
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
在本文中,我将讨论如何使用虚幻引擎、强化学习和免费的机器学习插件 MindMaker 在 AI 角色中生成涌现行为。 目的是感兴趣的读者可以使用它作为在他们自己的游戏项目或具体的 AI 角色中创建涌现行为的指南。
1、涌现行为:What & Why?
首先介绍一些关于涌现行为的入门知识。
涌现行为是指未预先编程但响应某些环境刺激而有机发展的行为。 涌现行为对于许多(如果不是所有)生命形式来说是常见的,它是进化本身的一个功能。 这也是最近体现的人工代理的一个特征。
当采用涌现行为方法时,并不是严格地为 AI 编写特定的动作,而是让它们通过一些自适应算法“进化”,例如遗传编程、强化学习或蒙特卡洛方法。 在这样的设置中——行为不是在一开始就被预测到的,而是允许基于一系列在某种程度上依赖于机会的级联事件而“出现”。
为什么会选择使用涌现行为? 主要原因之一是涌现行为方法可以创建行为更类似于碳基生命形式的 AI 代理,更不可预测,并显示出更大的战略行为多样性。
为娱乐或人类互动而设计的各种具体化 AI 代理可以从突发行为中受益,从而显得不那么静态,对用户更具吸引力。 《自然》杂志最近的一篇期刊文章表明,机器人在响应时间和运动模式方面表现出更多的可变性,被认为更人性化。
涌现行为还可以克服使用传统编程方法创建的其他形式的人工智能无法克服的障碍。 通过允许 AI 发现开发人员未预见到的解决方案,代理可以探索比传统编程方法可能实现的更广泛的解决方案空间。 甚至有可能出现的行为方法可能会导致通用人工智能的产生,这是一种可以与人类所拥有技能的多样性相媲美的人工智能。
但是,并非所有情况下都适合使用涌现行为方法,如果想要创建非常具体的行为,例如精确和重复地模仿特定动物的行为,涌现行为技术可能不是最佳选择。 涌现行为不太适合不需要变化的重复性高保真任务。 这就是为什么人类和其他有机生命形式可能难以完成高度重复的任务的原因之一,我们天生就是多变的。
此外,在尝试复制特定行为时,可能很难重现导致该行为模式出现在现实世界中的相同偶然事件。 例如,可能有多种解决方案是某种生物适应或行为进化来实现的,其结果受偶然事件的调节。 因此,并非所有紧急方法都必然会得出相同的解决方案。 一个例子是趋同进化多次重现眼睛的方式,但不一定具有完全相同的形式。
涌现行为方法有利于创造多种行为,其中一些行为可能与真实动物的行为相似,但不太可能完全相同。 另一方面,可以预期使用这些方法会产生大量有趣且独特的行为。 例如,我们可以看看强化学习代理发现的穿越地形景观的各种运动方法。

创建涌现行为的第一步是决定要使哪种行为涌现以及该行为的目标是什么。 这在某种意义上是容易的部分。 下一部分稍微复杂一些,需要概述一些关于涌现的理论。
2、不同类型的涌现行为
当谈到涌现的主题时,开放式涌现和静态或“固定点”涌现之间存在区别。
在不动点涌现中,一开始可能会出现多种行为,但它们会逐渐收敛到一个单一的解决方案或策略,并且出现的数量会随着时间的推移而减少。 本质上,当使用行为来解决的问题存在静态全局解决方案时,就会发生这种情况。 考虑井字游戏:虽然采用强化学习或遗传算法等新兴技术的 AI 最初可能会在井字游戏中显示多种策略,但它会很快收敛到单一的主导解决方案 游戏。 此时不会出现进一步的出现或策略。
