
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
机器学习模型已经变得越来越大,以至于训练模型可能会给那些没有空闲集群的人带来痛苦。 此外,即使使用训练好的模型,当你的硬件与模型对其运行的期望不符时,推理的时间和内存成本也会飙升。 因此,为了缓解这个问题,我们并没有放弃类似 BERT 模型的深层知识,而是开发了一种称为蒸馏(distillation)的技术,将网络缩小到合理的大小,同时最大限度地减少性能损失。
如果你已经阅读了本系列的第一篇文章,那么这并不是什么新闻。 在其中,我们讨论了 DistilBERT 如何引入一种简单而有效的蒸馏技术,可以轻松应用于任何类似 BERT 的模型,但我们避开了任何具体的实现。 现在,我们将详细介绍如何将想法转化为 .py 文件。
1、学生模型的初始化
由于我们想要从现有模型初始化一个新模型,因此需要访问旧模型(即教师)的权重。 我们假设预先存在的模型是在 PyTorch 上实现的 Hugging Face 模型, 因此,要获得权重,首先必须知道如何访问它们。 我们将使用 RoBERTa large 作为我们的教师模型。
1.1 Hugging Face的模型结构
我们可以尝试的第一件事是打印模型结构,这应该让我们深入了解它是如何制作的。 当然,我们总是可以深入研究 Hugging Face 文档 ,但这并不有趣。
from transformers import AutoModelForMaskedLM
roberta = AutoModelForMaskedLM.from_pretrained("roberta-large")
print(roberta)运行此代码后,我们得到:
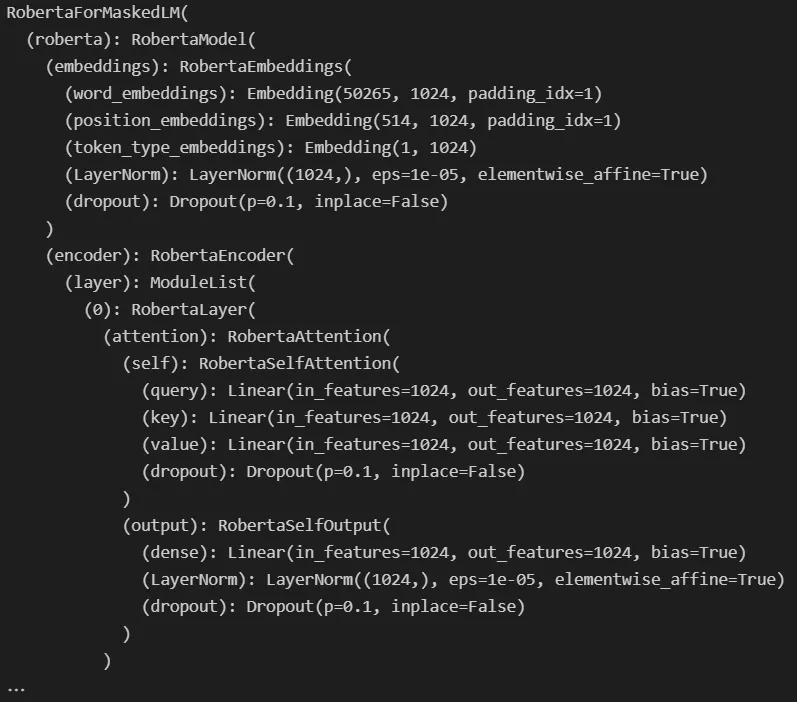
模型的结构开始出现,但我们可以让它变得更漂亮。 在 Hugging Face 模型中,我们可以使用 .children() 生成器访问模块的子组件。 因此,如果我们想要遍历整个模型,我们需要在其上调用 .children() ,并在每个产生的子级上继续调用 .children() ,等等......这描述了一个递归函数,代码如下:
from typing import Any
from transformers import AutoModelForMaskedLM
roberta = AutoModelForMaskedLM.from_pretrained("roberta-large")
def visualize_children(
object : Any,
level : int = 0,
) -> None:
"""
Prints the children of (object) and their children too, if there are any.
