NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
在我的“神经网络直觉”系列文章中,我将讨论构建通用视觉算法的有趣但具有挑战性的领域之一,该算法可以泛化到各种不同的、未见过的任务。 鉴于 GPT-4 模型最近的成功,过去几个月对 NLP 社区来说非常重要,这展示了大型语言模型 (LLM) 的真正力量及其解决确实不属于训练集的新任务的强大新兴能力。
ChatGPT 的最新版本(带有 GPT-4 后端)是多模态的,允许输入和描述图像输入,但对其训练的数据及其重要的架构方面没有太多可见性(我还没有读过 LLaMA -2 论文:)) — 从而使其成为一个黑匣子。 但另一方面,SalesForce 发表了一系列优秀论文,它们擅长各种视觉语言任务,例如图像字幕、视觉问答、图像到文本检索等。
这些论文在共同的框架下——BLIP(引导语言-图像预训练),列出了统一图像和文本特征的新颖方法、具有图像输入和数据集引导的指令调整LLM。 BLIP 系列算法在广泛的视觉语言任务上表现出强大的 SOTA 性能。
让我们深入研究所有这些想法并更好地理解核心概念!
1、BLIP概述
本质上,BLIP 系列始于论文 (1): BLIP - 用于统一视觉语言理解和生成的引导语言图像预训练,引入了一种将图像特征合并到文本中的新颖方法,从而实现了更好的统一视觉和文本表示学习。
接下来,论文(2)。 BLIP-2:使用冻结图像编码器和大型语言模型引导语言图像预训练,引入了一种有效的策略,利用现成的图像编码器和 LLM 进行视觉语言预训练,而不影响这些模型的泛化能力。
最后是最近的论文(3): InstructBLIP:通过指令调优实现通用视觉语言模型,重点关注指令调优方面,并表明指令调优的 LLM 与图像输入相结合,比多任务网络或没有指令调优的单模态/多模态网络表现出更好的零样本能力。
但在直接进入这些论文及其架构细节之前,让我们先退后一步,了解问题是什么以及为什么 BLIP 可以作为相同问题的有效解决方案:)
2、问题陈述
为图像分类、检测、分割等各种视觉任务构建通用计算机视觉模型一直是一个长期存在的问题,至少可以说是一个相当具有挑战性的问题。
在解决这个问题的过程中,出现了许多方法/算法——有些侧重于数据方面,有些则侧重于算法方面。 几年前,一项非常酷的研究将图像和文本特征与对比学习目标联系起来——CLIP,在图像识别方面取得了重大进展(尤其是图像分类/检索)。
CLIP 是最早成功地将文本特征纳入视觉任务(单模态)的论文之一(如果不是第一篇),执行大规模预训练,并在各种未见过的任务上表现出强大的零样本性能。
虽然人们在统一图像和文本特征方面进行了各种尝试(与 CLIP 不同,CLIP 是单模态的,意味着它预训练并独立使用图像和文本特征),但 NLP 也取得了一些重大突破,其中大型语言模型(LLM)表现出了出色的表现 文本生成能力,最突出的是它们泛化到新颖/未见过的输入或任务的能力。
自然地,需要一个统一的视觉和语言框架,最重要的是,需要一个将它们与LLM耦合的框架,使视觉解决方案能够利用LLM强大的泛化能力。
3、BLIP
BLIP 系列是最近提出的众多方法之一,它提出了一个强大而准确的图像文本理解框架,该框架使我们能够得到不需要太多微调的通用视觉模型。
3.1 BLIP的动机
最近有一些方法可以很好地单独处理使用基于编码器的模型(如 CLIP)的图像文本理解(用于检索的多模态表示学习)或使用编码器-解码器模型给定图像的文本生成任务(如图像字幕)。 然而,将基于编码器的模型应用于文本生成任务或将编码器-解码器模型应用于图像文本检索任务还不是很成功。
如果有一个统一的框架可以同时解决图像文本检索任务以及以图像为条件的文本生成任务呢?
