
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
在作为一名自由数据记者和新闻应用程序开发人员的工作中,我花了很多时间开发系统,让技术含量较低的记者、编辑和公众能够与数据库进行交互。 然而,无论系统设计得多么好,经常会出现只能通过数据库查询来回答的问题,通常用 SQL(结构化查询语言)编写。
随着在本地计算机上运行的大型语言模型 (LLM)(而不是使用 OpenAI 等云服务)的兴起,我想知道是否有可能让 AI 代理通过翻译和执行 SQL 来回答用自然语言编写的问题 对自定义数据库的查询。 例如,这对我作为数据记者是否有用,可以更快地挖掘数据集以获取有用信息? 是否有可能拥有一个本地人工智能系统,以便我可以即时提出这些问题,以减少对专有模型的依赖并保护我正在调查的任何机密数据源? 或者,也许记者和编辑可以直接与它互动并找到一些有用的东西?
为了开始探索这些可能性,我将本地大型语言模型和 Reason + Act 提示与一组基于 SQLite 查询的操作结合起来。 在这篇文章中,我详细介绍了一系列实验。在我作为自由数据记者和新闻应用程序开发人员的工作中,我花了很多时间开发系统,让技术含量较低的记者、编辑和公众能够与数据库进行交互。 然而,无论系统设计得多么好,经常会出现只能通过数据库查询来回答的问题,通常用 SQL(结构化查询语言)编写。
随着在本地计算机上运行的大型语言模型 (LLM)(而不是使用 OpenAI 等云服务)的兴起,我想知道是否有可能让 AI 代理通过翻译和执行 SQL 来回答用自然语言编写的问题 对自定义数据库的查询。 例如,这对我作为数据记者是否有用,可以更快地挖掘数据集以获取有用信息? 是否有可能拥有一个本地人工智能系统,以便我可以即时提出这些问题,以减少对专有模型的依赖并保护我正在调查的任何机密数据源? 或者,也许记者和编辑可以直接与它互动并找到一些有用的东西?
为了开始探索这些可能性,我将本地大型语言模型和 Reason + Act 提示与一组基于 SQLite 查询的操作结合起来。 在这篇文章中,我详细介绍了一系列实验,在这些实验中我研究了它们如何很好地回答我的数据中的问题。
1、推理与行动
预训练的LLM是静态的。 他们受到训练数据的限制。 他们在训练中看到的有关特定主题或观点的数据越少,他们就越不可能准确回答相关问题。 如果你问 ChatGPT 你当地的市长是谁,它很可能会给你一些过时甚至不正确的信息。 因此,使用LLM作为基于知识的任务的来源通常是行不通的。
Reason + Act(又名 ReAct,不要与 JavaScript 库混淆)是一种提示格式,它使 LLM 能够与系统交互、检索结果,并在得出结论时将该信息合并到其推理中。
