
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
在Machine learning is going real-time中,作者 Chip Huyen 将实时机器学习系统分为两个级别:
- 级别 1:可以实时进行预测的机器学习系统(在线预测)
- 第 2 级:可以不断从新数据中学习并实时更新模型的机器学习系统(在线学习)
第一层的系统能够做出相关/及时的预测,比如广告排名、跌倒检测、欺诈检测等。实时预测股票价值比一个月后更有价值,对吧?但对于 Level 1 ML 系统,技术挑战大多通过成熟的开源工具来解决,例如Apache Flink(流处理)、Kafka(事件驱动架构)、模型压缩、Kubeflow(工作流管理)和Seldon(自动缩放模型服务) )。所有这些 工具都有明确的开发路线图,以不断提高模型推理速度并简化管道开发。
然而,更难的部分是实施 2 级 ML 系统,该系统可以进行在线学习并使用新数据实时更新模型。MLOps 社区中几乎没有关于如何构建它们的讨论和共识。事实上,CDFoundation 的 SIG MLOps 将在线学习列为“需要研究”,直到 2024 年。那么,使用当前的开源工具构建实时机器学习管道有多容易?
1、在线学习的好处
等等,在我们继续前进之前,我们为什么要进行在线学习?近年来,流处理器的成熟让DataOps能够(1)以可扩展的方式处理实时数据(2)统一批处理和流处理,从Lamba架构转向更简单的Kappa架构。它们为我们的管道提供持续不断的实时数据流,这让我们产生疑问:我们能否实时从这些数据中提取更多价值?
答案(你可能已经猜到了):是的,我们可以。在线学习更频繁地更新我们的 ML 模型以处理诸如社交媒体上的趋势内容、罕见事件(黑色星期五)甚至在冷启动期间(新用户行为)等情况。当你需要提高模型性能以快速响应动态数据时,它会大放异彩。因此,值得一问:增加模型更新的频率可以产生多少价值?
2、实时机器学习管道架构
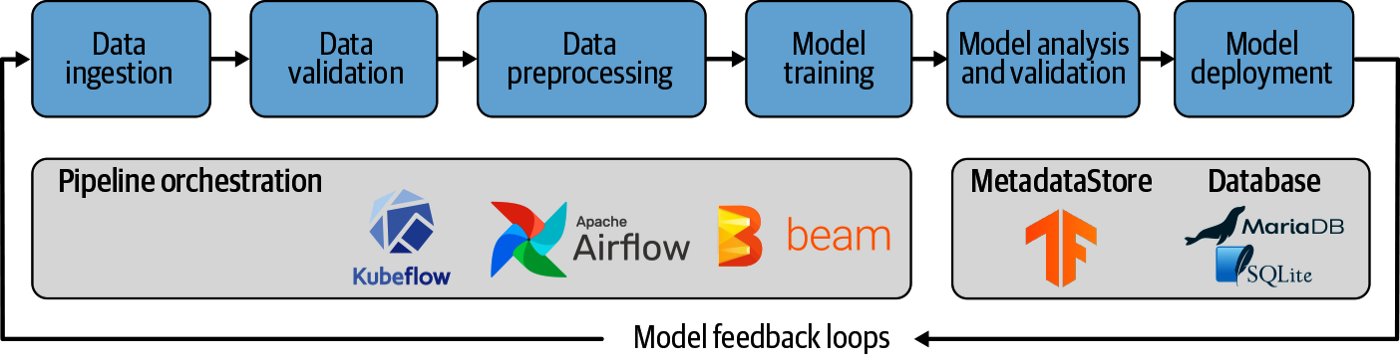
好的,既然我们了解了好处,我们应该如何设计实时 ML 管道?网上有一些行业参考资料,不出所料,这些公司拥有大量的实时用户交互数据。在查看它们之前,有必要回顾一下离线 ML 管道,因为将它们发展到在线仍然涉及相同的过程,只是它变成了一个长期运行的连续循环——摄取、训练和部署。
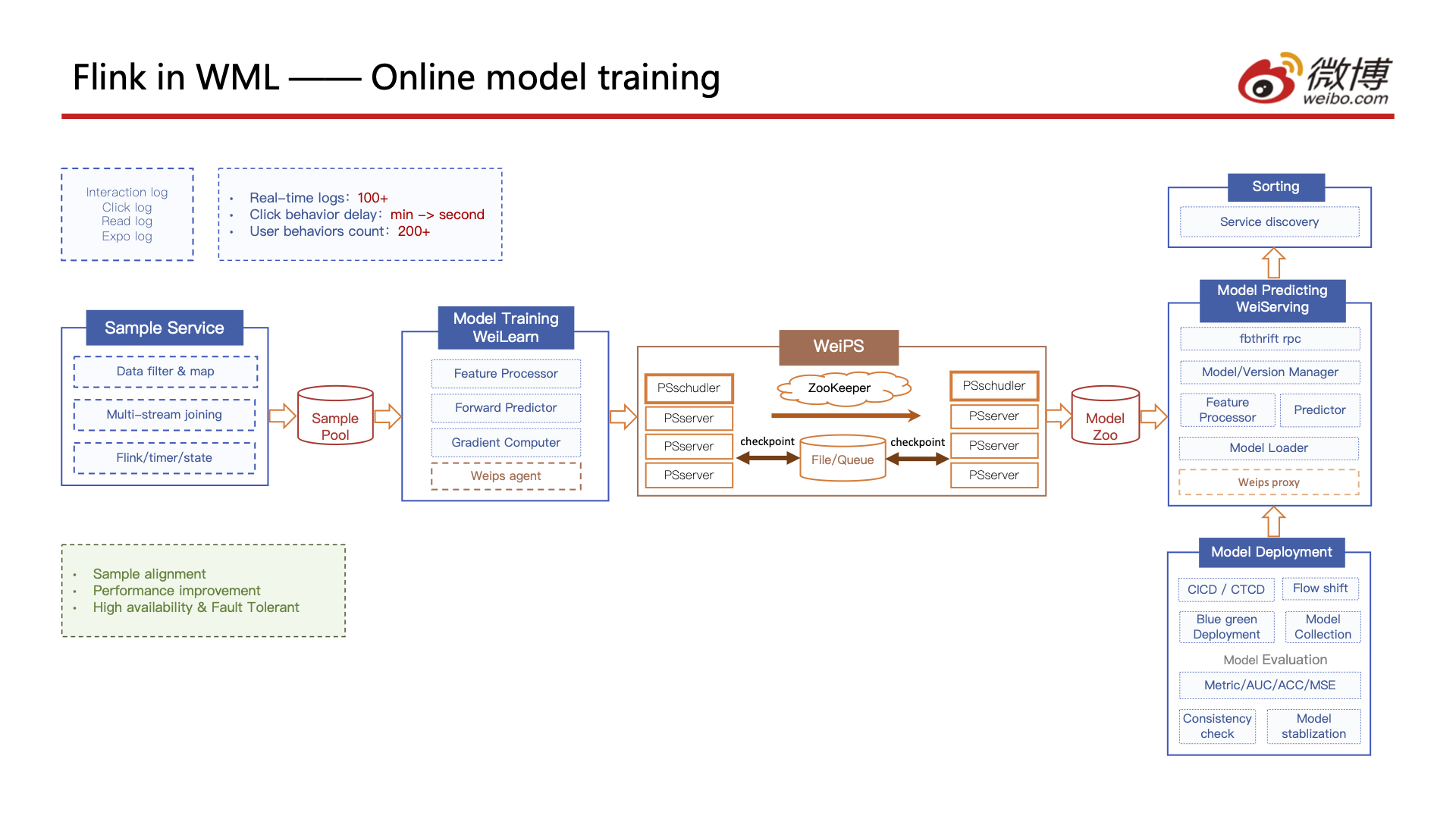