Uses the current depth (level) to print things in a ordonnate manner.
"""
print(f"{' ' * level}{level}- {type(object).__name__}")
try:
for child in object.children():
visualize_children(child, level + 1)
except:
pass
visualize_children(roberta)输出结果如下:
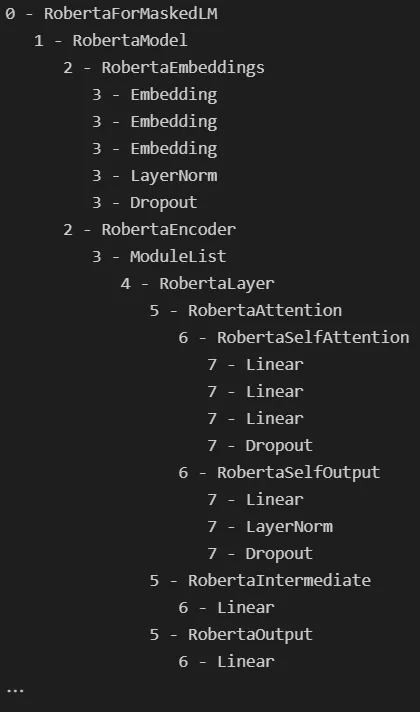
通过展开这棵树,看起来 RoBERTa 模型的结构与其他类似 BERT 的模型一样,如下所示:
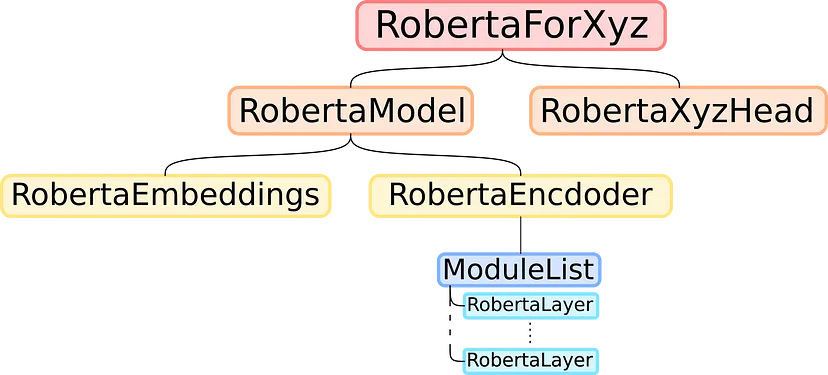
1.2 复制教师模型的权重
我们知道,要以 DistilBERT 的方式初始化类似 BERT 的模型,我们只需要复制除 Roberta 层最深层之外的所有内容,我们省略了其中的一半。
首先,我们需要创建学生模型,其架构与教师模型相同,但隐藏层数量只有一半。
为此,我们只需要使用教师模型的配置,它是一个类似字典的对象,描述了 Hugging Face 模型的架构。 当查看 roberta.config 属性时,我们可以看到以下内容:

我们在这里感兴趣的是 num-hidden-layers 属性。 让我们编写一个函数来复制此配置,通过将其除以 2 来更改该属性,并使用新配置创建一个新模型:
from transformers.models.roberta.modeling_roberta import RobertaPreTrainedModel, RobertaConfig
def distill_roberta(
teacher_model : RobertaPreTrainedModel,
) -> RobertaPreTrainedModel:
"""
Distilates a RoBERTa (teacher_model) like would DistilBERT for a BERT model.
The student model has the same configuration, except for the number of hidden layers, which is // by 2.
The student layers are initilized by copying one out of two layers of the teacher, starting with layer 0.
The head of the teacher is also copied.
