
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
今年早些时候,我与 Cognizant 深度学习协会团队的一位经理进行了交谈。 他的团队使用深度学习算法创建概念验证(展示商业机会的试点项目)。 他注意到他的团队面临的主要挑战之一是获取此类 POC 的数据。 获取特定于某个问题的具有良好代表性的数据是很困难的。 此外,在大多数情况下,利用真实世界的数据来测试系统是否提供所需的输出是不可能的,因为它会带来隐私相关的问题。 当我们结束谈话时,他表示一个可能的解决方案是生成合成数据(Synthetic Data),并且他的团队已经开始研究它。 这次谈话是我对“合成数据”的介绍。
在我处理AI模型的两年里,我对输入这些模型的数据的关注从未超出过数据增强过程。 最常见的是,在等式中,AI系统 = 模型 + 数据,我们保持数据不变并继续调整参数以提高模型性能。 吴恩达 (Andrew Ng) 最近在 LinkedIn 上发帖称,他正在考虑组织竞赛,我们采用流行的架构并保持不变,并要求团队处理数据——试图刺激以数据为中心的人工智能开发。
大多数时候,架构并不像数据集那么重要,拥有高质量、有代表性的数据集始终是一项不错的投资,在大多数情况下可能比升级到最新的检测器更重要。
— 约瑟夫·纳尔逊,联合创始人/首席执行官@ Roboflow
从我的研究中,我意识到缺乏高质量的、正确标注的数据实际上是世界各地AI团队面临的最大挑战,它阻碍了深度学习充分发挥其潜力。
我相信读者可以利用这篇文章作为了解计算机视觉合成数据生成(SDG-CV)领域的窗口。 SDG-CV 上有很多资源,但由于该领域最近变得流行,你可能会迷失方向。 在本文中,我尝试写下我对合成数据生成及其用例的理解。
1、计算机视觉任务中的合成数据
合成数据是通过计算机程序生成的数据。 这些程序可以是生成式深度学习算法(GAN、VAE、自回归模型)或生成 3D 模拟的 CGI 和游戏引擎(Unreal、Unity、Blender 等)。 计算机视觉的合成数据可以是 RGB 图像、分割图、深度图像、立体对、LiDAR 或红外图像。

为了构建强大的、高性能的深度学习模型,你需要大量带标注的数据。 你会惊讶地发现,在大多数情况下,这些模型不需要真实的训练图像即可表现良好。 与真实感相比,他们更喜欢数据的多样性,尤其是在物体检测方面。 然而,分割任务需要高度的纹理真实感,因为分割模型严重依赖纹理。
下面的一些示例将说明为什么采用合成数据是有益的。
2、合成数据使用示例
假设你对每年在地球上乱扔大量塑料瓶感到苦恼。 因此,你决定训练机器人来检测塑料瓶。 现在,这些瓶子可以以数千种不同的方式破碎。 收集瓶子的图片并对其进行注释不仅是一项乏味的任务,而且使用这样的数据集训练模型并不能涵盖所有可能的场景。 然而,它太贵了。 这些瓶子可以出现在不同的地形、不同的光照条件下,并放置在各种其他物体旁边。 更简单的替代方案是使用任何图形引擎(即 Unreal、Unity 或 Blender)合成数千个假的皱巴巴的瓶子图像。
让我们看看一个棘手的问题,合成数据可以解决这个问题—例如,自动驾驶汽车经过训练可以发现道路上的其他汽车。 显然,此类系统已经接受过大量汽车图像的训练,并且它们在识别汽车方面可能非常准确。 但它会检测到翻转的汽车吗? (这是我从 Immersive Limit 得到的一个有趣的例子。) 在现实世界中拍摄数千张翻转汽车的图像是不切实际的。 然而,通过使用任何 3D 渲染软件,我们可以合成任意数量的具有多种变化的翻转汽车。
3、合成数据与增强图像有何不同?
当我最初开始阅读有关合成数据的内容时,我脑海中浮现出一个疑问:合成数据的好处是否可以通过数据增强来实现。 好吧,这就是答案。
数据增强(Data Augmentation)是深度学习和计算机视觉工程师广泛使用的一项技术,通过将图像旋转几度、放大一点或翻转图像来修改真实数据。 该技术创建了数据集中现有图像的变体,并且可以被视为生成更多标记数据的廉价替代方案。

但是,如果我们的目标对象出现在不同的背景、不同的光照条件或不同的上下文中,如图(2c)所示,该怎么办?
