NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
在处理任何机器学习应用程序时,清楚地了解模型的偏差和方差非常重要。 在传统的机器学习算法中,我们谈论偏差与方差的权衡,这包括在尝试最小化模型的方差和偏差时的斗争。 为了减少模型的偏差,即减少错误假设造成的误差,我们需要一个更复杂的模型。 相反,降低模型的方差,即模型在捕获训练数据变化方面的敏感性,意味着更简单的模型。 很明显,在传统机器学习中,偏差与方差的权衡源于同时需要更复杂和更简单的模型的冲突。
在深度学习时代,存在一些工具可以在不损害模型偏差的情况下仅减少模型的方差,或者相反,在不增加方差的情况下减少偏差。 在探索用于防止神经网络过度拟合的不同技术之前,重要的是要弄清楚高方差或高偏差的含义。
考虑一个常见的神经网络任务,例如图像识别,并考虑一个识别图片中存在熊猫的神经网络。 我们可以自信地评估人类可以以接近 0% 的错误率执行此任务。 因此,这是图像识别网络准确性的合理基准。 在训练集上训练神经网络并评估其在训练集和验证集上的性能后,我们可能会得出以下不同的结果:
- 训练误差 = 20%,验证误差 = 22%
- 训练误差 = 1%,验证误差 = 15%
- 训练误差 = 0.5%,验证误差 = 1%
- 训练误差 = 20%,验证误差 = 30%
第一个例子是高偏差的典型例子:训练集和验证集的误差都很大。 相反,第二个示例存在高方差,在处理模型未从中学习的数据时准确率低得多。 第三个结果代表低方差和偏差,该模型可以被认为是有效的。 最后,第四个例子显示了高偏差和方差的情况:与基准相比,不仅训练误差大,而且验证误差也更高。
从现在开始,我将介绍几种正则化技术,用于减少模型对训练数据的过度拟合。 它们对前面示例的情况 2. 和 4. 有益。
1、神经网络的 L1 和 L2 正则化
与经典回归算法(线性、逻辑、多项式等)类似,L1 和 L2 正则化也用于防止高方差神经网络中的过度拟合。 为了使这篇文章简短和切题,我不会回忆 L1 和 L2 正则化如何在回归算法上起作用,但你可以查看这篇文章以获取更多信息。
L1 和 L2 正则化技术背后的想法是将模型的权重限制为更小或将其中一些权重缩小为 0。
考虑经典深度神经网络的成本函数 J:
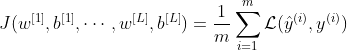
当然,成本函数 J 是每个层 1, …, L 的权重和偏差的函数。m 是训练示例的数量,ℒ 是损失函数。
2、L1 正则化
在 L1 正则化中,我们将以下项添加到成本函数 J:

其中矩阵范数是网络每一层 1, …, L 的权重绝对值之和:
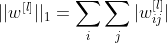
λ 是正则化项。 这是一个必须仔细调整的超参数。 λ 直接控制正则化的影响:随着 λ 的增加,对权重收缩的影响更加严重。
L1正则化下的完整代价函数变为:

对于 λ=0,L1 正则化的效果为零。 相反,选择太大的 λ 值会过度简化模型,可能导致网络欠拟合。
L1 正则化可以被认为是一种神经元选择过程,因为它将一些隐藏神经元的权重归零。
3、L2 正则化
在 L2 正则化中,我们添加到成本函数中的项如下:
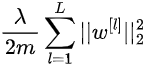
在这种情况下,正则化项是每个网络层权重的平方范数。 该矩阵范数称为 Frobenius 范数,明确地说,它的计算方式如下:
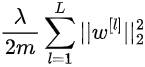
请注意,相对于层 l 的权重矩阵有 n^{[l]} 行和 n^{[l-1]} 列。
最后,L2正则化下的完整代价函数变为:
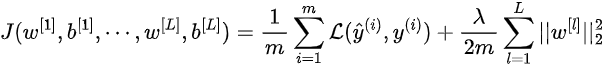
同样,λ 是正则化项,对于 λ=0,L2 正则化的效果为零。
L2 正则化使权重值趋于零,从而产生更简单的模型
4、L1 和 L2 正则化如何减少过拟合?
