
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
生成 3D 模型可能非常耗时,或者需要大量参考图像。解决这个问题的一种方法是神经辐射场 (NeRF),这是一种生成图像的 AI 方法。 NeRF 会可以用一批你为物体或场景拍摄的 2D 图像有效地构建 3D 表示。这是通过学习已有的图像之间的转换来完成的。这种跳跃(或插值)会生成对象的新视角的图像!
听起来不错,对吧?从一小组图像中,就可以制作 3D 模型!这比标准摄影测量有优势,标准摄影测量需要庞大的图像库来生成一些东西(你需要有每个角度的镜头)。然而,我们一开始就承诺 NeRF 速度很快,但直到最近,情况并非如此。以前,NeRFs 花了很长时间来学习如何将你的一组图像转换成 3D 的东西。
这已不再是这种情况。 Nvidia 发布了其即时 NeRF 软件,该软件利用 GPU 硬件运行必要的复杂计算。这将创建模型所需的时间从几天缩短到几秒钟! NVIDIA 对 instant-ngp 软件的可用性和速度做出了许多激动人心的声明。他们提供的结果和示例非常令人印象深刻:

很难不对此印象深刻——它看起来很棒! 我想看看将其转移到我自己的图像上并生成我自己的 NeRF 模型是多么容易。 所以我决定自己安装和使用这个软件。 在这篇文章中,我将详细介绍尝试的过程和制作的模型, 让我们开始吧!
如果你需要将NeRF生成的3D模型转换为其他格式,例如GLTF等,可以使用NSDT 3DConvert这个在线工具:

1、处理管线
那我们要做什么?
- 我们需要参考视频。 让我们去记录想要 3D 化的东西吧!
- 我们将参考视频转换为静止图像。 这个过程还试图了解我们录像的角度。
- 我们将其传递给
instant-ngp。 然后,这会训练一个 AI 来理解我们生成的图像之间的空间。 这实际上与制作 3D 模型相同。 - 最后,我们要制作一个视频! 在 NVIDIA 制作的软件中,我们将绘制一条路径,让相机环绕模型,然后渲染视频。
我不会详细说明这一切是如何工作的(不过请尽管提问!),但我会提供许多我认为有用的资源的链接。 相反,我将专注于我制作的视频,以及我偶然发现的旅程的一小部分。
2、我的尝试
实话说,我发现很难安装。 虽然说明很清楚,但我觉得当涉及到需要的特定软件版本时,所暗示的回旋余地较小。 使用 CUDA 11.7 或 VS2022 对我来说似乎是不可能的,但我认为是切换回 11.6 和 VS2019 有助于让安装过程继续进行。
我碰到很多错误,例如:CUDA_ARCHITECTURES 对于目标来说是空的。 这是因为 CUDA 不想与 Visual Studio 很好地配合使用。 我真的推荐这个视频和这个 repo,非常有助于搭建整个环境!
除此之外,该过程运行顺利。 提供的 Python 脚本可帮助指导将你拍摄的视频转换为图像,以及将其转换为模型和视频的后续步骤。
3、第一次尝试 :乐高汽车
最初,我试图在办公室里对一辆小型乐高汽车进行 NeRF-ify。 我认为我的摄影技巧有点欠缺,因为我根本无法创造出任何有意义的东西。 只是一个奇怪的 3D 污点。 为什么呢? 好吧,让我们看一下 NVIDIA 为我们提供的示例之一。 注意相机位置:
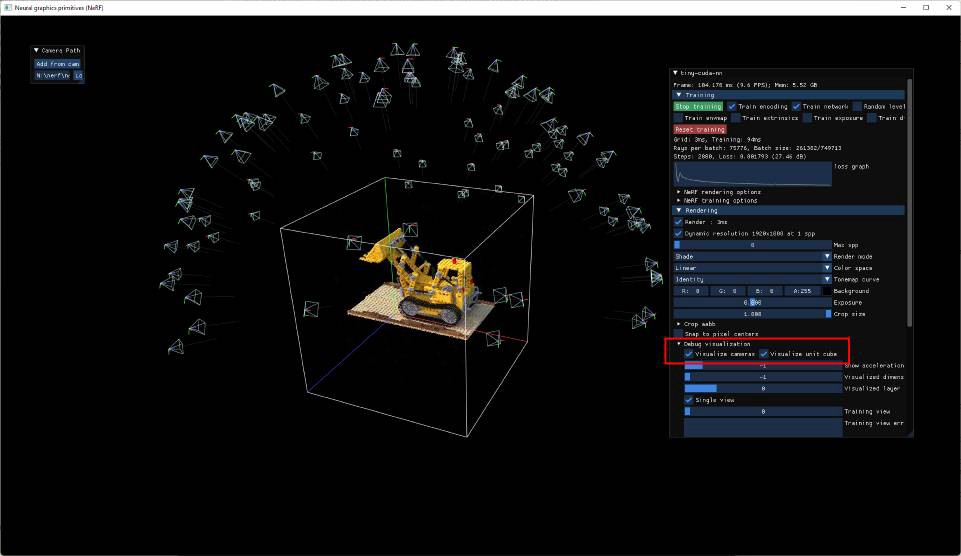
可以进行正确训练的场景设置的一个特点是像上面那样放置“相机”。 这些摄像机是软件认为你在拍摄视频时所面对的角度。 这应该是一个不错的圈子。 我的第一辆乐高汽车根本不是这样的,而是一个压扁的半圆形。
4、第二次尝试 :更大的乐高汽车
为了从第一次尝试中吸取教训,我找到了一张可以围绕其走动的桌子,并找到了一辆更大的乐高汽车。 我也试着确保拍摄时间也比以前更长。 最后,我从各个角度获得了 1 分钟的流畅镜头。 我用不到 30 秒的视频训练模型。 在以 720p 渲染 4 小时后,这是我制作的视频:

5、第三次尝试:植物
第二次尝试 要好一些,至少它在技术上有效。 但是,有一种奇怪的雾气,而且不是很锐利。 对于下一次尝试,我尝试从更远的地方拍摄(我假设雾是由于 AI 对那里的东西“感到困惑”造成的),更多地控制 aabc_scale(衡量场景大小),然后对其进行了几分钟的训练。 渲染后,视频看起来像这样:

好多了! 这里令人难以置信的令人印象深刻的是它如何设法如此准确地渲染钩针编织的花盆和木头上的凹槽,以及复杂的叶子。 看看相机穿过树叶的那个小俯冲!
6、第四次尝试
越来越好! 然而,我想要一个外面的——让我们试试吧。
我在公寓外拍摄了不到 2 分钟的镜头并开始处理。 这对于渲染/训练来说特别笨重。 我的猜测是 aabc_scale 值非常高 (8),因此渲染“光线”必须射出很远(即,我想要渲染的东西的数量更多)。 我不得不切换到 480p 并将渲染 fps 降低到 10(从 30)。 它表明你选择的设置确实会影响渲染时间。 经过 8 小时的渲染,我得到了这个:

我认为第3次尝试的结果最好,我认为可以让 第四次尝试 好一点。 然而,在渲染时间如此之长的情况下,迭代版本并尝试不同的渲染和训练设置是很困难的。 现在即使为渲染设置摄像机角度也很困难,导致程序对我来说变得缓慢。
尽管如此,从短短一两分钟的视频中,我得到了一个细节丰富、栩栩如生的 3D 模型,这是多么惊人的输出!
7、优点和缺点
我认为最令人印象深刻的是,给定 1-2 分钟的镜头,完全没有受过摄影测量训练的人(我)可以创建一个可行的 3D 模型。它需要一些技术诀窍,但是一旦你安装了所有东西,它就会很流畅且易于使用。将视频转换为图像效果很好,提供了 Python 脚本来执行此操作。一旦完成这些,将其输入到 AI 中就会顺利进行。
然而,很难为此指责 NVIDIA,但我觉得我应该提出来:这件事需要一个非常强大的 GPU。我的笔记本电脑中有一台 T500,它将它推向了绝对极限。训练时间确实比宣传的 5 秒长,并且尝试以 1080 渲染会导致程序崩溃(我在 135*74 附近动态渲染)。现在,与之前花费数天的 NeRF 实施相比,这仍然是一个巨大的改进。我不认为每个人都有 3090 可用于此类项目,因此值得简单提及一下。低性能使该程序难以使用,尤其是当我试图“飞行”相机以设置我渲染的视频时。不过,很难不对过程的输出印象深刻。
我面临的另一个问题是找到 render.py(您可能猜到了,它对于渲染视频至关重要)。非常奇怪的是,它不在代码仓库中,尽管在大多数广告文章和其他文档中都被大量提及。我不得不从这里把它挖出来。
最后,我也希望能够将它们提取为 .obj——也许这已经成为可能了?

8、结束语
这让我想到了图像生成人工智能 DALL-E。这已经变得非常流行,部分原因是它很容易访问。它为人们提供了一个非常酷的例子,说明 AI 模型可以做什么,以及它们的局限性。它进入了流行文化(或者至少它在我的推特上占有重要地位),人们制作了自己奇怪的 DALL-E 图像并分享它们。我可以想象这种技术也会发生类似的事情。一个可以让任何人上传视频并创建可以与朋友分享的 3D 模型的网站的病毒式传播潜力是巨大的。最终有人会做到这一点几乎是不可避免的。
就个人而言,我期待着对此进行更多试验。我希望能够生成超逼真的模型,然后将它们转储到 AR/VR 中。你可以在那个空间主持会议——那不是很有趣吗?由于只需要手机上的相机,因此执行此操作所需的大部分硬件已经在用户手中。
总的来说,我印象深刻。能够在手机上拍摄 1 分钟的视频并将其转换为可以逐步完成的模型,这真是太棒了。是的,渲染需要一段时间,而且安装起来有点困难,但效果很好。经过几次尝试,我已经得到了非常酷的输出!我期待着尝试更多!
原文链接:Using AI to Generate 3D Models, Fast!
BimAnt翻译整理,转载请标明出处





