
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
短短半年时间,OpenAI的ChatGPT已经无缝融入我们的日常生活,超越了传统的技术界限。 从寻求指导的学生到磨练技艺的作家,各个年龄段和职业的个人都接受了它的精确性、速度和非常人性化的对话。 这些聊天模型现在配备了 Langchain PDF 渲染功能,有望彻底改变各个行业,远远超出技术领域。
AutoGPTs、BabyAGI 和 Langchain 等开源工具的出现及其创新的 Langchain PDF 功能,标志着利用大型语言模型功能的一个重要里程碑。 这些工具使用户能够通过简单的提示自动化编程任务,建立语言模型和数据源之间的连接,并加快人工智能应用程序的开发。 Langchain 尤其脱颖而出,是一款支持 ChatGPT 的 PDF 问答工具,为轻松创建 AI 应用程序提供了全面的解决方案。
本文的学习目标如下:
- 使用 Gradio 构建聊天机器人界面
- 从 pdf 中提取文本并创建嵌入
- 将嵌入存储在 Chroma 矢量数据库中
- 发送查询到后端(Langchain链)
- 对文本执行语义搜索以查找相关数据源
- 将数据发送到 LLM (ChatGPT) 并在聊天机器人上接收答案
Langchain简化了实现这些目标的过程,系统地引导用户完成每个阶段。 凭借对嵌入模型、聊天模型和矢量数据库等多种服务的支持,Langchain 有助于创建专为 PDF 交互定制的聊天机器人。 这种无缝工作流程扩展到与 Streamlit 集成、处理多个 PDF 以及利用 RAG 进行语义搜索功能。
1、什么是Langchain?
Langchain 是一款开源工具,非常适合增强 GPT-4 或 GPT-3.5 等聊天模型。 它无缝连接外部数据,使模型更加代理和数据感知。 借助 Langchain,你可以以前所未有的方式向模型引入新数据。 该平台提供多个链,简化了与语言模型的交互。 除了 Langchain 之外,用于创建向量嵌入的 Models 等工具也发挥着至关重要的作用。 在处理 Langchain 时,渲染 PDF 文件图像的能力也值得注意。 现在,让我们深入研究文本嵌入的意义。
1.1 文本嵌入
文本嵌入是大型语言操作的核心和灵魂。 从技术上讲,我们可以使用自然语言的语言模型,但存储和检索自然语言的效率非常低。 例如,在这个项目中,我们需要对大块数据执行高速搜索操作。 对自然语言数据执行此类操作是不可能的。
为了提高效率,我们需要将文本数据转换为矢量形式。 有专用的机器学习模型可用于从文本创建嵌入。 文本被转换为多维向量。 嵌入后,我们可以对这些数据进行分组、排序、搜索等。 我们可以计算两个句子之间的距离来了解它们的相关程度。 最好的部分是这些操作不仅限于像传统数据库搜索那样的关键字,而是捕获两个句子的语义接近度。 由于机器学习,这使得它变得更加强大。
1.2 Langchain工具
Langchain 拥有所有主要矢量数据库的包装器,例如 Chroma、Redis、Pinecone、Alpine db 等。 LLM 也是如此,除了 OpeanAI 模型,它还支持 Cohere 的模型 GPT4ALL——GPT 模型的开源替代品。 对于嵌入,它提供了 OpeanAI、Cohere 和 HuggingFace 嵌入的包装器。 您还可以使用自定义嵌入模型。
所以,简而言之,Langchain 是一个元工具,它抽象出了与底层技术交互的许多复杂性,这使得任何人都可以更轻松地快速构建 AI 应用程序。
在本文中,我们将使用 OpeanAI 嵌入模型来创建嵌入。 如果你想为最终用户部署人工智能应用程序,请考虑使用任何开源模型,例如 Huggingface 模型或 Google 的通用句子编码器。
为了存储矢量,我们将使用 Chroma DB,一个开源矢量存储数据库。 请随意探索其他数据库,例如 Alpine、Pinecone 和 Redis。 Langchain 拥有所有这些矢量存储的包装器。
为了创建 Langchain 链,我们将使用 ConversationalRetrievalChain(),它非常适合与具有历史记录的聊天模型进行对话(以保留对话的上下文)。 请查看他们关于不同 LLM 链的官方文档。
2、设置开发环境
我们将使用很多库。 因此,请提前安装它们。 要创建无缝、整洁的开发环境,请使用虚拟环境或 Docker。
gradio = "^3.27.0"
openai = "^0.27.4"
langchain = "^0.0.148"
chromadb = "^0.3.21"
tiktoken = "^0.3.3"
pypdf = "^3.8.1"
pymupdf = "^1.22.2"现在,导入这些库:
import gradio as gr
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.chains import ConversationalRetrievalChain
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import PyPDFLoader
import os
import fitz
from PIL import Image3、构建聊天界面
