
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
理解、预测并最终减少城市路网中的交通拥堵是一个复杂的问题。即使了解最简单的单车道情况下出现的交通拥堵, 也是具有挑战性的。SUMO是一个开源平台,可模拟复杂环境中的交通流。在这个教程里,我们将学习如何从零创建复杂的交通流模拟,使用网格上的流量案例研究来做这方面的工作,教程结构如下:
- 为什么要研究交通网络中的流量?
- 从SUMO开始
- 仿真网格网络中的交通流
- 关键流量性能指标分析
- 仿真现实交通的未来方向
1、为什么要研究交通网络中的流量?
在之前的一篇文章中,我讨论了第一篇论文,该论文最终展示了交通"幻象"冲击波是如何从无到有地产生的,除了驾驶员的互动。

最近的研究表明,简化自动驾驶车辆之间的交互可能会减少人为场景(如绕圈行驶的车辆)的交通堵塞。但是,当你有多条路时会发生什么,就像在典型的城市道路网中一样?有趣的是,仅仅通过更多的车道或更长的道路增加容量可能不会符合拟的预期。在另一篇文章中我展示了"Braess悖论"如何导致不寻常的结果,即增加城市网络中的道路数量,反而可能会使交通恶化!
在进行基建工程,例如兴建新道路、增加车道、红绿灯等前,必须实事求是地仿真交通流量,使项目有最好的机会成功缓解交通。将音乐会、体育赛事等重大活动或机场和医院等公共建筑纳入场景时,情况变得更加复杂。在不远的将来,重要的是要仿真网联车辆和智能交通技术创新的影响,以最好地发挥其在简化交通流量方面的潜力。
2、从SUMO开始
交通仿真似乎属于交通流研究人员或工程承包公司的细分社区。例如,Anylogic、VISSIM和Aimsun是提供交通流建模解决方案的公司。 但是,SUMO 是公开的,并且很容易上手。
有多种方法来安装SUMO,但我更喜欢使用pip安装SUMO以及Python库,以便与SUMO交互。
python -m pip install sumo就是这样!现在,让我们开始创建交通流量的首次仿真!
3、仿真网格中的交通流
在城市规划中,网格相当普遍。在 SUMO 中,我们设置了一个 5x5 网格,每条道路长度为 200 米,并设置了 3 条车道,如下所示:
netgenerate — grid — grid.number=5 -L=3 — grid.length=200 — output-file=grid.net.xml接下来,我们使用位于SUMO主目录(sumo->tools)中的tools文件夹中的 randomTrips.py,为一定数量(示例中使用 200 辆车)的车辆生成随机行程。开始和结束时间表示车辆进入仿真的时间。我选择了 0&1,这意味着所有车辆在仿真的前 1 秒进入仿真。Period表示车辆的到达率。
randomTrips.py -n grid.net.xml -o flows.xml — begin 0 — end 1 — period 1 — flows 200接下来,我们使用 SUMO 的 jtrrouter 生成单个车辆的路线,时间从 0 到 10000。
jtrrouter — flow-files=flows.xml — net-file=grid.net.xml — output-file=grid.rou.xml — begin 0 — end 10000 — accept-all-destinations最后,为简单起见,我们希望保持恒定的车辆密度。最显而易见的方法是车辆随机驾驶,而不是退出仿真。为此,我们使用曼哈顿交通模型,在曼哈顿交通模型中,遇到交叉路口的车辆会根据设定的概率选择直行、左路或右行。在 SUMO 中默认情况下,车辆一旦到达目的地就退出仿真。但是,SUMO也有曼哈顿模型的实现,使用连续变道Python脚本。
