
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
当我们谈论 3D 优化时,我们首先想到的往往是减少三角形网格中三角形的数量。 无论是想要优化游戏的游戏开发者,还是想要更轻模型的 3D 艺术家,如今最常见的过程称为网格抽取(Mesh Decimation)。
1、什么是网格抽取?
由于我们在这里讨论的是 3D,因此我们将在 3D 网格的上下文中讨论抽取算法。 另外,我将谈论三角形而不是 n 边形,因为三角形是当今所有网格抽取算法所使用的。
网格抽取算法是一段程序,可以在给定一些参数的情况下自动减少网格的三角形数量。 通常,主要参数是生成的网格中的三角形数量(三角形初始数量的数量或百分比)。

这样的算法可以以各种方式实现。 首先,我们需要一种方法来实际减少三角形的数量。
2、删除三角形
有多种解决方案:
- 逐个删除顶点(将三角形连接在一起的点)
- 折叠边缘
- 折叠整个三角形
移除顶点包括逐步取消细分网格。 它很容易实现,但有一个主要的缺点:当顶点被删除时,我们不会补偿拓扑的变化。 一种解决方案是更改与已移除顶点相邻的顶点,但这会以更大的复杂性为代价。
折叠整个三角形是我从未实施过的解决方案。 我列出它是因为它在理论上可行,但它会非常具有破坏性,因为对多边形数量的控制很少,因为删除单个三角形可能意味着许多其他拓扑变化。
折叠边缘(也称为“边缘折叠方法”)是当今最佳网格抽取算法中最常用的方法。 当折叠一条边时,我们实际上将两个顶点合并为一个顶点,允许将新顶点放置在可以补偿拓扑变化的位置。 此外,此方法适用于半边网格数据结构,这是一种在内存中组织网格以允许轻松遍历和连接查询的方法。
3、删除哪些三角形?
现在我们有了去除三角形的方法,但应该去除哪些三角形呢?
嗯,这是最复杂的部分。 假设我们使用边折叠来删除三角形:边折叠方法采用边(显然)。 一般的想法是将边从对一般对象形状和颜色的贡献从低到高排序。
困难的部分是:我们如何量化边缘对物体形状和颜色的贡献?
如果你花一些时间思考这个问题,你可能会意识到它很复杂并且启发式方法是不可避免的:与 b-rep / nurbs 3D 模型不同,三角形模型已经是艺术家心中的几何近似( 除非我们通过设计谈论立方体或曲面细分,但对于这种情况,抽取实际上没有意义)。
在过去的四十年里(自 3D 游戏出现以来),一些人对此进行了思考并提出了不同的想法来创建这样的估算器。 常见的分享给大家:
3.1 基于距离的估算
它可能是最简单的估算器。 这个想法是计算折叠前后局部形状之间的最大距离。 这种方法有些局限。 我给你举个例子:假设我们要折叠边缘 BC,你选择什么解决方案?
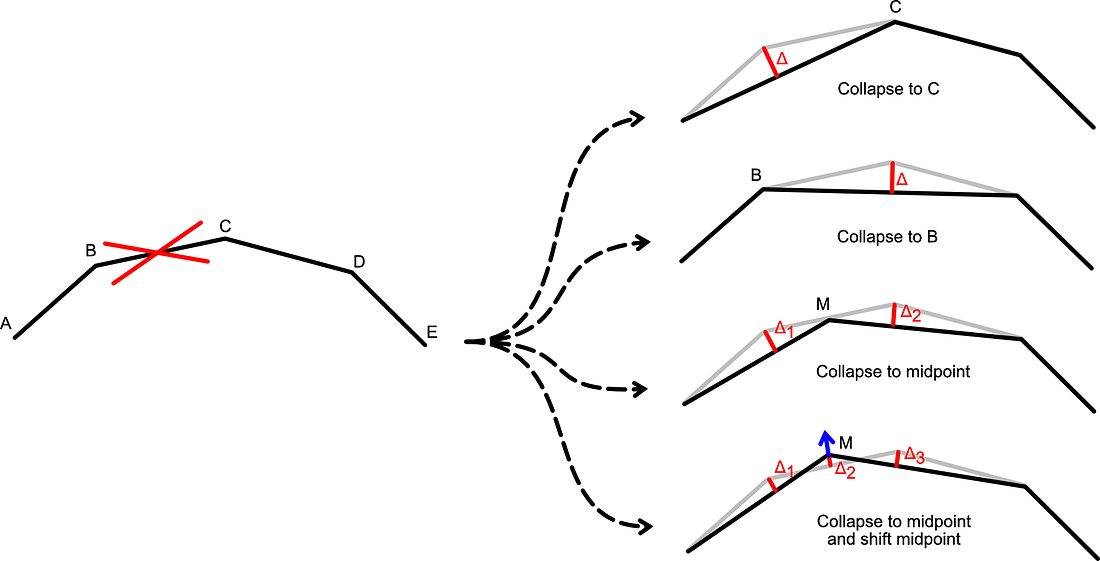
如你所见,有很多方法可以根据距离折叠边缘。 然而,这些都不能保证是最佳的,这只是一个猜谜游戏。
3.2 基于角度的估算器
另一个有点简单的估计器。 在边缘折叠的情况下,想法是在边缘连接两个面时按它们的角度对边缘进行排序。 它非常适合移除接近共面的三角形,但在处理顶点法线时很快就会变得棘手,这可能会独立于其折叠角度将边指定为硬边或平滑边。
3.3 基于二次误差的估算器
二次误差是基于局部表面的二次表示的估计量。 它使用矩阵,并已被证明是一个相当精确的估计器。 它还具有允许在折叠后计算最佳顶点位置的好处(不同于在设置位置之间手动选择)。 你可以在 Michael Garland 和 Paul S. Heckbert 的论文“使用二次误差度量的表面简化”中找到有关此内容的详细信息。
这种方法有多种变体,你应该能够在 Internet 上很容易地找到这些变体。
4、当今可用的解决方案
