NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
理解和建模机器学习预测的不确定性对于任何生产模型都至关重要。 想想医疗诊断或自动驾驶汽车,当模型的预测不准确或危险时,我们需要一个办法来处理。
不确定性建模本身就是一个完整的研究领域,具有大量的理论和方法。 简而言之,对于简单模型(例如无处不在的线性回归),分析方法提供了精确的解决方案。 对于难以解决精确解的更复杂模型,可以使用统计抽样方法,其黄金标准是马尔可夫链蒙特卡罗方法(例如最先进的哈密顿蒙特卡罗方法)。
然而,当涉及到神经网络时,这两种方法都不尽如人意。 精确的解决方案是不可用的,即使是最好的采样算法也会因构成典型神经网络的数千(如果不是数百万)参数而窒息。
值得庆幸的是,即使无法实现完全的贝叶斯不确定性,也存在一些其他方法来估计神经网络具有挑战性的情况下的不确定性。
今天,我们将探讨一种方法,归结为使用神经网络对概率分布进行参数化。我们使用 PyTorch的distributions包。
第一步是选择合适的概率分布。 选择取决于上下文:在回归设置中,正态或对数正态分布可能是合适的,而对于分类,人们会选择分类分布。 值得庆幸的是,PyTorch 的distributions包提供了所有主要概率分布的实现。
1、正态分布
为了简单起见,我们将在下文中考虑众所周知的正态分布,但该方法对于任何其他概率分布都是相似的。
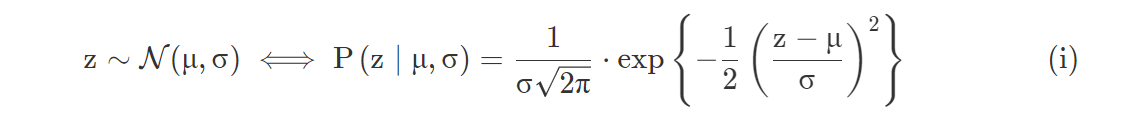
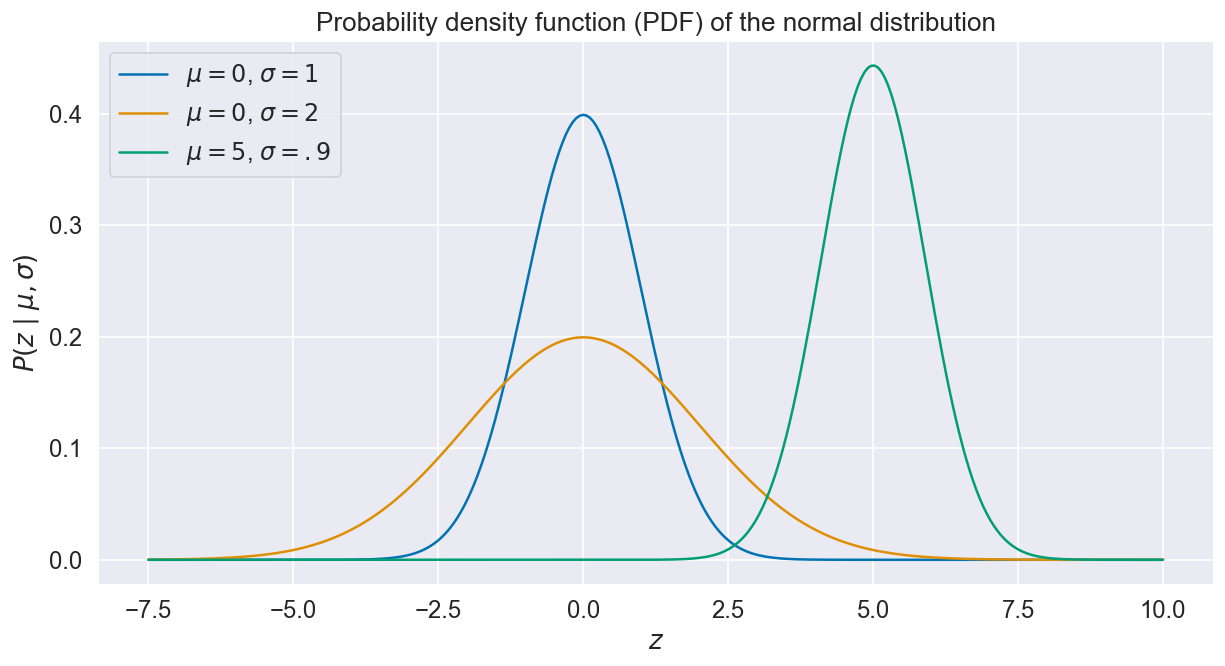
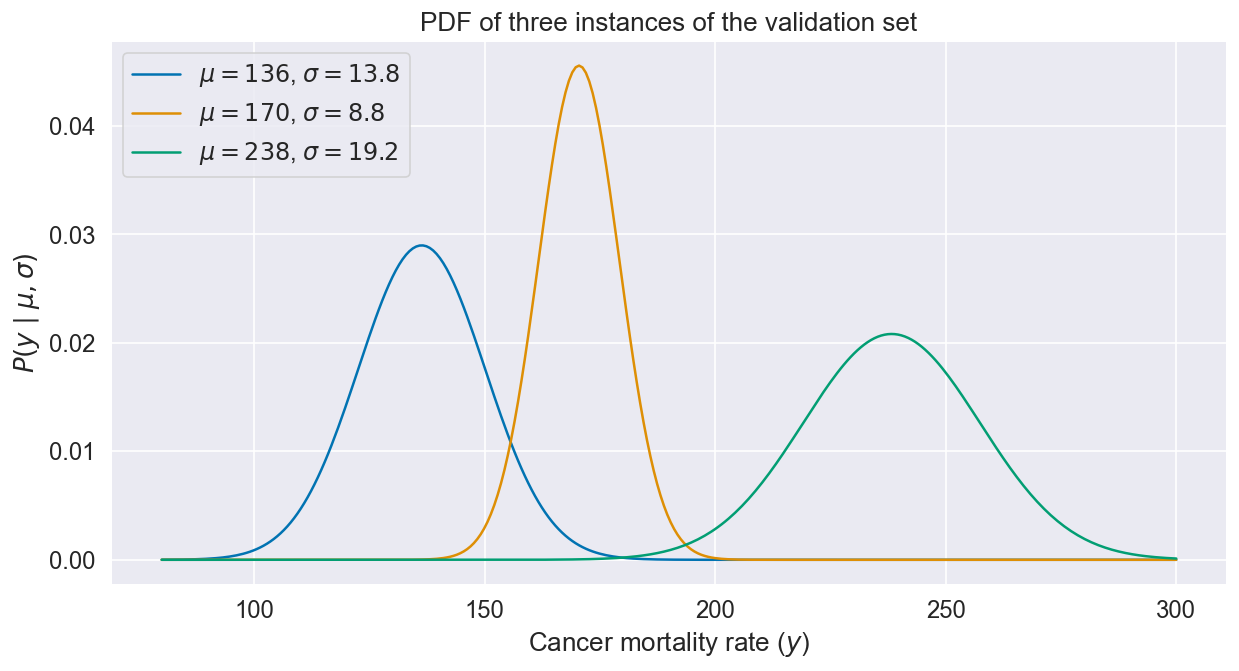
这里,~表示采样自,P(z|μ,σ) 是概率密度函数(PDF),表示在给定分布均值和标准方差下z值的可能性。具有不同的μ和σ的正态分布PDF实例如下图所示:
2、参数化正态分布
假设我们正在尝试对 来自一组特征x的输出y建模。在经典的非概率设置中,我们的神经网络由一个函数f表示,它依赖于输入x和可训练参数Θ:
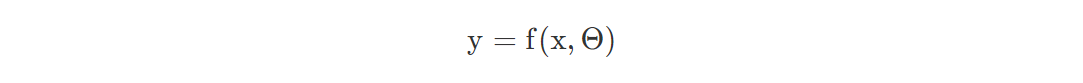
我们如何将这个模型变成概率神经网络?
