NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
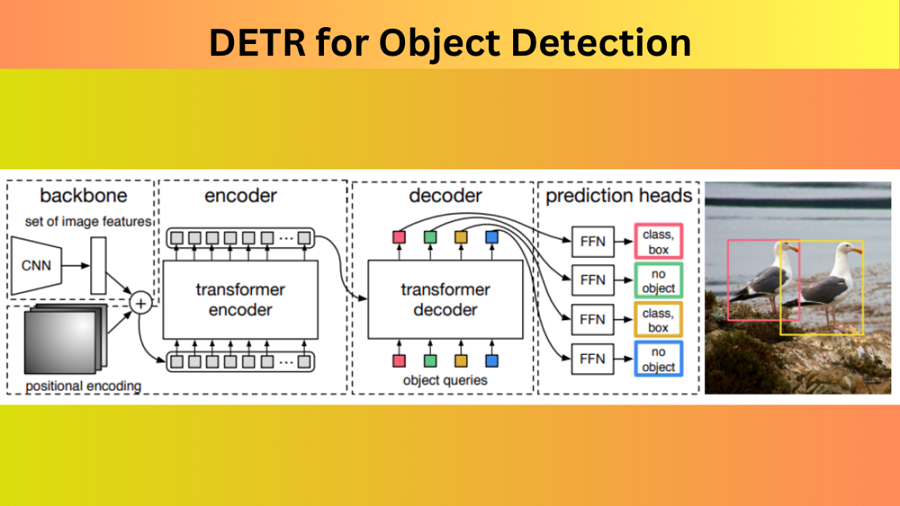
在本文中,我们探索 DETR 对象检测的革命(整个架构如下面所示的交互图所示),这是一种采用 Transformer 和并行解码集预测的独特方法,重新构想了问题陈述,为传统的解决方案带来了替代方案 方法。
我们还揭示了 Carion 等人(2020)如何提出了一种超越旧时代物体检测的利基解决方案。
1、DETR有什么特别之处? 🤔
在一个被手工制作的特征和耗时的过程所困扰的世界中,实验室出现了一种新的架构:DETR,端到端的物体检测器,可以在自己的领域与强大的 CNN 竞争! 通过结合 CNN 和 Transformer 这两个不太可能的父母的优势,DETR 简化了训练过程,告别了繁重的体力工作。
凭借其独特的超强注意力机制,DETR 可以非常准确地识别物体及其关系。
随着这种非凡架构的消息传播开来,实验室开始转向受 DETR 组件启发的更新可能性,从而实现更好的图像分割和对象检测模型。 因此,端到端超级物体检测器 DETR 诞生了。
今天我们将深入探讨它的过去,导致它诞生的因素,以及这个奇迹最初是如何实现的。
2、什么是对象检测? 😯
好吧,对象检测基本上就是通过在对象周围画框并弄清楚每个对象的名称来猜测对象在图像中的位置。