该应用程序的界面将有两个主要功能,一个是聊天界面,另一个将PDF的相关页面呈现为图像。 除此之外,还有一个用于接受最终用户的 OpenAI API 密钥的文本框。 我强烈建议您阅读这篇文章,从头开始使用 Gradio 构建 GPT 聊天机器人。 本文讨论了 Gradio 的基本方面。 我们将从这篇文章中借用很多东西。
Gradio Blocks 类允许我们构建一个 Web 应用程序。 Row 和 Columns 类允许在 Web 应用程序上对齐多个组件。 我们将使用它们来定制 Web 界面。
with gr.Blocks() as demo:
# Create a Gradio block
with gr.Column():
with gr.Row():
with gr.Column(scale=0.8):
api_key = gr.Textbox(
placeholder='Enter OpenAI API key',
show_label=False,
interactive=True
).style(container=False)
with gr.Column(scale=0.2):
change_api_key = gr.Button('Change Key')
with gr.Row():
chatbot = gr.Chatbot(value=[], elem_id='chatbot').style(height=650)
show_img = gr.Image(label='Upload PDF', tool='select').style(height=680)
with gr.Row():
with gr.Column(scale=0.70):
txt = gr.Textbox(
show_label=False,
placeholder="Enter text and press enter"
).style(container=False)
with gr.Column(scale=0.15):
submit_btn = gr.Button('Submit')
with gr.Column(scale=0.15):
btn = gr.UploadButton("📁 Upload a PDF", file_types=[".pdf"]).style()界面很简单,只有几个组件。
它有:
- 与 PDF 进行交流的聊天界面。
- 用于渲染相关 PDF 页面的组件。
- 用于接受 API 密钥的文本框和更改密钥按钮。
- 用于提问的文本框和提交按钮。
- 用于上传文件的按钮。
这是 Web UI 的快照:
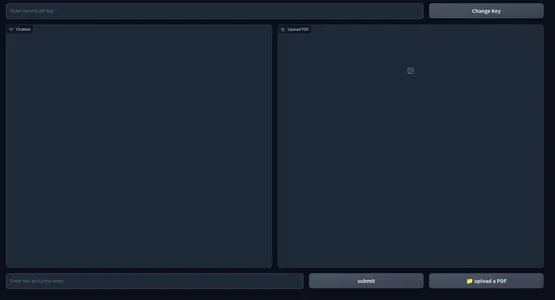
我们的应用程序的前端部分已经完成。 让我们跳到后端。
3.1 后端
首先,让我们概述一下我们将要处理的流程。
- 处理上传的 PDF 和 OpenAI API 密钥
- 从 PDF 中提取文本并使用 OpenAI 嵌入创建文本嵌入。
- 将向量嵌入存储在 ChromaDB 矢量存储中。
- 使用 Langchain 创建会话检索链。
- 创建查询文本的嵌入并对嵌入文档执行相似性搜索。
- 将相关文档发送到OpenAI聊天模型(gpt-3.5-turbo)。
- 获取答案并将其流式传输到聊天 UI 上。
- 在 Web UI 上呈现相关 PDF 页面。
这些是我们应用程序的概述。 让我们开始构建它。
3.2 Gradio事件
当在 Web UI 上执行特定操作时,将触发这些事件。 因此,这些事件使 Web 应用程序具有交互性和动态性。 Gradio 允许我们用 Python 代码定义事件。
Gradio Events 使用我们之前定义的组件变量与后端进行通信。 我们将定义应用程序所需的一些事件。 这些都是
- 提交 API key 事件:粘贴 API key 后按 Enter 键将触发此事件。
- 更改密钥:这将允许您提供新的 API 密钥
- 输入查询:向聊天机器人提交文本查询
- 上传文件:这将允许最终用户上传 PDF 文件
with gr.Blocks() as demo:
# Create a Gradio block
with gr.Column():
with gr.Row():
with gr.Column(scale=0.8):
api_key = gr.Textbox(
placeholder='Enter OpenAI API key',
show_label=False,
interactive=True
).style(container=False)
with gr.Column(scale=0.2):
change_api_key = gr.Button('Change Key')
with gr.Row():
chatbot = gr.Chatbot(value=[], elem_id='chatbot').style(height=650)
show_img = gr.Image(label='Upload PDF', tool='select').style(height=680)
with gr.Row():
with gr.Column(scale=0.70):
txt = gr.Textbox(
show_label=False,
placeholder="Enter text and press enter"
).style(container=False)
with gr.Column(scale=0.15):