几乎每个基于多边形的 3D 建模/编辑软件中都有网格抽取算法。 几乎所有都使用基于二次误差的边缘折叠方法,每个方法都有一些调整。
我可以提到 3DS Max、Blender、Houdini、Simplygon、InstaLOD、Pixyz、Meshlab ……每个都有自己的缺点和优点。 最快的通常是 Blender 的实现,但就结果而言,它也可能是最差的。 在我看来,Pixyz 的实施质量最好,性能优于平均水平。
5、我们为什么要改进它?
年复一年,随着越来越多的工具可用,游戏开发变得越来越容易。 随着 Blender 的闪电般快速开发,建模变得越来越容易,Unity、Godot 或 Unreal 的关卡设计变得越来越容易,游戏编程越来越容易使用高级语言和无代码(例如 Unreal 的蓝图,Unity 最近收购的Bolt,...)。
然而,有一件事仍然和以往一样困难:游戏优化。 今天的游戏优化需要深入了解 CPU/GPU 通信、渲染管道、光栅化理论等。
我不会在这里介绍所有优化方法,但减少 GPU 负载的一种非常常见的方法是减少在屏幕上绘制的三角形数量,因为它减少了光栅化期间要完成的计算数量。 如前所述,抽取网格是实现此目标的一种方式,无论是为了创建更适合的网格还是 LOD(细节层次)。
这就是为什么一个好的抽取算法是简化优化过程的关键。 这不是你想要手动执行或调整的事情:它应该在第一次尝试时产生最佳结果。
我个人认为抽取是我们可以更频繁地使用的东西。 例如,可以使用抽取代替手动重新拓扑。 我相信它可以比任何人更好地完成这项工作,但它需要比我们今天所知道的更好(一些 CG 艺术家会因此而恨我,但伙计,我正在尽我所能让你的生活更轻松)
6、构建更好的网格抽取算法
为了制作出色的抽取算法,我们需要了解现有算法存在的问题。 我不会指出具体的软件,因为有太多的技术细节,我不可避免地会在某些时候说错。 此外,软件更新的频率将超过我能够更新这篇文章的频率。
让我们来看看在我看来完美的抽取算法应该具备的东西列表,你可能会注意到今天的实现很少甚至从未满足一些要点:
- 处理法线
在抽取过程中考虑法线是非常棘手的,但不幸的是现在强制性的,因为每个人都使用顶点法线。 很少有论文讨论这个并且只涉及基本的三角形移除。
- 纹理处理
通常,在今天的游戏中,99% 的时间都将纹理应用于模型。 这通常意味着 UV 坐标连同顶点。
- 动画处理
这只涉及装配模型,但它有其自身的重要性,因为装配模型通常会占用大量三角预算,因为细节通常放在角色建模中,它暗示了所有复杂的东西(头发、衣服、手指……)。
抽取时,我们通常不会触及动画本身(应用于绑定的动作),而是将顶点分配给绑定的骨骼。 即使是最好的算法在这方面也常常受到限制,因为它都是关于做出复杂的妥协,并且错误的分配可能会在视觉错误方面付出很多代价(例如,一只手靠近腿,在抽取顶点手指时会被重新分配给 腿骨......我会让你想象当角色开始走路时的混乱🤡)
- 处理边界
几乎所有生产就绪的实现都考虑了边界,但是,并不是所有的实现都很好地估计了该边界的重要性,主要是因为有几种类型的边界。
- 支持额外的顶点属性
我们谈论法线、UV、骨骼权重……但实际上还有更多可能的顶点属性。 实际上,它实际上是无限的,因为这只是用户数据。 所有实现都限于少数几个可能的属性。
- 管理实例
抽取包含实例化网格(在模型中多次使用的单个网格,在不同位置。例如:螺丝)的模型时。 抽取时,你只想抽取一个实例化网格一次,而不是实例化的次数,否则它会破坏实例化并阻止渲染优化,例如 GPU 实例化。
- 全局估计器
可能是最不可预见的功能,但仍然是一个非常重要的功能。 当以 50% 的比例抽取一组网格时,天真的实现会以 50% 的比例抽取每个网格,这是强烈不推荐的!
