
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
本文旨在解释强化学习方法如何通过 TraCl 与 SUMO 配合使用,以及这如何有利于城市交通管理和自动驾驶车辆的路径优化。
1、SUMO和强化学习概述
SUMO是一款功能强大的交通仿真器,旨在处理大型负载交通网络和指定的交通需求,包括车辆路线和车辆跟随模型。 SUMO还提供了许多有用的信息,例如车辆速度、型号和位置。 SUMO的主要功能之一是交通控制接口(简称TraCI),它是一个Python API,将SUMO仿真视为服务器,允许用户从交通仿真中获取信息,或修改仿真。 TraCI 启用了一个接口,允许第三方系统(或库)与 SUMO 交通模拟集成。
强化学习(RL)作为一种机器学习技术,作为复杂系统的解决方案已经取得了非常有前景的结果。 强化学习方法能够通过与环境本身的交互来获取知识或提高性能。 强化学习的理论受到行为心理学的启发,它在环境中的策略下采取某些行动后获得奖励。 强化学习的目标是根据重复与环境交互所获得的奖励来学习最优策略。 这会持续优化策略并最终创建解决方案。
强化学习在现实世界中应用的一个很好的例子是城市交通管理。 随着城市交通网络中车辆数量的增加,设计智能交通管理系统来为车辆执行智能路由的需求很高。 然而,城市交通网络的复杂性给交通管理带来了诸多挑战,如交通系统的高速变化、道路上车辆的广泛分布等。 为了应对这些挑战,强化学习方法将很有用,因为它已经成功证明它能够处理复杂的优化问题。
2、基于强化学习的城市交通管理
正如我们在本文开头提到的,SUMO 交通仿真器可以使第三方系统实现强化学习。 在这种情况下,TraCI 将扮演 SUMO 和强化学习方法之间“转换器”的角色来建立这种交互。 TraCI 能够检索仿真中的每一条信息,包括车辆和网络。 这为强化学习代理提供了有用的功能来证明环境状态的合理性。 根据对状态的观察,我们可以相应地设置和分配奖励,并让强化学习根据奖励来优化策略。 之后,强化学习代理将通过 TraCI 为 SUMO 分配新的动作,并持续观察环境状态。