submit_btn = gr.Button('Submit')
with gr.Column(scale=0.15):
btn = gr.UploadButton("📁 Upload a PDF", file_types=[".pdf"]).style()
# Set up event handlers
# Event handler for submitting the OpenAI API key
api_key.submit(fn=set_apikey, inputs=[api_key], outputs=[api_key])
# Event handler for changing the API key
change_api_key.click(fn=enable_api_box, outputs=[api_key])
# Event handler for uploading a PDF
btn.upload(fn=render_first, inputs=[btn], outputs=[show_img])
# Event handler for submitting text and generating response
submit_btn.click(
fn=add_text,
inputs=[chatbot, txt],
outputs=[chatbot],
queue=False
).success(
fn=generate_response,
inputs=[chatbot, txt, btn],
outputs=[chatbot, txt]
).success(
fn=render_file,
inputs=[btn],
outputs=[show_img]
)到目前为止,我们还没有定义在上面的事件处理程序中调用的函数。 接下来,我们将定义所有这些函数来制作一个功能性的网络应用程序。
3.3 处理 API 密钥
处理用户的 API 密钥非常重要,因为整个过程都按照 BYOK(自带密钥)原则运行。 每当用户提交密钥时,文本框必须变得不可变,并提示已设置密钥。 当触发“更改密钥”事件时,该框必须能够接受输入。
为此,请定义两个全局变量。
enable_box = gr.Textbox.update(value=None,placeholder= 'Upload your OpenAI API key',
interactive=True)
disable_box = gr.Textbox.update(value = 'OpenAI API key is Set',interactive=False)定义函数:
def set_apikey(api_key):
os.environ['OPENAI_API_KEY'] = api_key
return disable_box
def enable_api_box():
return enable_boxset_apikey 函数接受字符串输入并返回disable_box 变量,这使得文本框在执行后不可变。 在Gradio Events部分,我们定义了api_key Submit Event,它调用set_apikey函数。 我们使用操作系统库将 API 密钥设置为环境变量。
单击“更改 API 密钥”按钮将返回 enable_box 变量,这将再次启用文本框的可变性。
3.4 创建链
这是最重要的一步。 此步骤涉及提取文本并创建嵌入并将它们存储在向量存储中。 感谢 Langchain,它为多种服务提供了包装器,使事情变得更容易。 那么,让我们定义这个函数。
def process_file(file):
# raise an error if API key is not provided
if 'OPENAI_API_KEY' not in os.environ:
raise gr.Error('Upload your OpenAI API key')
# Load the PDF file using PyPDFLoader
loader = PyPDFLoader(file.name)
documents = loader.load()
# Initialize OpenAIEmbeddings for text embeddings
embeddings = OpenAIEmbeddings()
# Create a ConversationalRetrievalChain with ChatOpenAI language model
# and PDF search retriever
pdfsearch = Chroma.from_documents(documents, embeddings,)
chain = ConversationalRetrievalChain.from_llm(ChatOpenAI(temperature=0.3),
retriever=
pdfsearch.as_retriever(search_kwargs={"k": 1}),
return_source_documents=True,)
return chain- 创建了 API 密钥是否已设置的检查。 如果未设置密钥,这将在前端引发错误。
- 使用 PyPDFLoader 加载 PDF 文件
- 使用 OpenAIEmbeddings 定义嵌入函数。
- 使用嵌入功能从 PDF 文本列表创建矢量存储。