想象一下,你同时以 50% 的速度抽取一个球体和一个立方体。 移除立方体上的三角形会彻底破坏它,而我们可以轻松移除球体上的三角形。 在这种情况下,我们希望从立方体中移除 0%,并移除超过 50% 的球体。
为此,我们需要对边进行排序以全局折叠而不是按网格折叠。
- 对生成的拓扑进行微调
在某些情况下,你希望将三角形中的角度限制在最小值以避免光照伪影,或限制边长以避免在动画或使用抽取作为重新拓扑工具时出现问题。
- 用质量标准控制
如果你曾经使用任何软件对模型进行过抽取,那么很有可能会被问及要移除(或保留)的三角形数量或要移除(或保留)的三角形比例。 这种情况如此普遍,以至于我将要告诉你的内容对你来说可能听起来不对,但请花点时间考虑一下:
在大多数情况下,抽取的目标并不是你想要的。原因如下:从来没有人要求i使用固定且精确的三角形数量。 为什么你需要从 4000 到 2000 个三角形? 真正重要的是保持足够的质量,使模型在将使用它的环境中看起来不错。
假设你想要抽取一个仅由直墙组成的建筑模型:抽取 50% 的三角形将完全毁掉模型。 如果你改用质量目标,它就不会进一步降低,因为模型实际上不能降低而不会让你的 3D 场景变得丑陋。
这就是为什么在大多数情况下应该使用质量标准而不是三角形计数目标来控制抽取算法。
- 一个很好的启发式估计
二次误差是一回事,但仅考虑所有属性类型和拓扑细节是不够的。 这其实是一个广泛的话题,并没有单一的方法。 在我这边,我认为机器学习真的可以在那里大放异彩。
7、性能问题
性能是我在谈论抽取时经常听到的话题。 但老实说,这并不是那么重要。 为什么? 因为抽取模型通常是一个离线过程,而不是在游戏过程中完成的事情。
我只是认为它应该足够快,不会破坏美术师/游戏开发人员的工作流程并让他切换上下文。 就个人而言,我确实会在大约 10 秒后切换上下文(我不是很耐心 😀),这对于运行抽取过程来说已经很多了。
此外,重要的是实现的算法复杂性:它不应像 0(n³),或者在抽取大型模型时永远不会结束。
抽取过程中成本最高的是使用估算器进行计算和重新计算的成本,以及保持边缘列表折叠排序的成本。 如果性能是一项功能,则可以通过降低排序频率、降低估算器的严格程度或使用更多启发式方法来进行权衡。
8、理论后的实践
因此,我们浏览了一系列可以使抽取算法接近完美的东西。 现在怎么办?
让我们来创造吧! 🛠
我不会详细介绍每个实现细节,但我正在写另一篇博文来解释我选择的数据结构。
另外,我选择了 C# 来实现它。 通常,人们使用 C 或 C++ 来处理这类事情,但我习惯了 C#,我认为用这种语言编写代码的体验要好得多。 此外,可以使用它提供的一些功能来做一些低级的事情。 我也想过用Rust来做,但是对它还不够熟悉。 无论如何,任何语言都应该做,最终只是上下文和性能的问题。
我尝试在其中实现本文中描述的所有内容,都可以在这个用于网格抽取的开源项目里找到。
原文链接:Mesh decimation done right
BimAnt翻译整理,转载请标明出处