准确地说,BLIP 通过定义并行共享分支和擅长视觉语言理解和视觉语言建模任务的多任务预训练目标来解决这个问题。
此外,大多数视觉语言理解任务都利用来自互联网的大规模噪声图像文本对,这是次优的并且会影响准确性。
因此,BLIP还提出了一个Captioner-Filter框架,借助Self-Distillation生成高度准确的合成字幕。
现在我们清楚了 BLIP 正在解决的问题,让我们深入了解为实现它而提出的架构。
- 单模态:仅使用一种模式学习的特征。 例如:分别来自 CLIP 的图像嵌入或文本嵌入。
- 多模台:通过使用多种模式学习的特征。 可以使用图像+文本、文本+音频等。
3.2 BLIP的架构
提议的架构如下:
- 单模态图像和文本编码器,将图像和文本作为输入(分别)并单独生成图像和文本嵌入。
- 一种基于图像的文本编码器,它将文本作为输入(以及通过单模态图像编码器的交叉注意注入的视觉特征)并生成多模态表示(组合图像和文本)。
- 一个基于图像的文本解码器,它接收 [Decode] 令牌(以及通过单模台图像编码器的交叉注意注入的视觉特征)并为给定的输入图像生成文本描述。
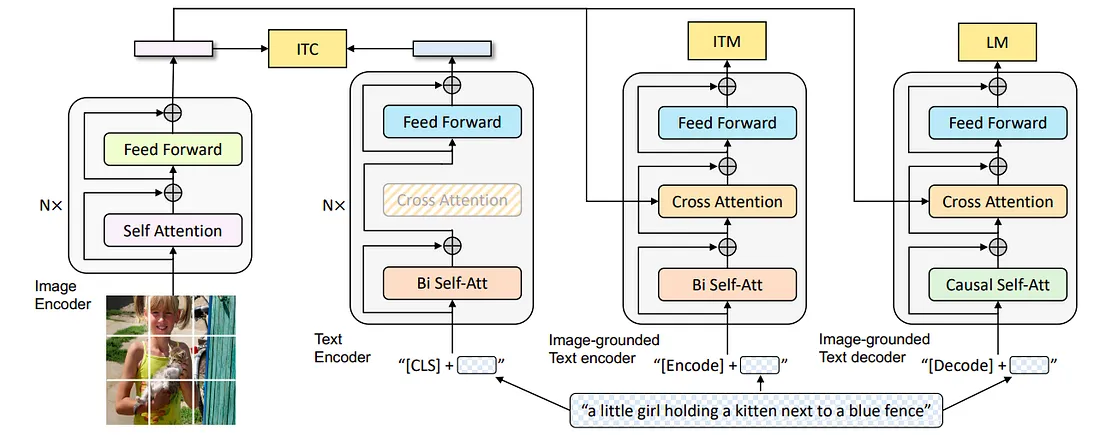
让我们看一下与每个模块相关的预训练目标:
- 图像-文本对比损失(ITC Loss):与 CLIP 类似,编码器被训练为相似的图像和文本对生成相似的表示,并为负输入对生成不同的表示。
- 图像-文本匹配损失(ITM Loss):这有助于文本编码器学习多模态表示,捕获视觉和语言之间的细粒度对齐。 这是一个二元分类任务,其中损失输出 1 表示正图像文本对,0 表示负图像文本对。
- 语言建模损失(LM Loss):该损失帮助文本解码器为相应的输入图像生成文本描述。
所有三个模块都是根据这些预训练目标进行联合训练的。
这里需要注意的一件事是,除了自注意力层之外,所有参数都在文本编码器和解码器之间共享,因为最适合编码和解码任务的表示分别是 SA 层的一部分。
我在阅读这篇论文时遇到的一个问题是“为什么我们需要 ITM 目标,仅仅 ITC 和 LM 损失就足以共同学习有效的视觉语言表示和文本生成模型?”