- 使用 chatOpenAI(默认情况下 ChatOpenAI 使用 gpt-3.5-turbo)定义一条链,一个基本检索器(使用相似性搜索)。
3.5 生成响应
创建链后,我们将调用该链并发送查询。 发送聊天历史记录和查询,以保留对话上下文并将响应流式传输到聊天界面。 让我们定义这个函数。
def generate_response(history, query, btn):
global COUNT, N, chat_history
# Check if a PDF file is uploaded
if not btn:
raise gr.Error(message='Upload a PDF')
# Initialize the conversation chain only once
if COUNT == 0:
chain = process_file(btn)
COUNT += 1
# Generate a response using the conversation chain
result = chain({"question": query, 'chat_history':chat_history}, return_only_outputs=True)
# Update the chat history with the query and its corresponding answer
chat_history += [(query, result["answer"])]
# Retrieve the page number from the source document
N = list(result['source_documents'][0])[1][1]['page']
# Append each character of the answer to the last message in the history
for char in result['answer']:
history[-1][-1] += char
# Yield the updated history and an empty string
yield history, ''- 如果没有上传 PDF,则会引发错误。
- 仅调用一次 process_file 函数。
- 将查询和聊天记录发送到链
- 检索最相关答案的页码。
- 向前端产生响应。
3.6 PDF 文件的渲染图像
最后一步是使用最相关的答案渲染 PDF 文件的图像。 我们可以使用 PyMuPdf 和 PIL 库来渲染文档的图像。
def render_file(file):
global N
# Open the PDF document using fitz
doc = fitz.open(file.name)
# Get the specific page to render
page = doc[N]
# Render the page as a PNG image with a resolution of 300 DPI
pix = page.get_pixmap(matrix=fitz.Matrix(300/72, 300/72))
# Create an Image object from the rendered pixel data
image = Image.frombytes('RGB', [pix.width, pix.height], pix.samples)
# Return the rendered image
return image- 使用 PyMuPdf 的 Fitz 打开文件。
- 获取相关页面。
- 获取页面的像素图。
- 从 PIL 的 Image 类创建图像。
这就是我们为与任何 PDF 聊天的功能性 Web 应用程序所需要做的一切。
将所有内容放在一起
#import csv
import gradio as gr
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.chains import ConversationalRetrievalChain
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import PyPDFLoader
import os
import fitz
from PIL import Image
# Global variables
COUNT, N = 0, 0
chat_history = []
chain = ''
enable_box = gr.Textbox.update(value=None,
placeholder='Upload your OpenAI API key', interactive=True)
disable_box = gr.Textbox.update(value='OpenAI API key is Set', interactive=False)
# Function to set the OpenAI API key
def set_apikey(api_key):
os.environ['OPENAI_API_KEY'] = api_key
return disable_box
# Function to enable the API key input box
def enable_api_box():
