器更有可能使用它们。
当生成器到达文本中的这一点时,它会选择“the”这个词……

......但是“who”这个词在特别列表中,它的分数被人为地提高到足以超过“the”这个词:

当生成器到达这里时,“星期二”、“星期四”和“星期五”这些词出现在特殊列表中,但他们的分数并没有增加太多以超过了“星期六”,这是有意设计的。 为了使水印效果良好,它不应该否决 A.I. 在涉及日期或名称时选择词语,以避免插入虚假信息(尽管在这种情况下,人工智能是错误的:威廉姆斯女士的最后一场比赛确实是在星期五):
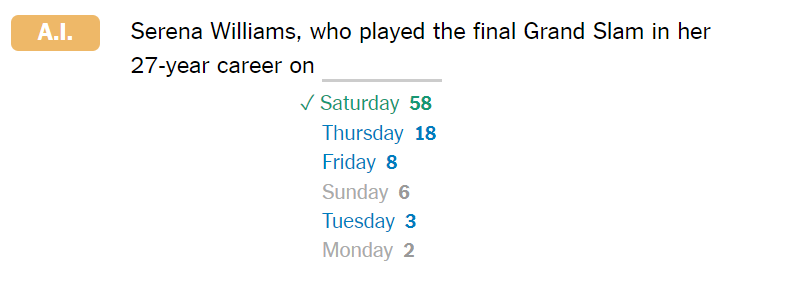
最后,生成的文本中大约 70% 的单词都在特殊列表中——远远超过人工编写的文本中的单词。 知道哪些词在特殊列表中的检测工具将能够区分生成的文本和人写的文本。

这对于生成的文本特别有帮助,因为它包含一些事实错误。
如果有人试图通过编辑文本来去除水印,他们将不知道要更改哪些词。 即使他们设法改变了一些特殊的词,他们也很可能只会将总百分比降低几个百分点。
马里兰大学教授、水印论文的合著者汤姆戈德斯坦说,即使是“非常短的文本片段”,例如一条推文,也可以检测到水印。 相比之下,OpenAI 发布的检测工具至少需要 1000 个字符。
然而,与所有检测方法一样,加水印也不是完美的,Goldstein 博士说。 OpenAI 目前的检测工具经过训练可以识别由 34 种不同语言模型生成的文本,而水印检测器只能识别由使用与检测器本身相同的特殊单词列表的模型或聊天机器人生成的文本。 这意味着除非 A.I. 公司就标准水印实现达成一致,该方法可能导致未来必须根据几种不同的水印检测工具检查有问题的文本。
Goldstein 博士说,要使水印在诸如 ChatGPT 这样广泛使用的产品中每次都能很好地工作,而不降低其输出质量,将需要大量的工程设计。 OpenAI 的 Leike 博士表示,该公司仍在研究将水印作为一种检测形式,并补充说它可以补充当前的工具,因为两者“各有优缺点”。
尽管如此,许多专家仍然相信可以可靠地检测所有 A.I. 的一站式工具。 完全准确的文本可能遥不可及。 这在一定程度上是因为可能会出现有助于消除一段文本是由人工智能生成的证据的工具。 并且生成的文本,即使它带有水印,在它只占较大文章的一小部分的情况下也很难检测到。 专家还表示,检测工具,尤其是那些不使用水印的检测工具,如果一个人对生成的文本进行了足够多的更改,可能无法识别生成的文本。
“我认为将会有一个神奇的工具,无论是由模型供应商创建还是由外部第三方创建,这将消除疑虑——我认为我们不会拥有这种奢侈 生活在那个世界里,”麻省理工学院-IBM 沃森人工智能中心主任大卫考克斯说。 实验室。
OpenAI 的首席执行官 Sam Altman 在上个月接受 StrictlyVC 采访时也表达了类似的看法。
“从根本上说,我认为不可能做到完美,”奥特曼先生说。 “人们会弄清楚他们必须更改多少文本。 还会有其他东西修改输出的文本。”
考克斯博士说,部分问题在于检测工具本身存在一个难题,因为它们可以更容易地避免检测。 一个人可以反复编辑生成的文本,并根据检测工具对其进行检查,直到文本被识别为人写的——这个过程有可能实现自动化。 Cox 博士补充说,随着新语言模型的出现和现有语言模型的进步,检测技术总是会落后一步。
“这总是会有军备竞赛的因素,”他说。 “情况总是会出现新模型,人们会开发方法来检测它是假的。”
一些专家认为,OpenAI 和其他构建聊天机器人的公司应该在发布 AI 产品之前提出检测解决方案,而不是之后。 例如,OpenAI 在 11 月底推出了 ChatGPT,但直到大约两个月后的 1 月底才发布其检测工具。
到那时,教育工作者和研究人员已经在呼吁使用工具来帮助他们识别生成的文本。 许多人注册使用一种新的检测工具 GPTZero,该工具由普林斯顿大学的一名学生在寒假期间开发,并于 1 月 1 日发布。
“我们收到了绝大多数老师的来信,”创建 GPTZero 的学生 Edward Tian 说。 田先生说,截至 2 月中旬,已有 43,000 多名教师注册使用该工具。
“生成式 A.I. 是一项令人难以置信的技术,但对于任何新的创新,我们都需要建立保障措施,以负责任地采用它,而不是在发布后数月或数年,而是在发布后立即采用,”Tian先生指出。
原文链接:How ChatGPT Could Embed a ‘Watermark’ in the Text It Generates
BimAnt翻译整理,转载请标明出处