generateContinuousRerouters.py -n grid.net.xml — end 10000 -o rerouter.add.xml接下来,我们创建一个SUMO配置文件,以便在 SUMO 中运行仿真,该文件是具有某些属性的.xml文件,包含网络文件的名称、路由文件和其他变道文件,供车辆在仿真中停留,直到仿真完成。我们定义输出文件,以便在交通仿真期间存储详细的车辆信息。
<configuration>
<input>
<net-file value=”grid.net.xml”/>
<route-files value=”grid.rou.xml”/>
<additional-files value=”rerouter.add.xml”/>
</input>
<time>
<begin value=”0"/>
<end value=”10000"/>
</time>
<output>
<fcd-output value=”grid.output.xml”/>
</output>
</configuration>最后,我们将在终端中运行如下仿真。Peroid表示保存数据的时间间隔 - 100 表示每 100 个时间步保存车辆信息,即速度和位置。
sumo-gui -c grid.sumocfg — device.fcd.period 100运行上面命令将弹出 SUMO GUI,你可以看到仿真:

车辆颜色表示其速度从最慢(红色)到最快(绿色)。
4、多次运行交通仿真
手动更改参数并输出文件是相当烦人的。如果你要运行100+次仿真探索不同的参数,如车辆数量,交通是如何变化的,然后的多个运行的统计平均。
为此,我使用操OS模块在命令提示上与python交互:
def initialize(grids=5,lanes=3,length=200):
os.system("netgenerate --grid --grid.number=5 -L="+str(lanes)+" --grid.length="+str(length)+" --output-file=grid.net.xml")
def single(path,vehicles):
os.system(path + "randomTrips.py -n grid.net.xml -o flows.xml --begin 0 --end 1 --period 1 --flows "+str(vehicles))
os.system("jtrrouter --flow-files=flows.xml --net-file=grid.net.xml --output-file=grid.rou.xml --begin 0 --end 10000 --accept-all-destinations")
os.system(path + "generateContinuousRerouters.py -n grid.net.xml --end 10000 -o rerouter.add.xml")
tree = ET.parse("grid.sumocfg")
root = tree.getroot()
for child in root:
if (child.tag == 'output'):
for child2 in child:
child2.attrib['value'] = 'grid.output'+str(vehicles)+'.xml'
with open('grid.sumocfg', 'wb') as f:
tree.write(f)
os.system("sumo -c grid.sumocfg --device.fcd.period 100")
if __name__ == '__main__':
import os
import numpy as np
import analysis
