NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
这篇文章是思想实验和观察的集合,旨在提炼和解释我和其他人对 GPT 和 LLM 所做的一些主张和观察。
以其最一般的形式陈述,该主张是:系统或过程能够很好地预测某事的能力并不意味着用于做出这些预测的潜在认知在结构上与被预测的过程相似。
特别适用于 GPT 和 LLM:LLM 被训练来预测文本(其中大部分是由人类生成的)这一事实并不意味着 LLM 进行的潜在认知与人类认知相似。
特别是,当前的 LLM 不是人类思维或思想的升华,LLM 认知似乎也不是拟人化的。 当前 LLM 的预测错误和局限性经常反映人为局限性并模仿人为错误这一事实并不能证明潜在的认知是相似的。
相反,在这些错误中观察到的表面级相似性更有可能是由于当前 LLM 在文本预测任务中的能力与某些制度中人类水平的表现相似。 有很多方法可以得出错误或不完美的答案,这些方法不必彼此相似。 [1]
这篇文章的重点是微观:一个 GPT 预测下一个标记的分布,或者自回归地预测接下来的几个标记。 不考虑代理循环、专门提示、来回对话或链式推理,所有这些都可用于从基于 LLM 的系统中获得更好的宏观性能。
在下一个标记预测的特定微观任务上,当前 LLM 在许多示例中的表现通常与处于时间压力下或注意力不集中的无人协助的人相似。 其他时候,它远低于或远高于这个特定的人类基线。
1、背景及相关工作
其他人以前的一些帖子,有助于了解这个一般主题的背景和背景:
- 特征选择,作者 Zack Davis。 这是一个很好的故事,可以帮助我们建立对机器学习模型的内部认知可能是什么样子的直觉。
- 来自算法内部的感受,作者:Eliezer Yudkowsky。 一篇经典的文章,理解它有助于澄清我在这篇文章中对认知和认知输出之间的区别,以及为什么这种区别很重要。
- GPT-N 是否受人类能力的限制? 不,克莱奥·纳尔多 (Cleo Nardo)。 一篇关注 GPT 能力限制的帖子。 我认为将这一点内化有助于理解我在这篇文章中提出的“认知”与“该认知的输出”的区别。
- GPT 是 Eliezer 的预测器,而不是模仿器。 与 Cleo 的帖子一样,这篇帖子提出了一个重要的观点,即文本预测的性能不受生成被预测文本的系统的认知能力的限制,也不一定与其密切相关。
- 模拟器,由 janus 提供。 一篇探索由足够长的自回归预测链、代理循环和专门提示引起的宏观行为的帖子。 作为对比很有用,有助于理解可以在不同抽象级别分解和分析 LLM 行为的方式。
- 有认知领域吗?,一个拟人化的 AI 困境,作者 Tsvi。 这些帖子部分是关于探讨谈论“不同种类的认知”是否有意义的问题。 也许,在足够强大和准确的认知系统的限制下,所有的认知都集中在相同的底层结构上。
2、思维实验一:外星人训练的LLM大模型
考虑一个由外星人在外星文明互联网语料库上训练的基于 transformer 的 LLM。
这样的模型会有类外星人的认知吗? 或者它会使用当前 LLM 用来预测人类文本的类似认知机制来预测外来文本吗? 换句话说,外星人的 GPT 是更像外星人本身,还是更像人类的 GPT?
也许没有认知领域,实际上人脑、外星人脑、外星人!GPT和人类!GPT认知在某种重要意义上都非常相似。
2.1 人类/外星人翻译
在人类和外星人文本上接受过训练的 LLM 是否能够在人类语言和外星人语言之间进行翻译,而训练集中没有包含此类翻译示例的文本?
人类语言之间的翻译是当前 LLM 的新兴能力,但在训练集中,每对人类语言之间可能至少有几个翻译示例。
假设这样一个外星-人类 LLM 确实能够在人类和外星语言之间进行翻译。 学习和执行这种翻译时使用的认知是否与人类学习在没有训练数据的语言之间进行翻译的方式相似?