当我谈到涌现行为时,我相信人们在接近这个话题时通常会想到“开放式涌现”。 在这种涌现形式中,没有固定的解决方案,代理将不断地产生新的行为。 创建这种开放式涌现可能比创建固定点涌现更复杂,并且必须考虑创建它所必需的结构。
值得庆幸的是,最近在理解和开放式涌现编程方面取得了一些进展,特别是 Joel Liebo 和其他人在自动课程方面所做的工作。 在一篇开创性的论文“Autocurricula and the Emergence of Innovation from Social Interaction”中,作者列出了一些可以预期开放式涌现发生的条件。 下面的表格将有助于理解什么时候可以期待开放式涌现。
3、开放式涌现的秘诀
如果为行为或目标设定的解决方案非常大,因此,就所有意图和目的而言,涌现的数量在所检查的时间段内不会出现上限。 这不是真正的开放式涌现,因为可能存在全局解决方案,如果给定足够的时间,代理将发现并停止适应。
然而,在许多情况下,这可能会超出人类生命的时间跨度,因此从观察者的角度来看,涌现将是开放式的。 一个例子可能是国际象棋游戏,其中全局解决方案被认为存在于井字游戏中,但由于游戏的复杂性,这尚未被发现并且不太可能在我们有生之年被发现。
创造开放式涌现的另一个秘诀是采用依赖于不断变化的环境的行为或目标状态。 想一想地球上的碳基生命形式——由于行星气候条件,环境不断变化,确保动物必须始终适应才能生存,并且涌现水平没有上限。
开放式涌现的第三个秘诀是多代理场景,其中涉及合作或竞争,代理正在采用一些自适应学习策略。 在这种情况下,代理人必须适应其同伴或竞争对手的策略,这反过来又确保另一个人也必须适应,从而形成持续适应的反馈循环,一种进化军备竞赛。 虽然这可能导致出现,但它也可能导致重复行为的循环,无限循环,直到环境中的某些元素将它们推离循环。 它不是真正的均衡,因为行为或策略不是固定的,但循环本身变成了一种均衡。 确保环境足够复杂和动态是避免这些周期性行为或策略的一种方法。
4、开放式涌现演示
在以下使用虚幻引擎创建的示例中,我选择使用上面列出的第三个配方,一个涉及来自两个虚拟物种的种群的多代理场景。 我们称其中一只为犀牛,另一只为老虎。 两组探索他们的环境寻找“浆果”,它们在虚幻引擎游戏环境中以大型圆形物体的形式出现。
使事情变得更复杂的是,这些浆果斑块上随机分布着野鸟,它们可以尖叫,吓跑老虎和犀牛。 然而,如果一只老虎或犀牛与另一只个体组队一起接近浆果,它们就会吓得鸟儿安静下来。 他们现在可以获取浆果,但他们必须将浆果彼此分开。
除了这种合作行为之外,它们还有一种竞争行为,它们可以发出吼叫声(老虎)或开始跺脚(犀牛),吓跑对立物种的代理人,但也会消耗自己宝贵的能量。 在许多方面,这种情况复制了自然界中的动物和人类公司可用的一些合作和竞争权衡。
竞争或合作是最古老的问题之一,通过在虚拟代理中模拟这一点,我们可以深入了解导致各种竞争或合作结果的条件。 使用这样的虚拟代理,我们还可以产生许多与在动物王国甚至人类中可能观察到的相同的行为复杂性。 OpenAI 小组最近发表的一篇论文能够证明工具使用的涌现是玩捉迷藏游戏的 AI 角色之间多代理竞争的函数。