from matplotlib import pyplot as plt
import xml.etree.ElementTree as ET
path = "C:\\Users\\BLAH\\AppData\\Local\\Programs\\Python\\Python39\\Lib\\site-packages\\sumo\\tools\\"
initialize()
vehicles_arr=np.r_[np.linspace(10,100,10).astype(int),np.linspace(100,2000,20).astype(int)]
for i in range(0,len(vehicles_arr)):
single(path,vehicles_arr[i])5、分析
SUMO xml 输出包含每个时间步的单个车辆时间、位置和速度的信息。我希望分析速度是如何依赖车辆密度,或仿真中的车辆数量 - 基本上在每一个时间步获得速度,然后在仿真的所有车辆上进行平均。
def textify(vehicles):
tree = ET.parse("grid.output"+str(vehicles)+".xml")
root = tree.getroot()
l = 0
for child in root:
for child2 in child:
l += 1
c = 0
t = 0
a = ''
speeds = np.zeros(l)
times = np.zeros(l)
ids = np.zeros(l)
for child in root:
for child2 in child:
# print(child2.tag, child2.attrib)
if (child2.tag == 'vehicle'):
a = (child2.attrib)
speeds[c] = np.float(a['speed'])
ids[c] = np.float(a['id'])
times[c] = t
c = c + 1
t = t + 1
# print(t)
data = np.c_[ids, times, speeds]
tt = len(np.unique(data[:, 1]))
vel = np.zeros(tt)
nc = np.zeros(tt)
flux = np.zeros(tt)
for i in range(0, tt):
w = np.where(data[:, 1] == i)
vel[i] = np.mean(data[w, 2])
nc[i] = len(w[0])
flux[i] = np.sum(data[w, 2])
velm = np.c_[nc, vel, flux]
np.savetxt('velm'+str(vehicles)+'.txt',velm)最后,绘制速度 - 密度图,其中每个仿真运行都有单独的密度:
import numpy as np
from matplotlib import pyplot as plt
def plots(vehicles):
vel=np.zeros(len(vehicles))
nc=np.zeros(len(vehicles))
flux=np.zeros(len(vehicles))
for i in range(0,len(vehicles)):
txt=np.loadtxt('velm'+str(vehicles[i])+'.txt')
nc[i] = np.mean(txt[95:100, 0])
vel[i] = np.mean(txt[95:100, 1])
flux[i]=np.mean(txt[95:100,2])
print(nc[i],vel[i],flux[i])
fig=plt.figure()
plt.plot(nc/3000,vel,'o')