它的工作原理是将“推理”与行动交织在一起,“推理”帮助模型制定和遵循计划,而“行动”则允许通过 API 访问外部“工具”,其中可能包括其他软件或数据/知识。 ReAct 跟踪(跟踪是 LLM 回答问题所采取的所有步骤的完整日志)如下所示,摘自 Colin Eberhardt 的 用 100 行代码重新实现 LangChain:
Question:你必须回答的输入问题
Thought:你应该时刻思考该做什么
Action:要采取的行动,应该是以下之一:[此处的行动列表]
Action Input 1:动作的第一个输入。
Observation:行动的结果
…(这个想法/行动/行动输入/观察可以重复N次)
thought:我现在知道了最终答案
Final Answer:原始输入问题的最终答案
这个想法是构建一个提示(提示是我们输入到 LLM 的一段文本),其中包括一两个示例 ReAct 跟踪,演示问题的各种解决方案。 然后我们提出要回答的问题,并让 LLM 继续,直到输出序列结束标记或“观察:”。 此时,我们查看输出,解析任何“操作”语句和相关的“操作输入”。 这会导致使用这些参数调用 Python 函数。 无论函数返回什么,都会作为“观察”以及模型的先前响应附加到提示中。 这种情况一直持续到我们用完上下文空间或者LLM得出“最终答案”,表明它已经得出了它认为是初始问题的答案。
这是专门为了解决传统LLM在事实检查和问答问题等任务中的表现缺陷而开发的。 ReAct 还有助于提高LLM问题答案的人类可解释性。
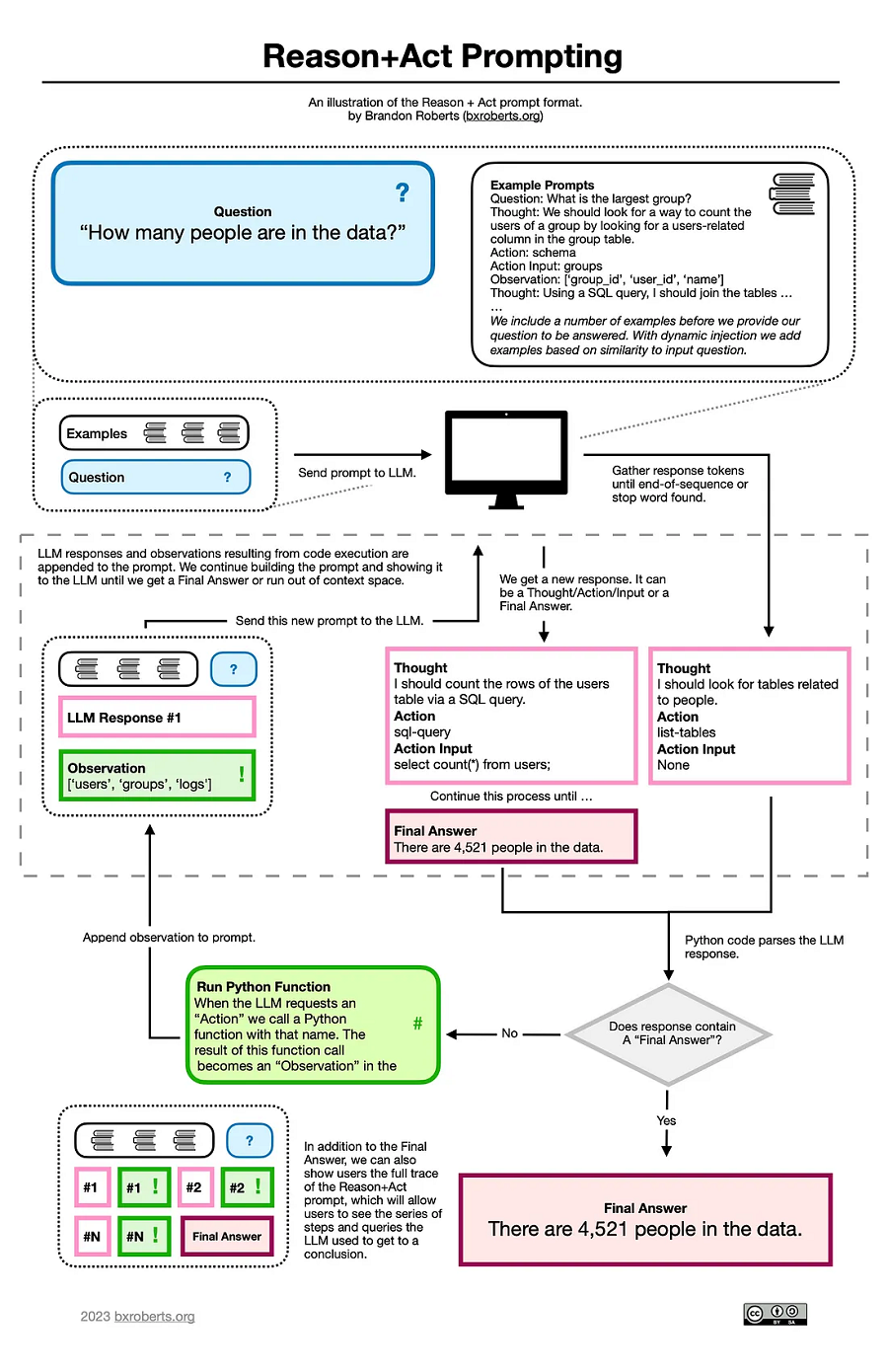
2、LLM加 SQLite
我可用的数据采用 SQLite 数据库的形式(SQLite 数据库是可移植的关系数据库,适合单个文件并允许你执行 SQL 查询)。 为了允许 LLM 通过 SQL 查询与我的数据进行交互,我为其提供了一些操作:
- tables:列出数据库中的表。
- schema:返回给定表的架构(即所有变量)。
- help:提供表和列的上下文。 这是为了避免提示本身的信息过载。 法学硕士可以在使用表或列之前请求帮助。 (例如“此列可用于加入组表”或“有时用户在此字段中提及他们的位置”)
- sql-query:执行 SQLite3 查询并返回前 3 个结果(以保留上下文空间,但允许“前几个”类型的问题)。
如果 LLM 使用错误的操作,所有这些操作都会产生有用的错误信息。 如果 LLM 犯了常见错误,例如询问不存在的表的架构或 SQL 查询命名错误的列或尝试使用未启用的 SQLite 扩展,这有助于 LLM 恢复。
通过这四个操作,我手动生成了一些示例跟踪。 这些的目标是向模型展示如何使用每个操作以及一些基本的 SQL 策略。 在向LLM提出需要回答的实际问题之前,这些内容已添加到提示中。