L1 和 L2 正则化技术对训练数据的过度拟合有积极影响,原因有二:
- 一些隐藏单元的权重变得更接近(或等于)0。结果,它们的效果减弱了,并且由此产生的网络更简单,因为它更接近于较小的网络。 如简介中所述,更简单的网络不太容易过度拟合。
- 对于更小的权重,隐藏神经元的激活函数的输入 z 也变得更小。 对于接近 0 的值,许多激活函数呈线性行为。
第二个原因并非微不足道,值得扩展。 考虑一个双曲正切 (tanh) 激活函数,其图形如下所示:
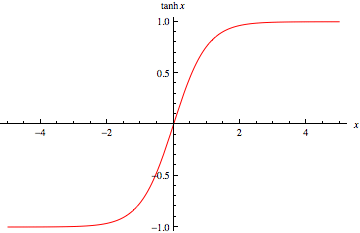
从函数图中我们可以看出,如果输入值 x 很小,函数 tanh(x) 的行为几乎是线性的。 当 tanh 用作神经网络隐藏层的激活函数时,输入值为:
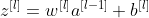
对于小权重 w 也接近于零。
如果神经网络的每一层都是线性的,我们可以证明整个网络的行为是线性的。 因此,限制一些隐藏单元模仿线性函数,会导致网络更简单,从而有助于防止过度拟合。
更简单的模型通常无法捕获训练数据中的噪声,因此过拟合的频率较低。
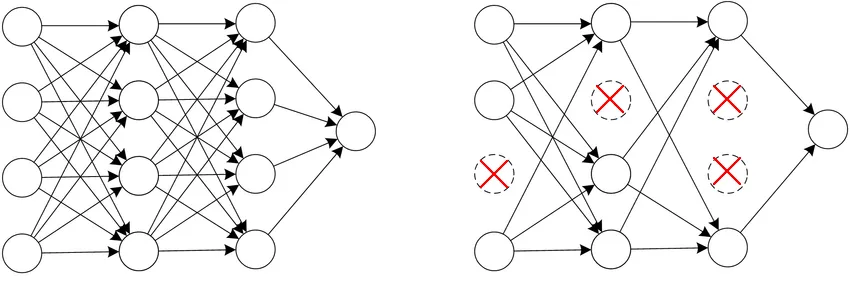
5、Dropout
dropout正则化的思想是随机移除网络中的一些节点。 在训练过程之前,我们为网络的每个节点设置一个概率(假设 p = 50%)。 在训练阶段,每个节点都有 p 的概率被关闭。 dropout过程是随机的,对每个训练样例单独执行。 因此,每个训练示例都可能在不同的网络上进行训练。
相对于 L2 正则化,dropout 正则化的结果是一个更简单的网络,更简单的网络导致更不复杂的模型。
6、Dropout实践
在这个简短的部分中,我将展示如何在实践中实现 Dropout 正则化。 我将介绍几行简单的代码 (python)。 如果你只对正则化的一般理论感兴趣,则可以轻松跳过本节。
假设我们已经将网络第 4 层的激活值存储在 numpy 数组 a4 中。 首先,我们创建辅助向量 d4:
# Set the keeping probability
keep_prob = 0.7
# Create auxiliary vector for layer 4
d4 = np.random.rand(a4.shape[0], a3.shape[1]) < keep_prob向量 d4 具有与 a4 相同的维度,并且包含基于概率 keep_prob 的值 True 或 False。 如果我们将保留概率设置为 70%,即保留给定隐藏单元的概率,也就是 d4 的给定元素具有真值的概率。
我们将辅助向量 d4 应用于激活 a4:
# Apply the auxiliary vector d4 to the activation a4
a4 = np.multiply(a4,d4)最后,我们需要通过 keep_prob 值对修改后的向量 a4 进行缩放:
# Scale the modified vector a4
a4 /= keep_prob需要最后一个操作来补偿层中单元的减少。 在训练过程中执行此操作允许我们在测试阶段不应用 dropout。
7、dropout 如何减少过拟合?
Dropout 具有暂时将网络变小的作用,我们知道较小的网络不那么复杂,也不太容易出现过度拟合。
考虑上面所示的网络,并关注第二层的第一个单元。 因为它的一些输入可能会由于 dropout 而暂时关闭,所以该单元在训练阶段不能总是依赖它们。 因此,鼓励隐藏单元将其权重分散到其输入中。 分散权重具有降低权重矩阵的平方范数的效果,从而导致某种 L2 正则化。
设置保持概率是有效 dropout 正则化的基本步骤。 通常,为神经网络的每一层分别设置保持概率。 对于具有较大权重矩阵的层,我们通常设置较小的保持概率,因为在每一步中,我们希望相对于较小的层按比例保留较少的权重。
8、其他正则化技术
除了 L1/L2 正则化和 dropout 之外,还有其他正则化技术。 其中两个是数据增强和提前停止。
从理论上,我们知道在更多数据上训练网络对减少高方差有积极作用。 由于获取更多数据通常是一项艰巨的任务,因此数据增强是一种技术,对于某些应用程序,它允许机器学习从业者几乎免费获得更多数据。 在计算机视觉中,数据增强通过翻转、缩放和平移原始图像来提供更大的训练集。 在数字识别的情况下,我们还可以对图像施加失真。 你可以检查此数据增强应用程序以进行手写数字识别。
顾名思义,提前停止涉及在最初定义的迭代次数之前停止训练阶段。 如果我们将训练集和验证集上的成本函数绘制为迭代的函数,我们可以体验到,对于过度拟合模型,训练误差始终保持下降,但验证误差可能在一定数量后开始增加 的迭代。 当验证错误停止减少时,这正是停止训练过程的时间。 通过更早地停止训练过程,我们迫使模型变得更简单,从而减少过度拟合。
原文链接:Regularization Techniques for Neural Networks
BimAnt翻译整理,转载请标明出处