plt.plot(nc / 3000, vel, color='k')
plt.xlabel('Density')
plt.ylabel('Velocity')
plt.tight_layout()
plt.savefig('vel-density.png',dpi=600)
#plt.show()
fig=plt.figure()
plt.plot(nc / 3000,flux,'o',label='Traffic Simulation')
plt.plot(nc / 3000, flux, color='k')
plt.plot(vehicles/3000,vehicles*vel[0],'r--',label='No Interaction')
plt.ylim(0,2800)
plt.legend()
plt.xlabel('Density')
plt.ylabel('Flux')
plt.tight_layout()
plt.savefig('flux-density.png', dpi=600)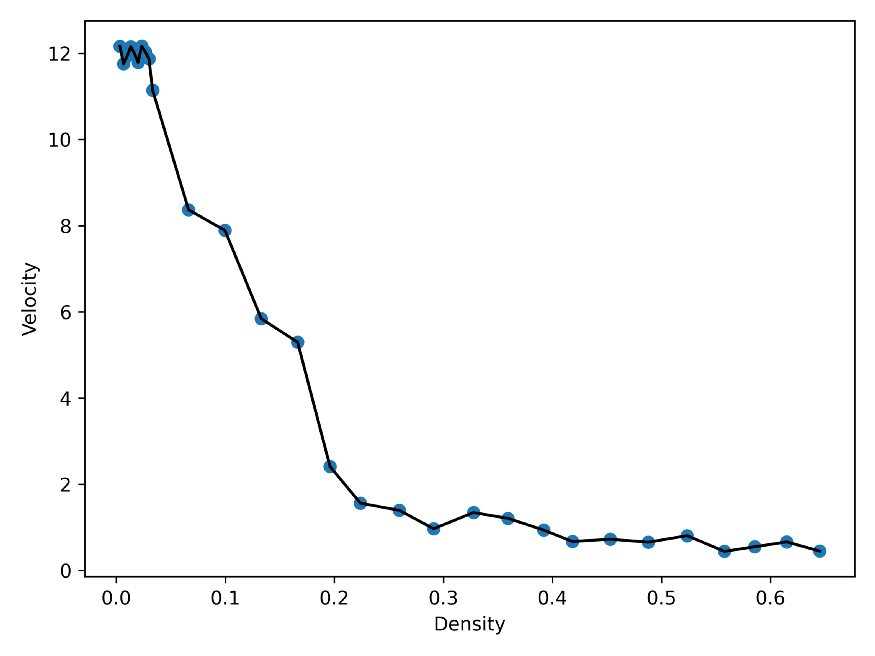
正如你所看到的,随着密度的增加,速度会降低。这是因为仿真中的车辆越多,拥塞越多,导致行驶速度降低。这是我们大家在高速公路上看到的东西,尤其是在高峰时段。
交通仿真中另一个常用的参数是通量。正如我在上一篇文章中所讨论的,通量衡量每次通过给定点的车辆数量,是衡量车辆吞吐量的指标。通量公式为:
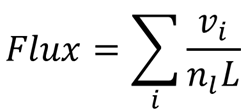
上述公式汇总长度 L 内的所有车辆的速度,以及车道数量 n_l。
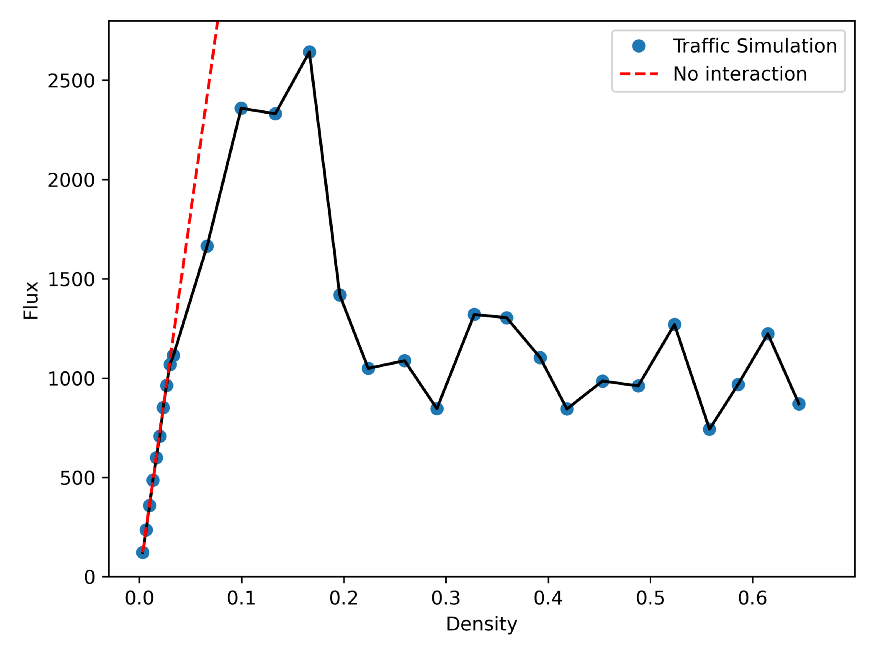
在低密度下,每辆车基本上都是在限速行驶,因此通量会随着密度的直线增加(下面图中的红线)。但是,在密度较高时,车辆不能在限速行驶,在某一点上,以较小的速度行驶的每辆车都会抵消车辆数量较多的影响,从而减少通量。在特征密度(此模拟中为 +0.1= 0.2)之上,会出现交通堵塞,并且通量随着密度降低而减小。
6、仿真真实的交通
我已经演示了如何使用 SUMO+Python 在具有代表性的网格中设置基本的交通仿真和合奏运行。然而,这绝不是对城市交通网络的全面仿真。在最近的一项研究中,利用OpenStreetMap和OSMnx,发现了城市网格的一些特点。SUMO 包括通过将 OpenStreetMap数据转换为 SUMO.net文件来仿真城市街道网络中的流量。
但是,除了现实城市网络上的仿真之外,还有校准这些交通仿真以匹配日常交通模式的问题。为了与日常生活中看到的详细交通模式相匹配,人们需要考虑进入道路的人的起伏,他们何时进入,何时/何地离开。这是一个极其复杂的问题,因为不可能知道每一个车辆的轨迹。现在,许多车辆将 GPS 数据传输给 INRIX 和 HERE这样的公司。Google和Apple等公司利用手机数据来获得稀疏的位置和速度信息。但是,这只能提供整个人口的一小部分信息。交通流是一个高度非线性的问题:这意味着小的变化可能会产生极端的后果。
同时,我们希望交通流仿真结果在不同的初始条件下是可靠的。结果应清楚地表明,对于各种情况,建议的项目是否具有显著的交通流改善。拥有详细的大规模交通仿真是一项挑战,这些仿真在可行的时间内运行,并且是现实的。
在 SUMO 页面上,只有少数这样的现实场景。页面顶部如下文字:
构建一个场景包含很多工作。如果你已经构建了一个 可以共享的SUMO 场景,请与我们联系。
希望交通运动数据的民主化、计算资源的日益可用以及开源交通流建模平台将使这些大型仿真更加容易访问。
原文链接:How To Simulate Traffic On Urban Networks Using SUMO
BimAnt翻译整理,转载请标明出处