return enable_box
# Function to add text to the chat history
def add_text(history, text):
if not text:
raise gr.Error('Enter text')
history = history + [(text, '')]
return history
# Function to process the PDF file and create a conversation chain
def process_file(file):
if 'OPENAI_API_KEY' not in os.environ:
raise gr.Error('Upload your OpenAI API key')
loader = PyPDFLoader(file.name)
documents = loader.load()
embeddings = OpenAIEmbeddings()
pdfsearch = Chroma.from_documents(documents, embeddings)
chain = ConversationalRetrievalChain.from_llm(ChatOpenAI(temperature=0.3),
retriever=pdfsearch.as_retriever(search_kwargs={"k": 1}),
return_source_documents=True)
return chain
# Function to generate a response based on the chat history and query
def generate_response(history, query, btn):
global COUNT, N, chat_history, chain
if not btn:
raise gr.Error(message='Upload a PDF')
if COUNT == 0:
chain = process_file(btn)
COUNT += 1
result = chain({"question": query, 'chat_history': chat_history}, return_only_outputs=True)
chat_history += [(query, result["answer"])]
N = list(result['source_documents'][0])[1][1]['page']
for char in result['answer']:
history[-1][-1] += char
yield history, ''
# Function to render a specific page of a PDF file as an image
def render_file(file):
global N
doc = fitz.open(file.name)
page = doc[N]
# Render the page as a PNG image with a resolution of 300 DPI
pix = page.get_pixmap(matrix=fitz.Matrix(300/72, 300/72))
image = Image.frombytes('RGB', [pix.width, pix.height], pix.samples)
return image
# Gradio application setup
with gr.Blocks() as demo:
# Create a Gradio block
with gr.Column():
with gr.Row():
with gr.Column(scale=0.8):
api_key = gr.Textbox(
placeholder='Enter OpenAI API key',
show_label=False,
interactive=True
).style(container=False)
with gr.Column(scale=0.2):
change_api_key = gr.Button('Change Key')
with gr.Row():
chatbot = gr.Chatbot(value=[], elem_id='chatbot').style(height=650)
show_img = gr.Image(label='Upload PDF', tool='select').style(height=680)
with gr.Row():
with gr.Column(scale=0.70):
txt = gr.Textbox(
show_label=False,
placeholder="Enter text and press enter"
).style(container=False)
with gr.Column(scale=0.15):
submit_btn = gr.Button('Submit')
with gr.Column(scale=0.15):
btn = gr.UploadButton("📁 Upload a PDF", file_types=[".pdf"]).style()