考虑一下 Daniel Everett 的这个演示视频,在这个演示中,他通过与说话者交流而不使用事先共享的语言来学习说和翻译他以前从未听过的语言:

在讲座中,丹尼尔和讲皮拉罕语的人表现出的认知类型与当前LLM大模型在学习和进行人类语言之间的翻译时表现出的认知类型截然不同,一次一个标记。
3、思维实验 2:人类思想的文字编码上训练的GPT
有时说 GPT 是“根据人类思想训练的”,因为训练集中的大部分文本都是由人类编写的。 但更准确和准确的说法是,GPT 被训练来预测人类思想的日志。
或者,正如 Cleo Nardo 所说:
好想象一下,互联网上的文字是由整个宇宙编写的,而人类只是宇宙中触摸键盘的点点滴滴。
但是考虑一个 GPT 字面意义上的训练来预测人类思想的编码,也许作为人类大脑的 fMRI 扫描的时间序列,适当地标记和编码。 不是预测文本序列中的下一个标记,而是要求 GPT 预测大脑扫描的下一个块或思想序列中的“思想标记”。
如果有正确的扫描技术和足够的训练数据,这样的 GPT 可能比当前的 LLM 更擅长模仿人类认知的输出。 也许这种 GPT 的潜在认知结构特征与人脑相似。 它与经过训练以预测文本的 GPT 有哪些共同特征?
4、思维实验 3:仅用计算机程序输出训练的 GPT
假设仅在现有计算机程序的日志和其他文本输出上训练 GPT,然后在推理时,要求它预测日志文件中的下一个标记,给定日志文件的前几行作为输入。
人类可能解决此预测任务的一种方法是对生成日志的程序形成假设,构建该程序的模型,然后在他们的头脑中或在计算机上执行该模型。
另一种方法是记忆日志和日志结构,对于现有程序生成的许多不同类型的日志,然后从这些记忆的日志中进行插值或外推,为推理时遇到的新日志生成补全。
GPT 可以使用哪些方法来解决这个任务? 可能更接近第二种方法,尽管原则上可能转换器网络的一些早期层形成程序模型,然后后续层对建模程序的几个展开步骤的执行进行建模以对其进行预测 输出。
观察一下,当人们在头脑中模拟 Python 程序的执行时,他们不会像在硅 CPU 上执行的操作系统上运行的 Python 解释器那样,将高级语句转换为机器代码,然后 一条一条地执行 x86 指令。 大脑和真正的 Python 解释器都可以用来预测给定 Python 程序的输出这一事实并不意味着用于生成输出的底层过程在结构上是相似的。
类似的观察可能适用于也可能不适用于 GPT:GPT 的某些子网络可以对程序的执行进行建模以预测其输出这一事实并不意味着用于执行此建模的认知在结构上与 在另一个基板上执行程序本身。
5、观察:LLM 错误有时看起来与人为错误相似
感谢@faul_sname 为这个例子提供了灵感,尽管我用它来得出与他们所做的几乎相反的结论。
考虑一个 LLM 被要求预测 Python 解释器会话(看起来像)的记录中的下一个标记:
text-davinci-003的输入:
Python 3.10.6 (main, Mar 10 2023, 10:55:28) [GCC 11.3.0] on linux
>>> a = 3
>>> a
4
>>> a花点时间考虑一下你将如何为该序列中的下一个标记分配概率分布,以及“正确”答案是什么。 显然,要么转录不是真正的 Python 解释器会话,要么解释器有问题。 你认为错误是暂时的(可能是宇宙射线在内存中稍微翻转的结果)还是持久的? 是否有另一个假设可以解释到目前为止的成绩单?