TraCI 可以使用多种编程语言进行访问,最常见的语言是 Python。 SUMO模拟器中的工具包/TraCl允许用户使用Python与SUMO交互。 这是有利的,因为 Python 已经是一种成熟的机器学习脚本语言,在实现机器学习算法的同时提供有用的库(例如 Numpy 和 Pandas)。
强化学习代理与环境之间通过 TraCI 的交互将持续进行,直到达到终止状态,或者代理满足终止条件。 本质上,强化学习技术应用马尔可夫决策过程(MDP)。 MDP被定义为五元组 <S,A,T,R,γ>,其中S是状态的集合,A是可以改变状态的动作集合,T是转移函数,即一定动作下状态改变的概率,R是奖励函数,γ被称为折扣因子,它对未来和即时奖励的重要性进行建模。
强化学习通过重复以下步骤来优化其策略:在每个时间步t,强化学习代理从状态集合S中感知状态,并根据其观察,选择一个动作并执行它,以引导环境状态转变为 下一个状态。 然后,代理收到即时奖励 R,观察新状态,并使用上面的方程(包括折扣奖励 γ)更新策略。
总之,强化学习将是复杂城市交通管理问题的理想解决方案,SUMO 模拟器提供了一个良好的界面 (TraCI),用于应用强化学习来运行模拟并学习重新规划车辆路线的最佳策略。 在下面的内容中,我将演示如何使用 TraCI 应用强化学习方法在 SUMO 中重新规划车辆路线。
为了在 SUMO 仿真器中实现强化学习,我们需要 SUMO 中马尔可夫决策过程的相应元素。 SUMO模拟器使用默认路径方法 DuaRouter为仿真中的每辆车生成路径文件。 DuaRouter基于最短路径计算执行动态用户分配(DUA)。 强化学习代理将用它学到的最优策略替换默认路由方法。
3、自动驾驶车辆的路径优化案例
这一部分我们将演示一个简单的交通仿真,该仿真使用 TraCI 在 SUMO 模拟器中应用强化学习方法,旨在演示车辆如何通过选择正确的路径来学习到达目的地以避免交通拥堵。 它还展示了车辆如何根据收到的奖励来优化其路径选择策略。