# Set up event handlers
# Event handler for submitting the OpenAI API key
api_key.submit(fn=set_apikey, inputs=[api_key], outputs=[api_key])
# Event handler for changing the API key
change_api_key.click(fn=enable_api_box, outputs=[api_key])
# Event handler for uploading a PDF
btn.upload(fn=render_first, inputs=[btn], outputs=[show_img])
# Event handler for submitting text and generating response
submit_btn.click(
fn=add_text,
inputs=[chatbot, txt],
outputs=[chatbot],
queue=False
).success(
fn=generate_response,
inputs=[chatbot, txt, btn],
outputs=[chatbot, txt]
).success(
fn=render_file,
inputs=[btn],
outputs=[show_img]
)
demo.queue()
if __name__ == "__main__":
demo.launch()现在我们已经配置了一切,让我们启动我们的应用程序。
您可以使用以下命令在调试模式下启动应用程序
gradio app.py你也可以简单地使用 Python 命令运行应用程序。 下面是最终产品的快照。 代码的 GitHub 存储库。
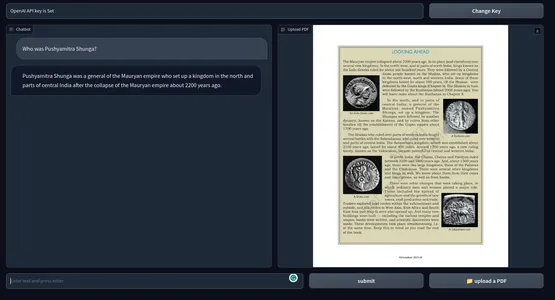
4、可能的改进
当前的应用程序运行良好。 但你可以采取一些措施来使其变得更好。
- 这使用了 OpenAI 嵌入,从长远来看可能会很昂贵。 对于生产就绪的应用程序,任何离线嵌入模型可能更合适。
- 用于原型设计的 Gradio 很好,但对于现实世界来说,具有现代 JavaScript 框架(如 Next Js 或 Svelte)的应用程序在性能和美观方面会更好。
- 我们使用余弦相似度来查找相关文本。 在某些情况下,KNN 方法可能更好。
- 对于文本内容密集的 PDF,创建较小的文本块可能会更好。
- 模型越好,性能就越好。 与其他LLM进行实验并比较结果。
6、实际用例
使用跨多个领域的工具,从教育到法律再到学术界或您可以想象的任何需要人们阅读大量文本的领域。 ChatGPT 用于 PDF 的一些实际用例是
- 教育机构:学生可以上传教科书、学习材料和作业,该工具可以回答查询并解释特定部分。 这可以减轻学生的整体学习过程的压力。
- 法律:律师事务所必须处理大量 PDF 格式的法律文件。 该工具可以方便地从案件文件、法律合同、法规中提取相关信息。 它可以帮助律师更快地找到条款、先例和其他信息。
- 学术界:研究学者经常处理研究论文和技术文档。 一个能够总结文献、分析文档并提供答案的工具可以大大节省总体时间并提高生产力。
- 行政机构:政府。 办公室和其他行政部门每天要处理大量的表格、申请和报告。 使用回答文档的聊天机器人可以简化管理流程,从而节省每个人的时间和金钱。
- 财务:分析财务报告并一次又一次地重新审视它们是乏味的。 通过使用聊天机器人可以使这变得更容易。 本质上是实习生。
- 媒体:记者和分析师可以使用支持 chatGPT 的 PDF 问答工具来查询大型文本语料库,以快速找到答案。
支持 chatGPT 的 PDF 问答工具可以更快地从大量 PDF 文本中收集信息。 它就像一个文本数据的搜索引擎。 不仅仅是 PDF,我们还可以通过一些代码操作将此工具扩展到任何包含文本数据的内容。
7、结束语
在本教程中,我们探索了如何利用 Langchain PDF 的功能,构建一个聊天机器人界面,以便使用 ChatGPT 与 PDF 文件进行交互。 通过集成自然语言处理技术和参数调整,我们为查询和检索 PDF 文档中的信息创建了无缝的用户体验。
要点:
- 事实证明,Gradio 是快速开发应用程序前端的宝贵工具,允许用户与聊天机器人交互并轻松上传 PDF 文件。
- Langchain 在我们应用程序的后端系统中发挥了关键作用,为 ChatGPT 等语言模型提供了包装器,并支持与底层服务的轻松交互。
- 利用 OpenAI 的嵌入和 GPT-3.5 引擎,我们增强了聊天机器人理解和响应用户查询的能力,促进与 PDF 文档的类人对话。
- 将 ChatGPT 集成到我们的应用程序中,使其成为强大的 PDF 问答工具,使用户能够有效地提取相关信息。
- 通过利用 Gradio、Langchain 和 OpenAI 模型的综合力量,我们演示了 AI 应用程序如何简化知识任务、节省时间并提高生产力。
要开始构建类似的应用程序,请考虑探索提示工程技术、微调模型参数以及通过 pip install 安装必要的库(例如 Transformer)。 借助这些可用的工具和技术,你可以释放自然语言处理的潜力并为各个领域构建创新的解决方案。
原文链接:Build a ChatGPT for PDFs with Langchain
BimAnt翻译整理,转载请标明出处