可以对任何自适应虚拟代理群体进行类似的操作,这些虚拟代理将在彼此之间玩游戏,其中收益取决于其他玩家的策略,并且环境会受到他们行为的影响。 目标可以是任何东西,只是代理必须有一些方法来接收有关其环境的反馈,包括竞争对手采取的行动以及改变自己的行动作为回应的能力。 这个目标是由玩家还是程序员设定的,在复杂性方面没有太大区别。 选择由玩家设置它可能会带来关于游戏叙事的有趣选项。 需要注意的重要一点——行为的目标是谁来选择并不重要,重要的是这满足了上述竞争或合作的要求。
但是涌现究竟是如何“涌现”的呢? 一种方法是使用强化学习或遗传算法。 在我们的例子中,我们有一群虚拟代理,它们使用随机变化的行为来查看目标状态是否受到影响。 代理然后优先考虑那些导致良好结果的行为。 在遗传算法中,这是通过种群中出现的一种交叉函数来完成的,其中随机出现的良好适应性得到保留,相对不太有用的适应性被丢弃。 这是由适应度函数决定的。 这不需要看起来像有性繁殖或任何类似的东西,因为现有的代理可以被它们适应的对应物无缝替换,而用户不会看到任何正在发生的交叉。 在我们的示例中,我们将使用强化学习,这是我在另一系列文章中广泛介绍的一种算法技术。
与遗传算法类似,强化学习依赖于大数法则,即给定足够多的随机行为,就会出现好的动作,并可以在未来优先考虑。 最初,智能体选择一系列随机动作,但如果它们导致智能体获得奖励,则该奖励的价值将归因于智能体为获得奖励而采取的动作,因此更有可能在未来重复这些动作 . 当这个随机动作的过程被充分重复时,那些与代理人获得奖励有因果关系的动作将与那些仅仅是偶然事件的动作区分开来。 这就是强化学习的核心所在,它是一种因果算法,可用于检测因果关系。
人们可以像这样想象这个过程。
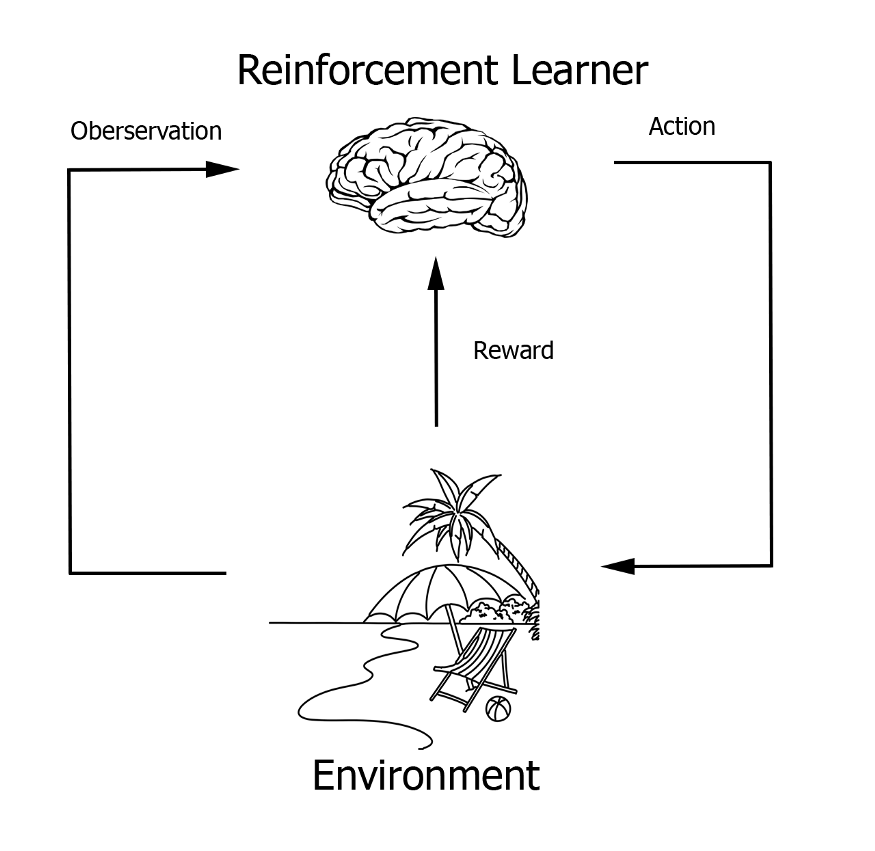
对于这个项目,我使用了免费的 MindMaker 插件和 Stable Baselines 强化学习算法套件。 借助 MindMaker,我们可以使用 OpenAI Gym 格式轻松地在 Unreal Engine 游戏环境中部署各种 RL 算法。 这为在各种模拟环境中部署强化学习算法提供了一个通用结构。
5、总结与未来发展
上述简单设置导致不同数字物种的行为不太可能达到稳定平衡的情况。 鸟类在浆果斑块上的随机分布确保环境始终在变化,这反过来又不断改变代理人合作或竞争的潜在利益。 智能体本身的活动也会影响有鸟和没有鸟的浆果斑块的比例——随着更多的智能体相互合作,合作的动机就会减少,因为没有鸟的浆果斑块的比例会增加。
这个想法是,这些相互作用的力量创造了一个总是波动和不稳定的环境,推动战略适应。 鉴于我们的代理与环境互动的方式很少——他们无法诱捕他们的竞争或使用环境中的物体隐藏浆果,我们的范例不太可能产生像涌现工具使用这样有趣的东西。 然而,它确实避免了固定均衡,并创造了不断变化的合作和竞争策略组合。 这可以提供一组比通常出现在开放世界视频游戏中更有趣的行为。
因此,我相信涌现行为技术(例如此处概述的技术)很可能会主导下一代视频游戏 AI,从而创造出更加有趣和诱人的角色和行为库。
原文链接:Creating Emergent Behaviors with Reinforcement Learning and Unreal Engine
BBimAnt翻译整理,转载请标明出处