- 回顾上一节,我们可以将模型的预测等同于分布均值μ:不考虑不确定性,μ 是最可能的结果。
- 反过来,假设正态分布在这种情况下是合适的,标准方差σ是一个很好的统计数据,可以总结我们预测的不确定性。
将μ(x,Θ1) 和σ(x,Θ1)作为两个自网络,分别具有可训练的参数Θ1 和 Θ2。
均值网络μ(x,Θ1)和原始网络f没有区别,可以用于预测。第二个网络σ(x,Θ2)则负责显式的建模不确定性。从(i)我们得到:
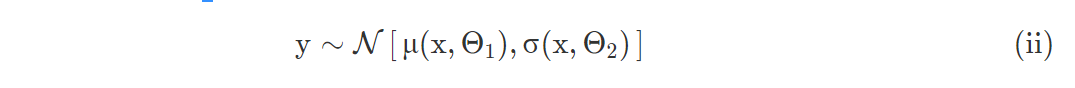
注意在实践中,Θ1 和Θ2会重叠,就是说这两个网络的最初几层是共享的,后面我们会深入这一点。
我们现在有两个子网络,包含共享和不同的参数。 我们想用一个损失函数联合训练它们。
等式 (i) 表示的概率密度函数是一个理想的候选者:诀窍是最大化观察到y的可能性,这一点PDF 准确表示了出来。
最好取 PDF 的对数而不是处理讨厌的指数。 另外,PyTorch 期望函数最小化,所以我们对数量取负:损失函数是在指定的x, Θ1 和 Θ2下观察到y的可能性的对数的负数
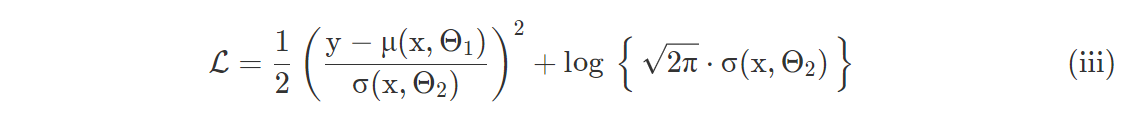
注意我们如何经典的均方误差中得到差项的平方(y−μ)2。
就是这样,我们已经用神经网络对正态分布进行了参数化,并设计了一个合适的损失函数。 每个输入都有自己独特的一组均值(预测)和标准差(不确定性),这些均值从 PDF 的优化中整齐地校准。
理论够了,接下来让我们实现吧。
2、应用:预测癌症死亡率
我们将使用来自 OLS 回归挑战的数据,其目标是根据许多社会人口变量(例如中位年龄、收入、贫困率、失业率等)预测美国各县的癌症死亡率。
我们不会进一步讨论数据集或数据准备步骤,但此 jupyter notebook 提供了重现代码。
关于 PyTorch 模型的实现:
class DeepNormal(nn.Module):
def __init__(self, n_inputs, n_hidden):
super().__init__()
# Shared parameters
self.shared_layer = nn.Sequential(
nn.Linear(n_inputs, n_hidden),
nn.ReLU(),
nn.Dropout(),
)
# Mean parameters
self.mean_layer = nn.Sequential(
nn.Linear(n_hidden, n_hidden),
nn.ReLU(),
nn.Dropout(),
nn.Linear(n_hidden, 1),
)
# Standard deviation parameters
self.std_layer = nn.Sequential(
nn.Linear(n_hidden, n_hidden),
nn.ReLU(),
nn.Dropout(),
nn.Linear(n_hidden, 1),
nn.Softplus(), # enforces positivity
)
def forward(self, x):
# Shared embedding
shared = self.shared_layer(x)
# Parametrization of the mean
μ = self.mean_layer(shared)