"""
# Get teacher configuration as a dictionnary
configuration = teacher_model.config.to_dict()
# Half the number of hidden layer
configuration['num_hidden_layers'] //= 2
# Convert the dictionnary to the student configuration
configuration = RobertaConfig.from_dict(configuration)
# Create uninitialized student model
student_model = type(teacher_model)(configuration)
# Initialize the student's weights
distill_roberta_weights(teacher=teacher_model, student=student_model)
# Return the student model
return student_model当然,这个函数引入了一个缺失的部分 distill_roberta_weights ,该函数会将教师模型权重的一半置于学生层中,但我们仍然需要对其进行编码。 由于递归对于探索教师模型效果很好,因此我们可以使用相同的想法来探索和复制其中的部分内容。 我们将同时浏览教师模型和学生模型,同时将部分内容从一个模型复制到另一个模型。 唯一的技巧是要小心隐藏层部分并只复制一半。实现代码如下:
from transformers.models.roberta.modeling_roberta import RobertaEncoder, RobertaModel
from torch.nn import Module
def distill_roberta_weights(
teacher : Module,
student : Module,
) -> None:
"""
Recursively copies the weights of the (teacher) to the (student).
This function is meant to be first called on a RobertaFor... model, but is then called on every children of that model recursively.
The only part that's not fully copied is the encoder, of which only half is copied.
"""
# If the part is an entire RoBERTa model or a RobertaFor..., unpack and iterate
if isinstance(teacher, RobertaModel) or type(teacher).__name__.startswith('RobertaFor'):
for teacher_part, student_part in zip(teacher.children(), student.children()):
distill_roberta_weights(teacher_part, student_part)
# Else if the part is an encoder, copy one out of every layer
elif isinstance(teacher, RobertaEncoder):
teacher_encoding_layers = [layer for layer in next(teacher.children())]
student_encoding_layers = [layer for layer in next(student.children())]
for i in range(len(student_encoding_layers)):
student_encoding_layers[i].load_state_dict(teacher_encoding_layers[2*i].state_dict())
# Else the part is a head or something else, copy the state_dict
else:
student.load_state_dict(teacher.state_dict())该函数通过递归和类型检查,确保学生模型与教师模型相同,对于 Roberta 层来说是安全的。 可以注意到,如果我们想在初始化教师模型时更改复制哪些层,则只有编码器部分中的 for 循环需要更改。
现在我们有了学生模型,我们需要训练它。 除了要使用的损失函数之外,这部分相对简单。
2、自定义损失函数
作为对 DistilBERT 训练过程的回顾,我们可以看下图:

我们将把注意力转向那个写着 LOSS 的红色大盒子。 但在揭示里面有什么之前,我们需要知道如何收集我们要喂它的东西。 从这张图中,我们可以看到我们需要三样东西:标签、学生模型和教师模型的嵌入。 标签,我们已经有了,否则,我们可能会遇到更大的问题。 现在让我们得到另外两个。
2.1 检索教师和学生的输入
在这里,我们将坚持我们的示例并使用带有分类头的 RoBERTa 来说明这部分。 我们需要的是一个函数,给定类似 BERT 模型的输入,即两个张量( input_ids 和 Attention_mask)以及模型本身,将返回该模型的输出 logits。
由于我们使用的是 Hugging Face,所以这非常简单,我们唯一需要的知识就是看哪里。
from torch import Tensor
def get_logits(
model : RobertaPreTrainedModel,
input_ids : Tensor,
attention_mask : Tensor,
) -> Tensor:
"""
Given a RoBERTa (model) for classification and the couple of (input_ids) and (attention_mask),
returns the logits corresponding to the prediction.