在这种情况下,合成数据占据上风。 另一个例子是,假设你正在训练无人机系统来监控高尔夫球场的维护情况。 在这种情况下,你的训练数据是草地图像,数据增强几乎没有任何用处。 此外,在某一天,照明可能会根据天气和一天中的时间而有所不同。 使用 3D 场景渲染软件,你可以模拟虚拟高尔夫球场并提取训练图像。 这绝对不像听起来那么容易,但这是一项一次性投资,可以在未来为你节省大量金钱和时间。
4、生成合成数据
如前所述,合成数据可以通过两种方法生成:
4.1 基于深度学习的合成数据生成
基于深度学习可以采取两种方法:
- 使用生成对抗网络
在 GAN 模型中,我们创建了一个生成模型,该模型采用随机样本数据并生成与真实数据非常相似的合成数据。 判别器根据之前设置的条件将综合生成的数据与真实数据集进行比较。
- 使用变分自编码器
在VAE模型中,编码器将真实数据集压缩成紧凑的形式并将其传输到解码器。 然后解码器生成一个输出,它是真实数据集的表示。 通过优化输入和输出数据之间的相关性来训练系统。
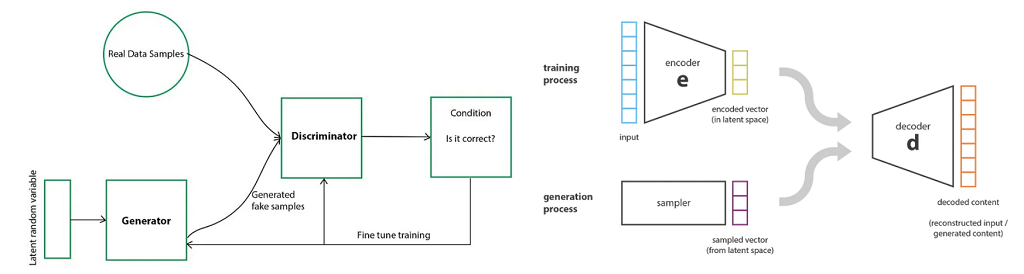
4.2 基于3D渲染的合成数据生成
基于 3D 渲染的 SD 生成的基本工作流程相当简单:
准备并按程序生成对象的 3D 模型,将它们放置在模拟场景中,设置环境(相机视点、照明等)并渲染合成图像以进行训练。 基本上,创建一个逼真的虚拟世界并提取它们的图像。 当你拥有 3D 渲染的合成数据时,3D 渲染器还可以自动进行标注。
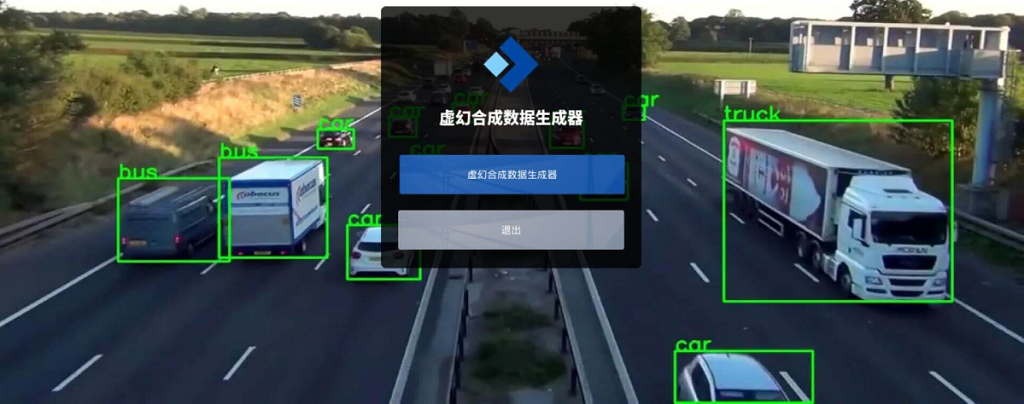
一个最典型的例子是UnrealSynth,这是一个基于UE5开发的YOLO合成数据生成器,只需要将3D模型导入进去,就可以自动生成训练数据集,非常方便:
在接触一些合成数据初创公司和公司时,我发现他们中的大多数依赖基于 CGI 或 3D 渲染的方法来生成合成数据。 避免使用基于深度学习的方法的原因很容易猜到:首先,优化 GAN 并不容易。
其次,GAN 存在模式崩溃的问题。 这意味着你的发生器崩溃,产生的样本种类有限,即。 仅生成少数类别的数据。 这是不希望的。 毕竟,将多样性和极端情况引入训练是使用合成数据集的整体理念。 然而,这些公司更多地使用对抗网络来进行领域适应。
5、合成数据的必要性
以下是必须采用合成数据进行训练和测试的几个原因:
- 合成数据减轻了数据集偏差。 这对于人脸识别等与人类相关的计算机视觉任务尤其重要。
- 合成数据能够覆盖实际数据捕获不可行的情况下的极端情况。 很多时候,真实的数据集不够多样化。 综合数据包含更多用例和模式。 这样你的模型就可以处理很少发生的关键情况。
- 数据收集和标记是一项费力、昂贵且耗时的任务(例如:面部关键点检测的注释)。 你可以为数据集实现自动像素完美标记。 这可以为你节省大量时间并加快产品的上市时间。
- 它解决了使真实数据的使用变得不可能或极其困难的隐私或法律问题。 例如在医疗和金融应用中。
- 在渲染级别,合成数据生成可以随机化照明条件、相机视点、对象的方向、更改图像分辨率等。
6、结束语
以下是我个人认为在机器视觉训练合成数据方面做出了一些令人印象深刻的工作的几家初创公司和公司:AI Reverie、Chooch AI、Datagen、Parallel Domain、Neurolabs、Synthesis AI、Zumo Labs 。
可以在此处查看合成数据公司的完整列表。 我还没有机会观看名单上所有公司的演示。 如果你有兴趣,请查看一下。
原文链接:Synthetic Data for Computer Vision: Have you given it a thought?
BimAnt翻译整理,转载请标明出处