以下是 text-davinci-003 预测下一个标记的分布:

也许 text-davinci-003 对“comsic ray”假设有信心,或者它可能只是没有一个特别强大的模型来说明 python 解释器(无论是否有错误)的行为方式。
一个不同的例子,一个没有bug的脚本:
Python 3.10.6 (main, Mar 10 2023, 10:55:28) [GCC 11.3.0] on linux
>>> a, b = 3, 5
>>> a + b
8
>>> a, b = b, a
>>> a / b下一个标记的概率分布:
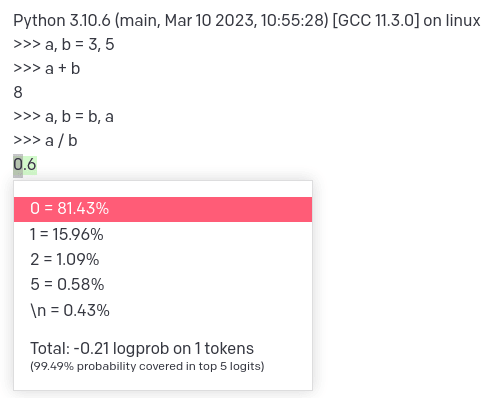
正确答案(或者至少是在真实的、没有错误的 python 解释器中执行这些语句的结果)是 1.6666666666666667。
稍作修改的输入:
Python 3.10.6 (main, Mar 10 2023, 10:55:28) [GCC 11.3.0] on linux
>>> a, b = 3, 5
>>> a + b
8
>>> a, b = b, a
>>> a * b
15
>>> a / b下一个标记的概率分布:
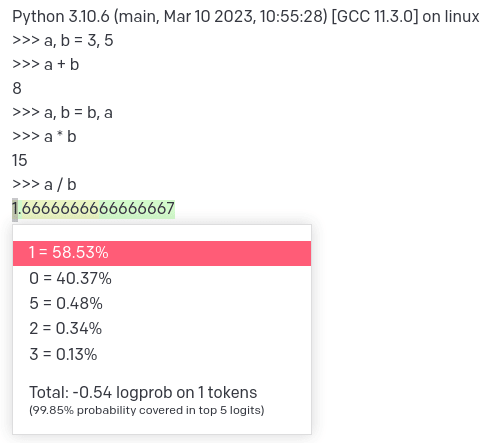
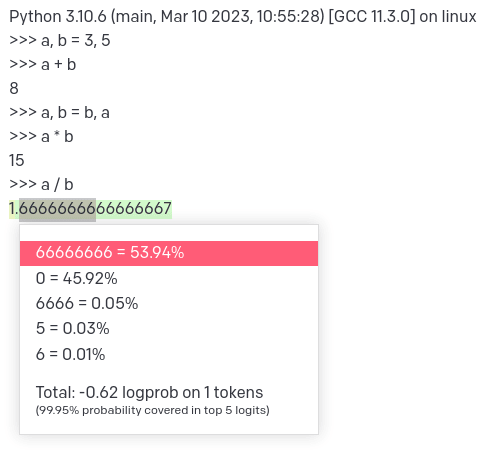
模型预测直觉上最有可能的正确答案,尽管它非常不确定。
一个人,如果被要求预测上述任何序列的下一个标记,是否可能出于类似的原因得出类似的概率分布? 可能不是,尽管取决于人类,他们对 Python 的了解程度,以及他们为做出预测付出了多少努力,从人类预测的概率分布中抽样产生的输出可能与抽样text-davinci's分布的输出相匹配 ,在某些情况下。 但是 LLM 和人类可能通过截然不同的机制得出他们的概率分布。
GPT 的预测错误有时看起来与人类可能犯的错误在表面层面上相似,这一事实可能是两个主要因素的结果:
- 在特定的文本预测任务中,GPT 认知与注意力不集中的人之间的能力水平相似。
一些预测任务的不明确性质 - 什么是“正确”答案,例如,在不一致的 python 解释器转录本的情况下? - 在人类和 GPT 之间的采样输出看起来相似(特别是类似“错误”)的情况下,这可能更多地是关于任务的性质和每个系统的性能水平的事实,而不是关于两者执行的潜在认知。
6、结论
这些思想实验和观察并不是为了明确表明未来的 GPT(或基于它们的系统)不会具有类似人类的认知。 相反,它们旨在表明当前 LLM 输出与人类输出的明显表面级相似性并不意味着这一点。
GPT 是预测器,而不是模仿器,但模仿是进行预测的一种方式,这种方式在许多领域通常都很有效,包括模仿明显的错误。 人类擅长模式匹配,但通常,寻找表面层面的模式会导致过度拟合并看到领域内不存在的模式。 随着模型变得越来越强大并且能够产生类似人类的输出,将 LLM 输出解释为潜在的类似人类认知的证据可能变得既诱人又令人担忧。
原文链接:LLM cognition is probably not human-like
BimAnt翻译整理,转载请标明出处