3、模型和工具选择
如果你研究过本地LLM的世界,可能会不知所措。 模型、格式、工具和提示类型的数量令人难以置信。 特别是一位用户 Tom “TheBloke” Jobbins,在 Hugging Face 上有超过 2000 多个LLM可供下载。 为了完成这一切,我需要一种方法以标准化的方式测试许多不同的模型。
我编写了一个脚本,向每个模型询问一组问题并记录结果。 然后,我根据准确性— 基于正确答案关键字(例如美元金额和名称)的存在 —对结果进行评分。
我将搜索重点放在Alpaca排行榜上的顶级模型上。 排行榜上的模型可以成功回答各种问题并完成包括编程问题和逻辑难题在内的任务。 我的假设是这些候选人可能擅长 SQL 编码和推理。 我还扩大了搜索范围,纳入了同事推荐的一些模型以及 GPT-4 Turbo 进行比较。 我主要关注较小的 7B 参数模型(例如 Mistral、Llama 2),因为这些模型是最平易近人且能够在笔记本电脑上运行的,但我也测试了一些 13B 和 70B 模型。
4、实验设计
该测试包括六个问题,需要模型使用所有可用的表来执行日益复杂的查询。 这些数据来自我一直在处理的 Roblox 游戏和招聘信息。 Roblox Corporation 是 Roblox 平台背后的公司,是一家价值数十亿美元的公司,主要面向儿童。 我想回答新闻问题,例如有多少 18 岁以下的儿童在他们的论坛上寻找工作,尝试量化某些游戏赚到的钱,并找出任何不道德的行为。
以下是我向LLM提出的问题:
- “哪个团队的工作经验最多?” 要求模型按照团队列进行分组,计数然后排序,取前几名。
- “数据中所有游戏通行证的总价是多少?” 需要对整个表的价格列进行求和。
- “最受喜爱的游戏数量排名前三的游戏是什么?” 要求模型按“收藏夹”列进行数字排序,该列由带逗号的数字字符串组成。
- “工作的最低和最高年龄要求是多少?” 这要求模型确定 minAgeRequirement 列上的每个值都为零。
- “根据用户的个人资料描述,他们的年龄是多少?” 用户有时会在描述中提及他们的年龄(例如,“我 15 岁”)。 这要求模型进行字符串搜索并以不特定的顺序提取数字。
- “在个人资料描述中提及年龄的人中,平均年龄是多少? 您可以通过查找‘岁数’然后获取其前面的字符来找到它。” 在这里,我提供了一个提示来指导模型达到提取数字年龄并对其求平均值的目标。
与LLM合作的主要限制之一是其上下文大小。 这是LLM在输出时可以作为输入的最大标记数(单词和符号)。 对于大多数本地模型,上下文大小范围为 2k 到 4k。 像 GPT-4 这样的 OpenAI 模型在其最新版本中可以高达 128k 令牌,尽管使用更长的上下文也会带来更高的成本。 一切都必须符合这个限制,包括提示、示例、问题以及所有 ReAct 周期和最终答案。 超过这个限制就会导致失败。