"""
return model.classifier(
model.roberta(input_ids, attention_mask)[0]
)我们为学生模型和老师模型都执行这个操作,第一个有梯度,第二个没有梯度。
2.2 损失函数计算
如果损失函数有点不透明,我们建议你返回第一篇文章来阅读损失函数。 但是,如果没有时间这样做,下图应该会有所帮助:
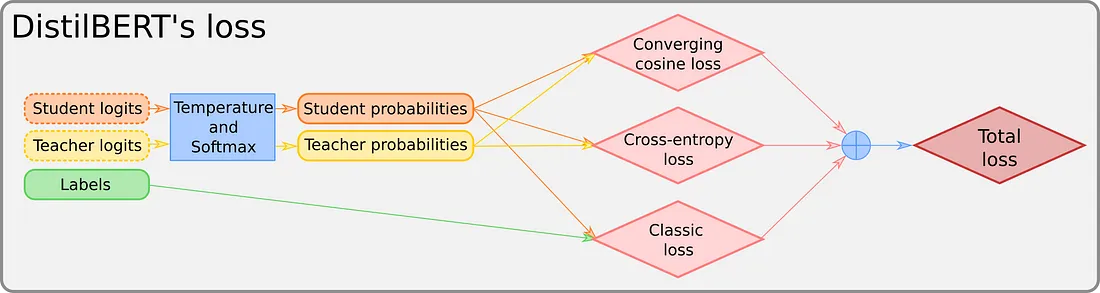
我们所说的 Converging consine loss(收敛余弦损失)是用于对齐两个输入向量的常规余弦损失。 有关更多信息,请参阅该系列的第一部分。 这是代码:
import torch
from torch.nn import CrossEntropyLoss, CosineEmbeddingLoss
def distillation_loss(
teacher_logits : Tensor,
student_logits : Tensor,
labels : Tensor,
temperature : float = 1.0,
) -> Tensor:
"""
The distillation loss for distilating a BERT-like model.
The loss takes the (teacher_logits), (student_logits) and (labels) for various losses.
The (temperature) can be given, otherwise it's set to 1 by default.
"""
# Temperature and sotfmax
student_logits, teacher_logits = (student_logits / temperature).softmax(1), (teacher_logits / temperature).softmax(1)
# Classification loss (problem-specific loss)
loss = CrossEntropyLoss()(student_logits, labels)
# CrossEntropy teacher-student loss
loss = loss + CrossEntropyLoss()(student_logits, teacher_logits)
# Cosine loss
loss = loss + CosineEmbeddingLoss()(teacher_logits, student_logits, torch.ones(teacher_logits.size()[0]))
# Average the loss and return it
loss = loss / 3
return loss3、更优雅的实现
我希望你不会对 Python 是一种面向对象的编程语言感到震惊。 因此,由于所有这些函数都使用几乎相同的对象,因此不让它们成为类的一部分似乎很奇怪。 如果你想实现这一点,我建议使用 Distillator 类来整理代码,就像这个gist 。 我们不会嵌入这个,因为它很长。
当然,缺少一些东西,比如 GPU 支持、整个训练例程等。但是 DistilBERT 的所有关键思想都可以在那里找到。
4、蒸馏结果
那么以这种方式提炼出来的模型最终表现如何呢? 对于DistilBERT,可以阅读原论文。 对于 RoBERTa,Hugging Face 上已经存在类似 DistilBERT 的精简版本,就在这里。 在 GLUE 基准测试 上,我们可以比较这两个模型:
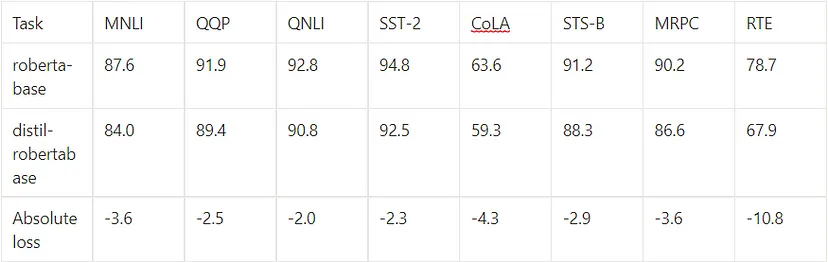
至于时间和内存成本,该模型的大小大约是 roberta-base 的三分之二,速度是 roberta-base 的两倍。
5、结束语
通过本系列文章,你应该拥有足够的知识来提炼遇到的任何类似 BERT 的模型。 但为什么要停在那里呢? 大自然充满了蒸馏方法,例如 TinyBERT 或 MobileBERT。 如果你认为其中一个更适合你的需求,那么应该阅读这些文章。 谁知道呢,你可能想尝试一种新的蒸馏方法,因为这是一个日益发展的领域。
原文链接:Distillation of BERT-like models: the code
BimAnt翻译整理,转载请标明出处





