
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
在进行地理空间数据科学工作时,考虑优化你正在编写的代码非常重要。 如何使具有数亿行的数据集更快地聚合或连接? 这就是空间索引(spatial index)等概念的用武之地。在这篇文章中,我将讨论空间索引的实现方式、它的优点和局限性,并了解 Uber 的开源 H3 索引库,了解一些很酷的空间数据科学应用程序。 让我们开始吧!
1、什么是空间索引?
常规索引是你可能会在书的末尾找到的那种东西:单词列表以及它们在文本中出现的位置。 这可以帮助你快速查找特定文本中对你感兴趣的单词的任何引用。 如果没有这个方便的工具,你将需要手动浏览书中的每一页,搜索想要阅读的提及内容。
在现代数据库中,查询和搜索的这个问题也非常具有针对性。 索引通常可以比过滤更快地查找数据,并且你可以根据感兴趣的列创建索引。 特别是对于地理空间数据,工程师经常需要查看“交叉”或“附近”等操作。 我们如何制作空间索引以使这些操作尽可能快? 首先,让我们看一下一些地理空间数据:
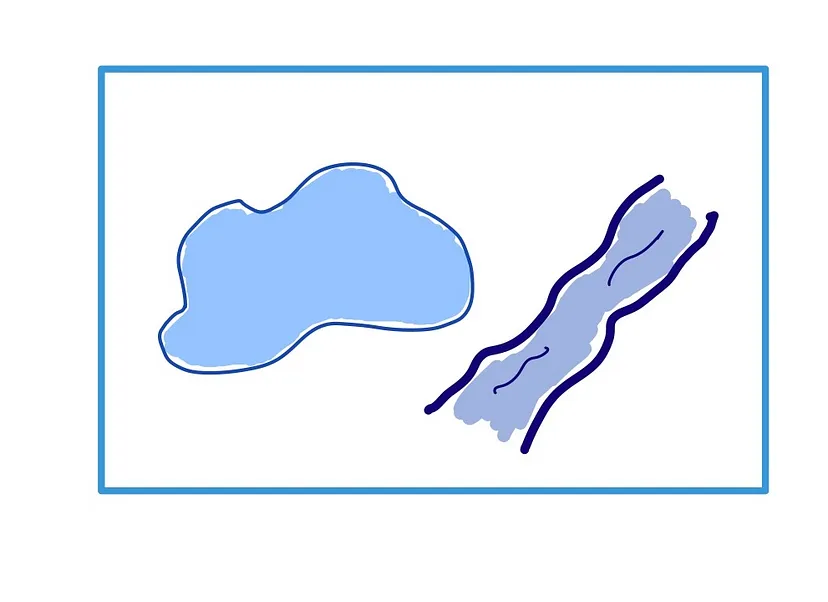
假设我们想要运行一个查询来确定这两个形状是否相交。 通过构造,空间数据库在包含几何图形的边界框之外创建索引:
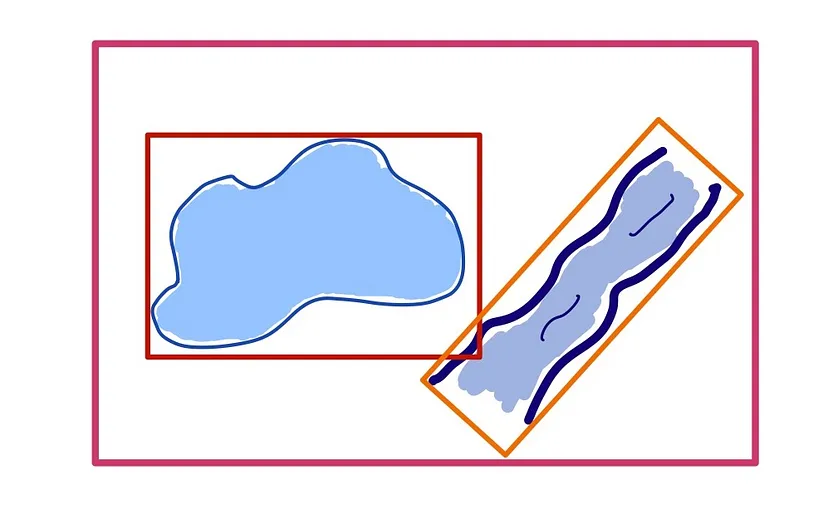
为了回答这两个特征是否相交,数据库将比较两个边界框是否有公共区域。 正如你所看到的,这很快就会导致误报。 为了解决这个问题,像 PostGIS 这样的空间数据库通常会将这些大的边界框划分为越来越小的边界框:
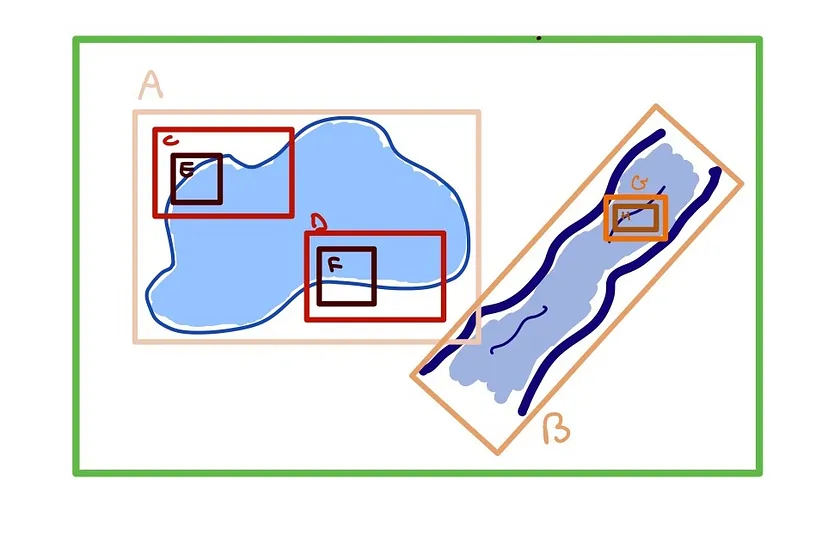
这些分区存储在 R 树中。 R 树是一种分层数据结构:它们跟踪大的“父”边界框、其子边界框、其子边界框的子边界框等等。 每个父级的边界框都包含其子级的边界框:
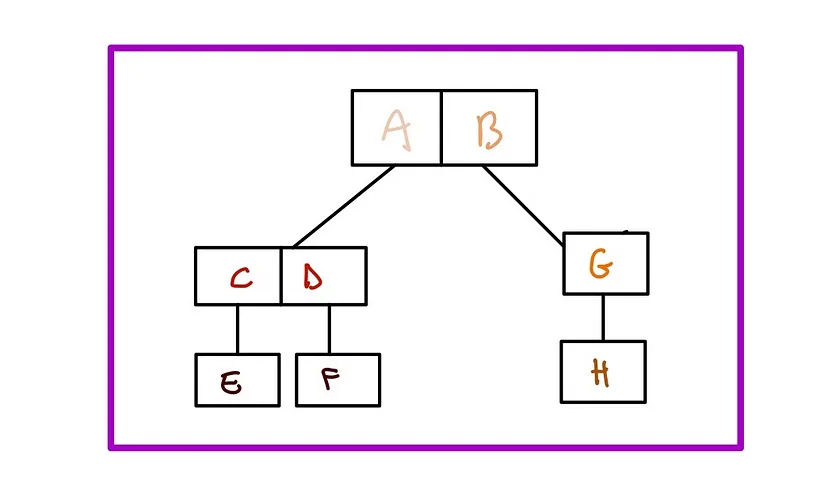
“相交”操作是受益于该结构的关键操作之一。 在查询交点时,数据库会向下查找这棵树,询问“当前边界框是否与感兴趣的特征相交?”。 如果是,它会查看该边界框的子级并提出相同的问题。 这样做时,它能够快速遍历树,跳过没有交集的分支,从而提高查询的性能。 最后,它根据需要返回相交的几何图形。
2、实践:使用 GeoPandas 尝试空间索引
现在让我们具体看看使用常规行式过程与空间索引是什么样子。 我将使用代表纽约市人口普查区和城市设施的 2 个数据集(均通过开放数据获得许可,可在此处和此处获取)。 首先,让我们在 GeoPandas 中尝试对人口普查区几何图形之一进行“交叉”操作。 GeoPandas 中的“Intersection”是一个逐行函数,根据我们的几何形状检查感兴趣列的每一行,并查看它们是否相交。
GeoPandas 还提供了使用 R 树的空间索引操作,并允许我们执行交集。 以下是两种方法超过 100 次相交操作运行时的运行时比较(注意:因为默认的相交函数很慢,所以我只从原始数据集中选择了大约 100 个几何图形):
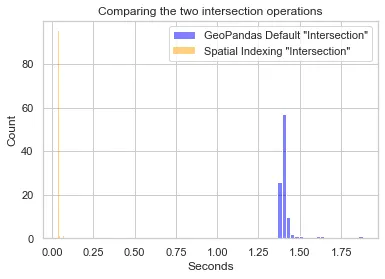
正如你所看到的,空间索引方法比普通交集方法提供了更好的性能。 事实上,以下是每个运行时间的 95% 置信区间:

太棒了! 那么,为什么我们不想使用空间索引呢? 是否存在没有任何好处的情况? 嗯,是。 其中一些限制是由于空间索引在数据中存储叶子的方式造成的。 事实证明,原始数据的分布方式会影响边界框在 R 树中的放置方式。 具体来说,如果大量数据集中在同一地理空间中,它们将倾向于共享相同的父级,从而被分组到相同的分支中。 这可能会导致树倾斜,在查询时无法提供太多优化。
4、其他空间索引是什么样的?