由于需要为模型使用操作、编写 SQL 查询和检索 JSON 结果留出足够的上下文空间,这意味着我只能使用几个示例。
我设计了一个带有四个示例的通用提示。 其中两个重点是向LLM展示如何使用表格和帮助命令。 后两个示例展示了 SQL 查询解决方案。
5、初步结果
OpenAI 的 GPT-4 Turbo 模型在使用通用提示时始终表现良好。 这是一个非常灵活的模型,并且没有表现出有关幻觉的重大问题(温度=0)。 但较小的本地模型也具有惊人的竞争力(请注意,在非正式测试中,指令调整模型的表现往往比完成模型更差)。 在小型型号中,基于 7B Mistral 的模型表现最好。
当跟踪中提供的示例与问题密切匹配时(例如,解决方案需要 SQL 查询,其中只有列或表名称与示例不同),模型的表现始终良好。 需要基于数字字段进行简单排序或获取列的最大/最小值的问题都可以轻松解决。 但是,当模型需要从头开始编写复杂的查询并且不存在类似的示例时,LLM通常根本无法找到解决方案。 当数据需要转换或解析时尤其如此。
例如,在第三个问题中,LLM需要连接两列,然后根据“收藏夹”列进行排序。 此列包含带逗号的数字字符串,因此模型需要先去掉逗号,然后才能将其转换为整数以进行数字排序。 (未能去掉逗号将导致所有包含 1 的值为零。)如果没有示例显示这一点,所有模型都无法得出正确答案。
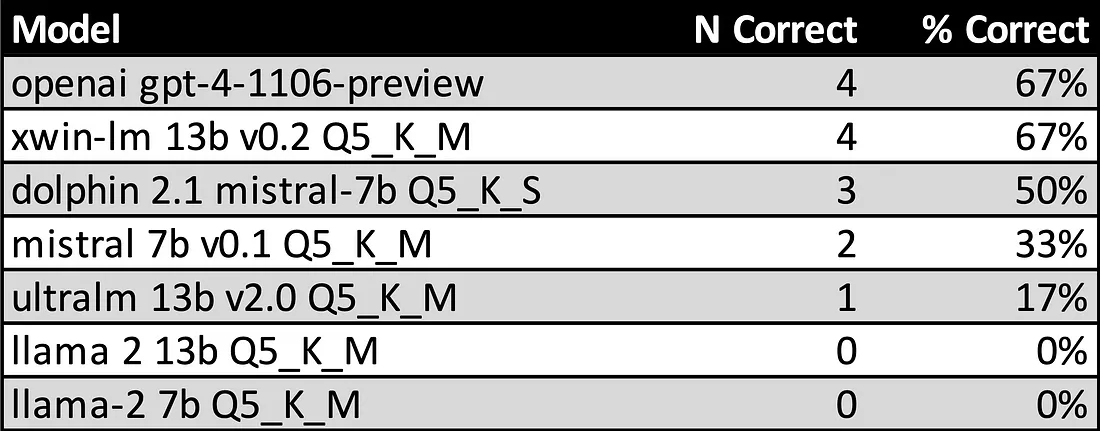
为了解决这个问题,我编写了几个额外的问答跟踪,涵盖所有表中的各种列、技术和 SQL 策略。 我不会向LLM提供包含所有示例的通用提示,而是根据输入问题与示例问题的相似性,动态地将各个示例注入到提示中。 我最初手动开发了这个过程,但现在可以根据与输入问题的语义相似性从小型数据库中提取适当的示例跟踪。 这显着提高了LLM针对提供了适用示例的问题提供解决方案的能力。
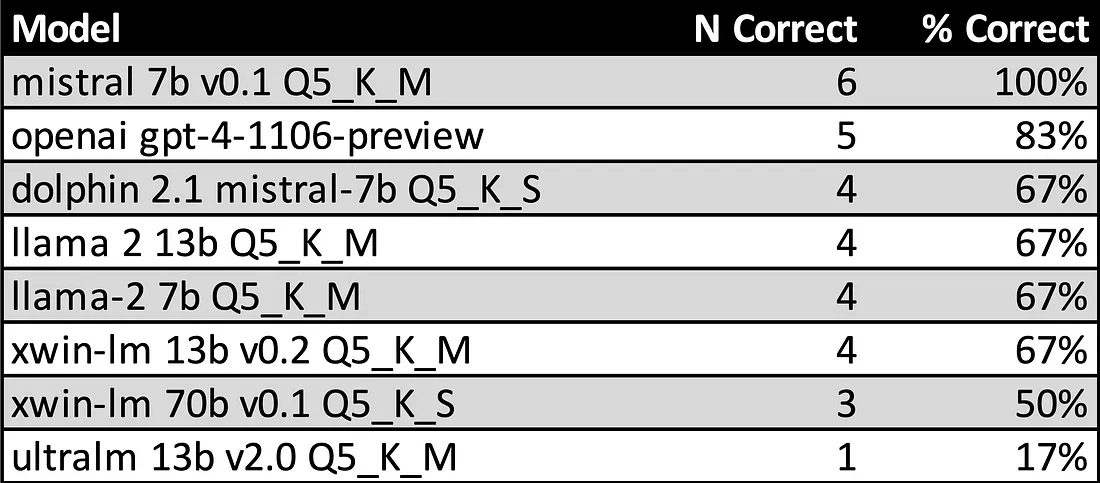
Mistral 7B 在动态注入示例提示策略方面表现最佳。 差异在于问题 6,该问题要求模型获取用户描述中提到的平均用户年龄。 Mistral 7B 意外地正确地完成了这一点。 OpenAI 的 GPT-4 Turbo 和 Mistral 7B 都错误地将非数字结果转换为整数(导致零),并将这些零包含在平均值中,导致平均值下降。 Mistral 将其结果四舍五入为 16(从 15.9 开始),这是所有模型最接近正确答案 16.3 岁的结果。
6、模式混乱