首先,我们需要准备一个包含道路信息的交通网络文件和一个包含车辆路线信息的路线文件,用于构建模拟环境。
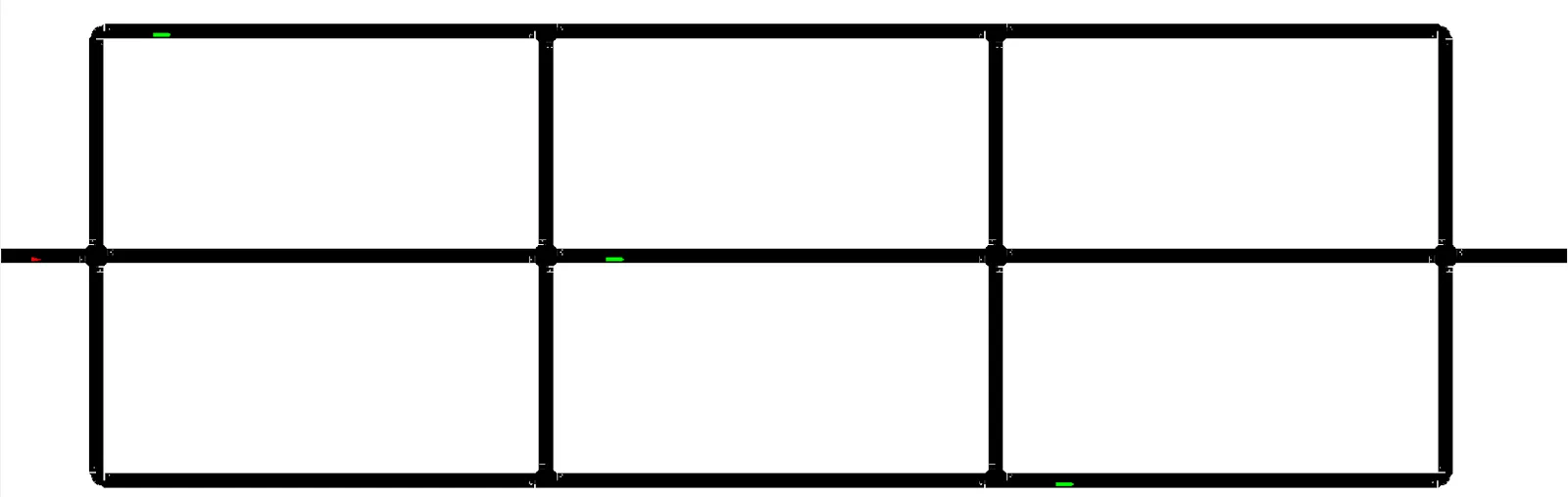
图1所示为由.net文件和.rou文件生成的仿真道路网络。 道路上的三个绿色小矩形是堵塞道路并造成拥堵的卡车。 左边的小三角形是仿真的车辆,其目的地位于网络的右侧。
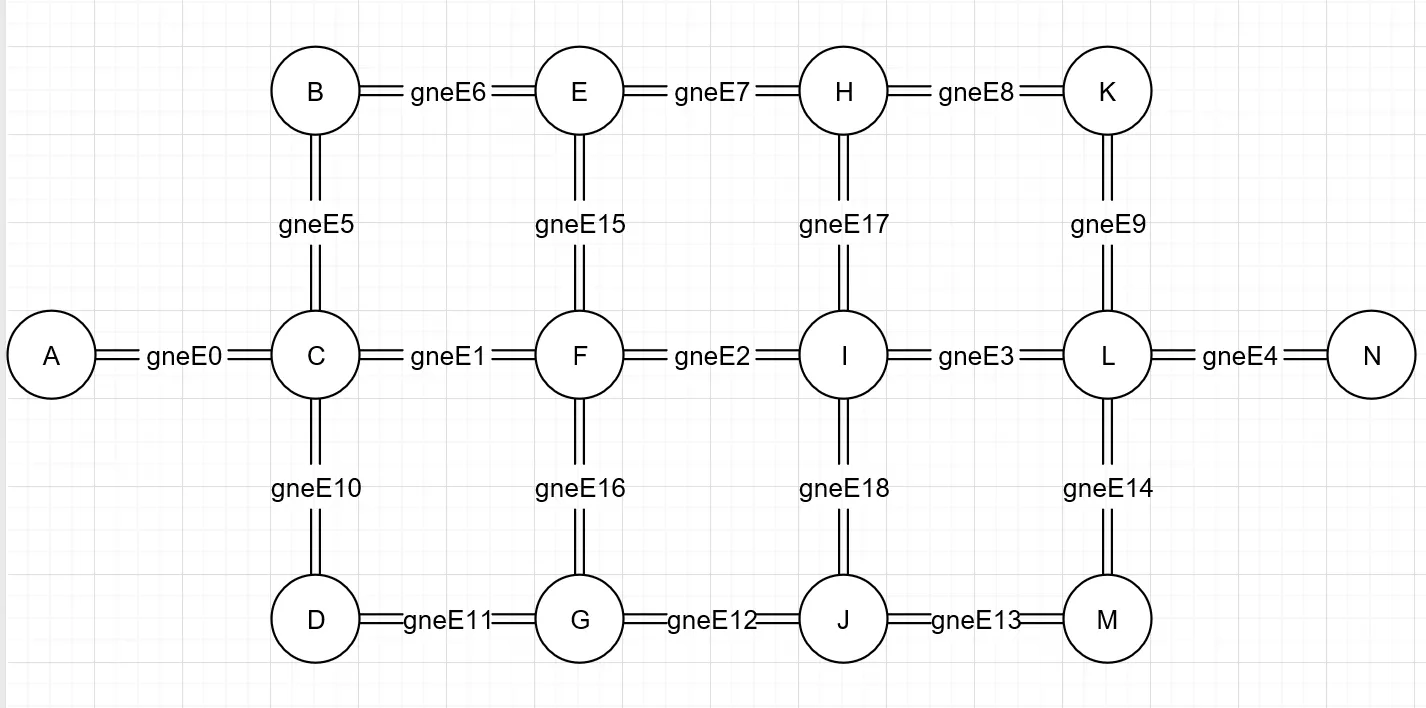
图 2 与图 1 具有相同的网络设计。但是,它显示了连接每个节点的边的 ID,这也表明了车辆将采取的路径。 如果车辆从左到右节点或从上到下节点移动,我们会使用正边 ID 记录车辆采用该路径。 否则(从右到左或从下到上)我们使用负边缘 ID 记录车辆采用该路径。 例如,如果车辆从节点 A -> C -> F -> E -> B -> C 返回节点 A,则所采取的路径将被记录为['gneE0', 'gneE1', '-gneE15'、'-gneE6'、 'gneE5'、 'gneE0']。
下一步,我们使用 TraCI 库控制 SUMO 仿真器,因为连接到该库可以实现强化学习方法。 在这种情况下,将使用 numpy 和 pandas 库。 numpy 库用于支持多维数组和矩阵,以及大量数学函数。 然而,pandas 库是用于数据操作和分析的。 这两个库都广泛用于机器学习。
在开始强化学习之前,我们初始化Q表。 Q表是用于路径选择策略的可更新表。 每次采取行动以优化策略时,表的值都会更新。 该表将记录环境的每个状态以及采取每个动作的概率。 本例的 Q表格式如下所示:

在图 3 中,我们可以将边 ID 设置为带有其三个可用移动得分的阶段。 如果车辆进入Q表中未覆盖的新边,我们将该边ID记录为新记录并将其分配为随机移动,然后根据车辆进入的下一条边更新分数。