以前的对象检测方法通过创建相关的子问题来解决预测图像中对象位置的问题。 这些子问题涉及使用图像的众多预定义区域、点或中心来估计对象属性。
3、DETR 有什么新功能? 🎁
作者希望我们看到对象检测非常简单,但他们也指出人们过去常常更迂回地处理它。
作者将目标检测视为一个集合预测问题。 集合预测问题是指你尝试根据某些信息猜测一组项目。 可以把它想象成试图根据你的朋友已经看过的电影来找出他们可能喜欢哪些电影。
请注意:将对象检测视为一组预测问题存在一些挑战。 最重要的一个是摆脱重复的预测。 当你完成本教程的其余部分时,请记住这一点。 它将帮助你更好地理解作者为何做出某些选择和决定。
他们的论文主要由两个主要部分组成:
- 一种独特的基于集合的全局损失,它利用二分匹配(一种促进集合预测的算法)来鼓励不同的集合预测。
- 基于Transformer的架构,包括编码器和解码器。
通过将对象检测视为集合预测问题,消除了先前在对象检测任务中需要手动设计的组件来合并先验知识的需要。 这种方法简化了流程并简化了任务。
3、重新想象的问题陈述🧠
了解本文在计算机视觉领域的贡献非常重要。 为了理解这一点,我们首先通过理解过去的对象检测来重新想象问题陈述。 接下来,我们看看作者提出的两种解决端到端对象检测的新方法。 最后,我们看看作者提供的简单解决方案。
- 过去的目标检测(问题陈述)
- 设置目标检测预测(方法 1)
- 用于目标检测的 Transformer 和并行解码(方法 2)
- 一个简单的解决方案(解决方案)
以前的目标检测方法是根据一些初始猜测进行预测的。
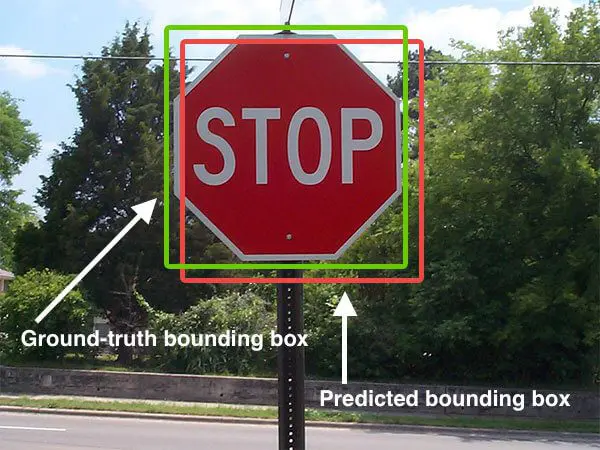
- 两阶段检测器:预测与提案相关的框(如图 1 所示)
- 单级检测器:针对锚点或可能对象中心的网格进行预测(如图 2 所示)

重新想象的问题陈述:预测的质量在很大程度上取决于最初的猜测是如何做出的。 因此,我们需要一种直接预测检测集的方法,而不是使用手工方法。
4、基于几何预测的目标检测🕵️
在图像处理应用中,基本的集合预测任务是多标签分类。 但首先,让我们快速回顾一下多标签和多类的含义。
- 多类:属于多个可能类别中的一类的图像(多类对象检测的示例如图 3 所示)。

- 多标签:同时分配有多个标签的图像(多标签对象检测的示例如图 4 所示)。

多标签分类的基线方法称为一对多。 在这里,我们为每个标签训练一个二元分类模型,然后尝试预测图像中存在哪些标签,哪些不存在。 当然,只有当标签相互排斥时,这种技术才有效。
在对象检测流程中,几乎相同的框非常常见。 这使得上述一对一的方法失败了。 相反,作者使用直接集合预测来实现这种情况下的集合预测。
注意:在直接集合预测中,我们需要一种方法来考虑所有预测元素之间的关系以避免重复。
这就是作者使用匈牙利算法(在本系列即将推出的教程中介绍)的地方,这有助于他们巧妙地将基本事实(实际数据)与他们的预测相匹配。
注意力机制聚合来自整个输入序列的信息。 这些更适合长序列表示。
为了获得信心并更好地理解 Transformer 及其基本原理,我们建议观看视频 1,它提供了 Transformer 的全面概述和直观解释。
让我们暂停并思考一下。 如果我们输入图像,并且对象检测模型并行预测对象(边界框),会出现什么问题?
虽然模型并行输出所有对象,但与自回归方法不同,每个预测不具有所有其他预测的上下文。 这可能会产生两个问题:
- 并行模型输出重复项。
- 并行模型可以每次以不同的顺序输出对象。
5、一个利基解决方案🥳
DETR 通过结合二分匹配随时和transformer来解决其挑战。 匹配损失函数有助于将每个预测与唯一的地面真实对象配对,因此不必担心重复。
此外,二分匹配损失不关心预测对象的顺序,这意味着我们不需要担心预测的顺序。
原文链接:DETR Breakdown Part 1: Introduction to DEtection TRansformers
BimAnt翻译整理,转载请标明出处