# Parametrization of the standard deviation
σ = self.std_layer(shared)
return torch.distributions.Normal(μ, σ)大部分实现应该看起来很熟悉:网络层(包括可训练参数)在 __init__ 函数中定义,然后前向函数将所有内容拼凑在一起。
一些值得注意的细节:
- 第一个隐藏层是共享的,并创建了一个公共嵌入。
- 接下来,计算分支到均值和标准方差子网络。
- 标准方差分支以 softplus 转换结束,以强化正极性。
- forward 方法输出由两个分支的输出参数化的 Normal 对象。
接下来是损失函数:
def compute_loss(model, x, y):
normal_dist = model(x)
neg_log_likelihood = -normal_dist.log_prob(y)
return torch.mean(neg_log_likelihood)说明如下:
- 按照上面的 forward 方法,调用模型返回一个分布对象。
- 这个对象提供了一个 log_prob 方法。 它的实现等同于等式(iii)。
- 返回所有输入的平均值。
训练可以像任何其他 PyTorch 模型一样进行。
正态分布对象提供 mean 和 stddev 属性:
model.eval()
normal_dist = model(x) # evaluate model on x with shape (N, M)
mean = normal_dist.mean # retrieve prediction mean with shape (N,)
std = normal_dist.stddev # retrieve standard deviation with shape (N,)训练后的拟合度:
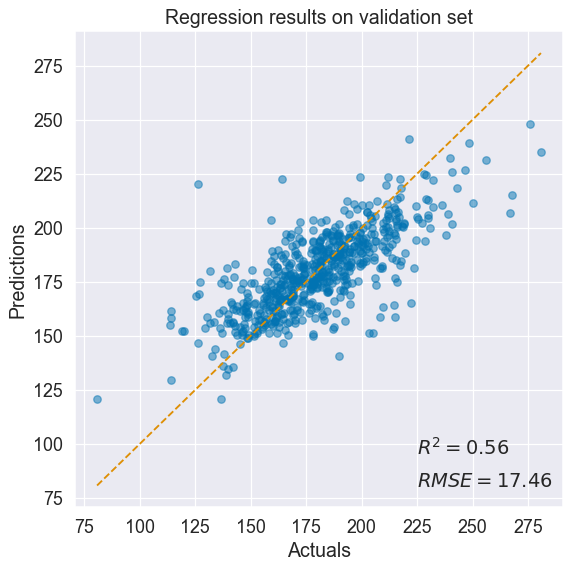
该模型在预测癌症死亡率方面做得不错。
两个模型输出的μ和σ分布:
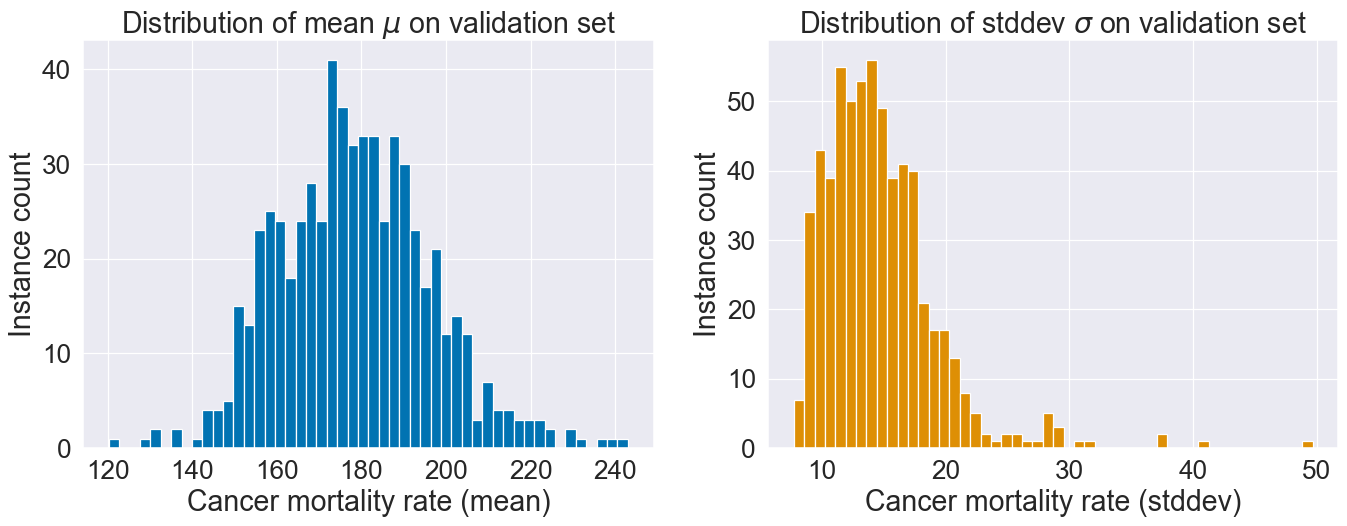
不同的实例得到不同的不确定性概况,因为μ 和σ 都取决于X:
我们对不确定性的估计有多好?
找出答案的一种方法是将不确定性与输入的令人惊讶或意外程度的度量进行比较。 意外输入应与更高的不确定性相关(例如,自动驾驶汽车遇到罕见的天气事件)。
出于我们的目的,意外性被衡量为与实例特征值中值的平均偏差。 特征值越极端,实例越出乎意料。
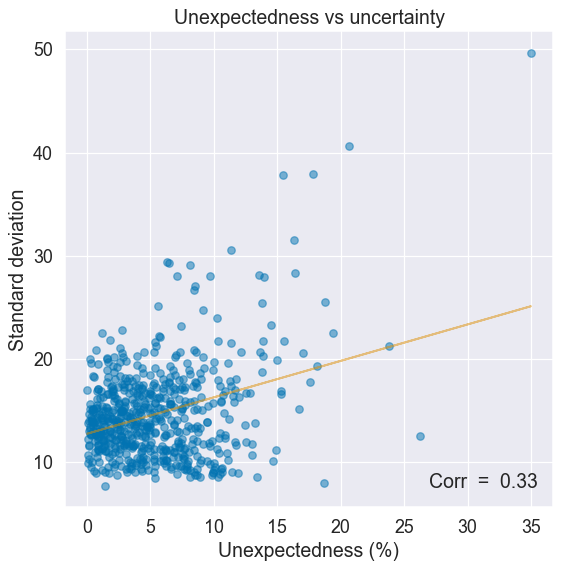
有一个上升趋势:不确定性往往会随着预期投入的减少而增加,这是应该的。
3、结束语
PyTorch 的distributions包提供了一种优雅的方法来参数化概率分布。
在这篇文章中,我们使用正态分布对不确定性进行建模,但是对于不同的问题还有大量其他分布可用。
这种方法的要点:
- 选择一个合适的概率分布。
- 设计一个神经网络,为目标分布中的每个参数输出一个值。
- 使用概率密度函数作为损失联合优化这些子网络。
好处是对模型预测的不确定性进行估计,代价是增加了一些额外的层。
这种方法简单且用途广泛—当我需要不确定感时,这是我的首选方法。
完整代码可在此处获得。
原文链接:Modeling uncertainty with PyTorch
BimAnt翻译整理,转载请标明出处