使用清晰、描述性的列名称非常重要。 为了说明这一点,我的一个表有一列名为“creatorDescription”的列,其中包含用户描述。 在LLM需要搜索用户描述的问题中,LLM花费了大量时间来弄清楚描述列不被称为“描述”。 这也是产生幻觉错误的常见原因。 LLM 有时会获取架构,并在其思想中注意该列称为“creatorDescription”,然后无论如何在 SQL 查询中使用“description”。 与其强迫法学硕士学习奇怪的列名称,不如简单地将列重命名为“描述”会更容易。
同样,名为“团队”的列对于模型来说也是不明确的,LLM需要做额外的工作才能发现该字段是团队名称而不是团队 ID。 将列重命名为“team_name”有助于消除需要使用该字段来得出解决方案的任务的含义。
LLM普遍都在复杂的数据转换方面遇到困难。 最具挑战性的测试问题要求模型从自由文本描述字段中提取年龄(例如,从包含文本“我是 22 岁”的个人资料中提取整数 22)。 SQLite 的内置标量函数很少。 当没有给出如何实现这一点的示例时,所有模型都无法弄清楚。 当我注入一个显示字符串搜索后跟负索引的示例提示时,该模型可以模仿该策略并将其应用于新问题。
在所有实验中,明确、简单和描述性地命名列有助于模型更频繁地找到解决方案。 如果您知道要回答有关在自由文本字段中找到的年龄的问题,最好创建一个已准确执行该转换的新列。 模型需要采取的步骤越少,其性能就越好。
7、结束语
在我的实验中,我发现小型本地 LLM 可以与更大的 70B 甚至 OpenAI GPT-4 Turbo 模型竞争。 由于尺寸较小,Mistral 7B 型号的表现尤其出色。 但幻觉、小上下文、复杂模式和数据转换仍然对所有LLM(尤其是小型LLM)构成挑战。
基于问题相似性的动态选择和示例注入提示被证明是一个非常成功的策略。 它使得一些模型即使对于非常复杂的问题也能得出正确的答案。 与微调方法所需的重新训练相比,添加新示例可以更快地解决新的不可预见的问题或数据问题。
虽然本地模型和 OpenAI 模型都成功地使用 Reason+Act 提示回答了 SQL 数据库中的问题,但这些模型是否适合一般受众则是另一个问题。 尤其是本地LLM,在偏见和一致性方面几乎没有任何保证,使得开放式问题容易受到这些缺陷的影响。
理性+行动痕迹本身也是建立模型输出信任的强大资产。 查看完整的跟踪、查看它尝试了哪些查询、为什么运行这些查询、检查查询结果以及识别模型出错或产生幻觉的区域都很容易。 使用传统的微调或再训练方法是不可能实现这一点的。
我计划对此进行扩展并探索使用更复杂的数据集和 RDBMS(例如 PostgreSQL)。 我发布了一个演示这些技术的视频,如果你想对自己的数据运行自己的实验,我还提供了代码。
原文链接:Can LLMs Help Us Understand Data?
BimAnt翻译整理,转载请标明出处