在Flink Forward Virtual 2020期间,微博(社交媒体平台)分享了 WML 的设计、他们的实时 ML 架构和管道。从本质上讲,他们已经将以前分离的离线和在线模型训练集成到一个使用 Apache Flink 的统一管道中。演讲的重点是如何使用 Flink 通过将离线数据(社交帖子、用户资料等)与多个实时交互事件流(点击流、阅读流等)和提取的多媒体内容特征相结合来生成用于训练的样本数据。没有提到具体的模型架构,但他们正在进行在线训练 DNN。
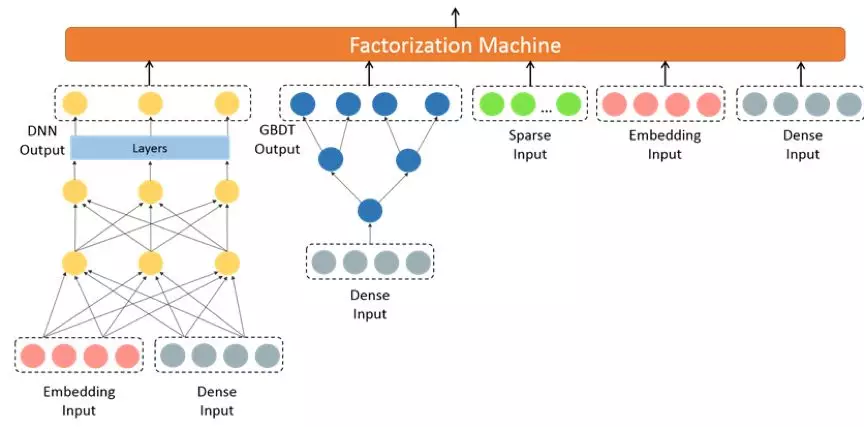
同时,PAI(Platform of Artificial Intelligence)是阿里云(云厂商)的产品,它允许用户通过拖放可视化 UI 构建在线机器学习管道。2019 年初,他们在平台上发布了 FTRL(Follow The Regularized Leader)在线学习模块,以支持推荐用例,例如新闻推荐。那年晚些时候,在阿里巴巴的(电子商务)工程博客上,他们分享了他们如何使用在线培训来预测双十一期间的点击率(CTR)和转化率(CVR)。
由于影响CTR/CVR的因素很多,比如促销和季节,模型采用了“多层多频”的方式。它是从 XNN 演变而来的,部分模型使用冻结嵌入的检查点,而部分模型使用更改嵌入/更改权重。该管道执行在线训练以及实时模型更新(A/B 测试)。他们使用 AUC 运行在线评估,将模型精度与 10 分钟前的样本进行比较。(阿里巴巴还开源了在线 FTRL 作为 Alink 的一部分,将在下一节中提到。)

几乎同一时间,爱奇艺(视频流媒体)分享了他们在线训练 Wide & Deep DNN for Streaming Recommender System 的经验。他们使用了“lambda”方法:对过去 7 天的数据进行离线训练模型,并使用该检查点作为他们日常在线模型实时摄取的开始。在线培训只有一次,然后每小时部署模型。使用这种架构的原因是为了纠正在线模型,因为它过度拟合局部模式并观察到性能下降,并且 OOV(词汇外)的可能性很高。下一步,他们正在探索替换 Adam 优化器和部署频率。
从上面的例子来看,几个趋势很明显:
- 公司正在为离线和在线培训统一 MLOps 管道
- 他们还转向使用 DNN在线训练更深层次的模型
- 并尝试更频繁的模型部署(<10 分钟,甚至实时!)
3、工具和库
有几组开源库用于在 ML 管道中实现在线培训。有些构建在 Flink 之上,而有些则使用 Spark Streaming。它们中的大多数需要 Java 在流处理器上运行,但有些提供 API 甚至在 Python 上原生运行(对来自 Python 深度学习生态系统的开发人员更友好!)。