其他公司也调整了自己的空间索引。 Uber 使用 H3,一种六边形分层索引系统,将世界划分为等面积的六边形。 在对人们在城市周围的运动进行建模或解决计算半径等问题时,六边形有很多好处。 地理空间数据被存储在这些六边形中,作为公司的主要分析单位。 该网格是通过将 122 个六角形单元叠加到二十面体地图投影上而构建的,它支持多种功能,包括聚合、连接和机器学习应用程序。
该系统及其许多功能都是开源的,可以在 GitHub 上进行分析。 H3 API 的功能之一是根据指定的分辨率将纬度和经度点转换为表示唯一六边形的字符串。 让我们对整个设施数据库执行此操作,并将六边形字符串转换为多边形:
import h3
fac_db['h3'] = fac_db['geometry'].apply(lambda point: h3.geo_to_h3(lat = point.y, lng = point.x, resolution = 5))
h3_agency = fac_db.groupby(['h3', 'AGENCY'], as_index = False).count().sort_values('OBJECTID', ascending = False)
highest_agency = h3_agency.groupby('h3').first().reset_index()
highest_agency['geometries_h3'] = highest_agency['h3'].apply(lambda x: Polygon(h3.h3_to_geo_boundary(x, geo_json = True)))在这些空间数据分析项目中经常出现的一个问题是,六边形中有多少项目是按某个列(例如“机构”)分类的。 幸运的是,现在我们已经将数据放入 H3 六边形中,因此计算和可视化非常容易:
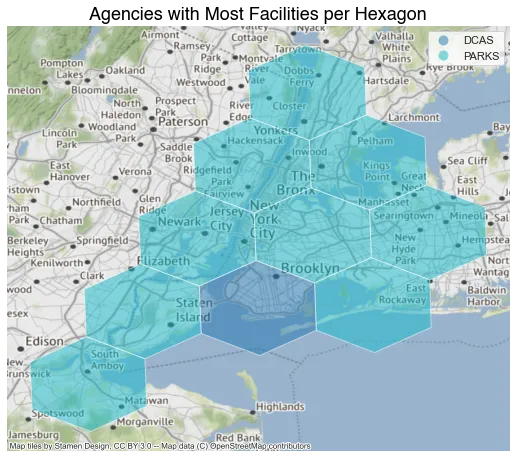
在本例中,您可以看到 DCAS(全市行政服务部)和 PARKS(公园和娱乐部)是每个六边形中设施最多的两个机构。 这可能是有道理的,因为这两个机构将拥有更多的实体设施(例如行政大楼或公园等休闲区)。
5、结束语
正如你所见,空间索引是地理空间数据科学和分析非常有用的优化工具。 在简单的交集查询的情况下,与标准 GeoPandas 交集函数相比,使用空间索引极大地提高了查询的性能。 该索引的实现方式及其含义有许多细微差别,例如拥有大量的集群数据分支。 正如我们所看到的,公司已经开发了自己的解决方案:一个例子是 Uber 的 H3 开源索引,它使我们能够回答各种空间分析问题。 虽然我演示了基于机构的设施计数操作,但 H3 为其他更复杂的机器学习应用程序提供了基准。
原文链接:Geospatial Data Engineering: Spatial Indexing
BimAnt翻译整理,转载请标明出处