我们将学习次数设置为 30,这意味着我们将运行仿真 30 次。 每次仿真都会一直运行,直到左侧的车辆找到到达目的地的路或陷入拥堵。 车辆从边“gneE0”出发,目标到达边“gneE4”并尝试避开拥堵边,即“gneE2”、“gneE6”和“gneE13”。 因此,当车辆到达边缘“gneE4”时给予奖励,而当车辆进入“gneE2”、“gneE6”或“gneE13”时给予惩罚。
强化学习根据 Q表做出动作。 之后,它通过执行该操作来更新有关下一阶段收到的奖励或惩罚的 Q表。 因此,下次它会通过寻找包含更高分数的动作来表现得更“贪婪”。 在这种情况下,我们使用以下算法更新Q 表分数:
q_table.[edge_id, action] +=learning_rate * (q_target — q_predict)其中折扣因子为 0.1,q_target 是我们在下一阶段收到的奖励或惩罚,q_predict 是特定操作的当前分数(最初为 0) )。
运行仿真 30 次后,我们可以看到车辆变得越来越聪明,学会通过避开拥堵路径来到达目的地。 图 4 显示了车辆在每次模拟中所走的总路径:
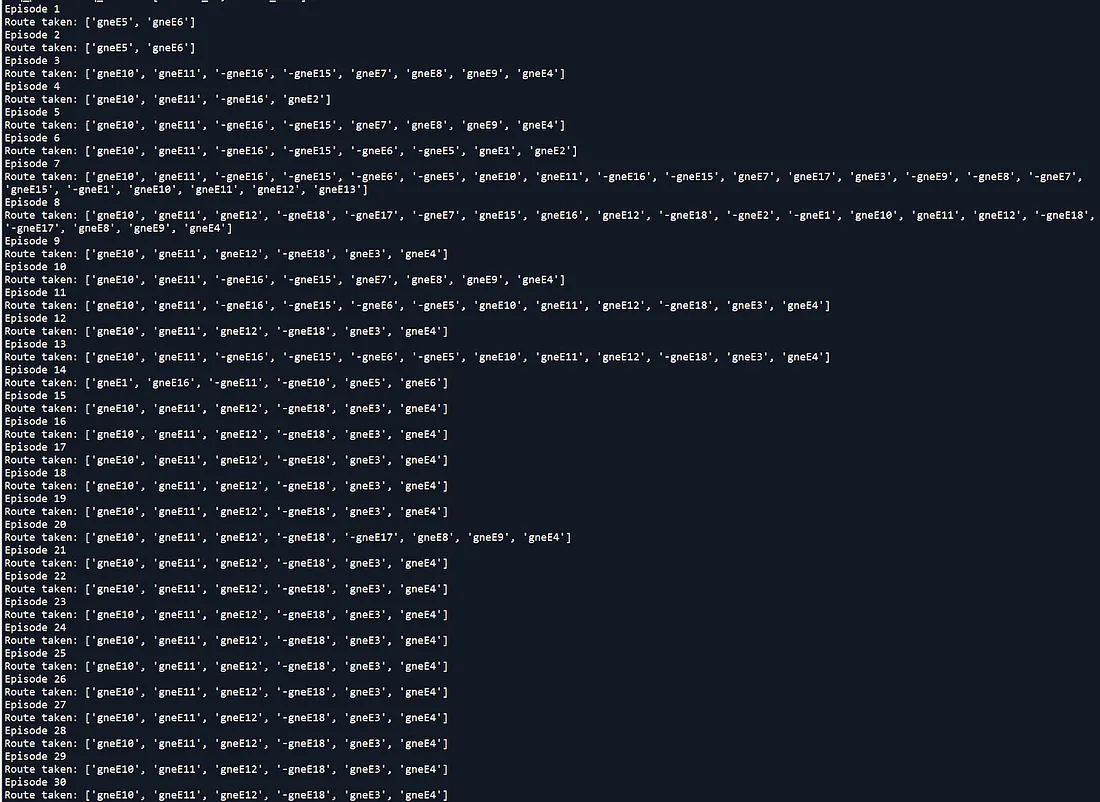
在图 4 中,从第 1 个episode到第 10 个episode,我们可以看到车辆是否进入拥堵路径或采取较长的路径到达目的地。 从第11个episode到第20个episode,它变得越来越聪明,但偶尔仍然会走更长的路。 从第21个episode到第30个episode,始终走最短路径到达目的地,不进入拥堵路径。
4、结束语
在本文中,我们开发了一个简单的程序,通过 TraCI 在 SUMO 模拟器中执行强化学习,并表明车辆变得更加智能,能够到达目的地并避开拥堵的路径。 这证明强化学习在SUMO中是适用的,并且效果良好。
原文链接:Reinforcement Learning for Autonomous Vehicle Route Optimisation
BimAnt翻译整理,转载请标明出处