- River -从头开始设计用于在线培训:它可以通过单个观察更新模型,包含用于构建预处理管道和流数据评估指标的实用程序。唯一拥有大多数在线学习算法的库,包括 Tree/FM/Linear/Naive Bayes/KNN 分类器和回归器、K-means 聚类和半空间树异常检测。它的 SKLearn 风格的 API 很多人都会非常熟悉,如果你更喜欢 Python,那是最好的选择!
- FlinkML —提供了一些 ML 算法,但旧的库在 Flink 1.9 中被删除了。目前,正在利用 Flink Table API 进行重新开发,以提供管道接口和模型服务。在这里可以看到进度(在撰写本文时只有几个界面)。
- Alink——阿里巴巴发布的基于 ML 算法的算子集合,建立在 FlinkML 新的管道接口之上。它同时具有 Python 和 Java API。但是,FTRL 是唯一的在线训练算法,其他都是批处理算法。如果您更喜欢 Flink 生态系统,这是最好的选择。
- Spark Mllib 的 Streaming Algorithms —类似于 FlinkML,提供多种流式 ML 算法,但在 Spark Streaming 生态系统中。它具有 Python 和 Scala API 来构建管道和导出 PMML 模型。自 Spark 2.0 以来也正在重新开发以利用 DataFrame API。较旧的库包含在线 Kmeans 聚类和线性回归。
- Oryx —一个 lambda 架构开发平台,使用 Kafka 和 Spark。它提供批处理、速度和服务层来管理模型训练和更新 (PMML)。目前包含 ALS 推荐、K-means 聚类和随机森林分类/回归流算法。不幸的是,自 2019 年以来没有重大进展。
总体而言,所有库仍在开发中,并且大多数优先考虑批处理/离线训练算法。River 是唯一一个使用最多算法优先考虑在线训练的库,而其他从离线训练开始的库可能更适合在生产中部署。
4、未来的挑战
本文探讨了用于构建实时机器学习管道的常见架构和开源工具的当前状态,重点关注实现和工程角度。在后续系列中,我将构建实时 ML 管道并不断探索改进它们的想法,例如比较检查点+在线训练和 100% 在线训练、实时模型部署等。
原文链接:Building ML Pipelines to Learn from Data in Real-time (Survey)
BimAnt翻译整理,转载请标明出处