一种看待方法是,ITM 损失首先有助于实现 ITC 和 LM 目标。 接下来,由于参数在文本编码器/解码器之间共享,ITM 目标强制为语言生成任务提取更多信息丰富的视觉特征。
ITM 的一个缺点是它的计算瓶颈——由于图像和文本嵌入是联合生成的,当涉及到一组图像和文本对的匹配表示时,必须对每一对(1轮/对)进行匹配 并且不能像 ITC 任务那样预先计算。
3.3 图像字幕和过滤(CapFilt)
另一个有助于提高 BLIP 准确性的模块是利用模型的文本解码器块(captioner)和图像文本匹配块(过滤器)协同工作来标记和过滤噪声网络数据并重新训练网络(ITC、ITM和 LM)返回相同的网络数据,这些数据比以前更准确。
简单来说(自蒸馏),
- 使用嘈杂的网络数据+小而准确的人工标记数据进行预训练
- 使用人工标记数据微调 ITC、ITM 和 LM
- 使用 LM 在网络数据上生成更新的标题,使用 ITM 进行过滤,然后再次使用它们来训练你的端到端网络(包含 ITC、ITM 和 LM)。
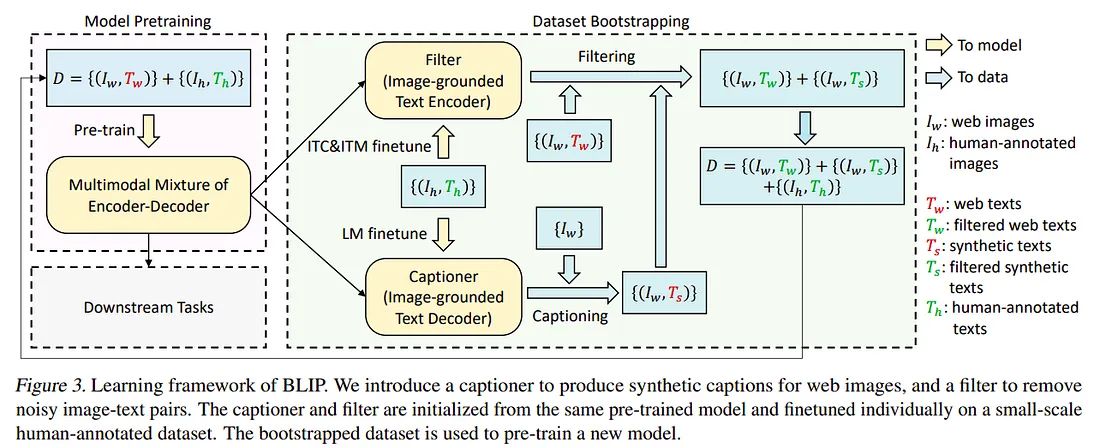
尽管性能可归因于 BLIP 的架构,但 CapFilt 框架显着提高了准确性,并表明不仅大规模数据,更清晰、准确的大规模数据也是关键。
4、BLIP-2
接下来我们看看BLIP-2。
4.1 BLIP-2的动机
在上一节中,我们了解了 BLIP 如何提出高效的架构方案和训练目标来有效训练多模态网络,从而解决视觉理解和文本生成(给定图像)任务。
但是,在大规模数据集上训练此类语言模型时存在挑战,其中此类视觉语言模型(VLM)的预训练特别昂贵。
我们能否使用现成的预训练冻结图像编码器和冻结大语言模型(LLM)并将它们用于视觉语言预训练,同时仍然保留其学习到的表示?
这里需要注意的一件事是,LLM在单模态预训练期间没有看到图像,并且冻结它们使得视觉语言对齐具有挑战性。
BLIP-2 通过引入查询变换器解决了这个问题,该查询变换器有助于生成与文本标题(来自冻结图像编码器)相对应的信息最丰富的视觉表示,然后将其馈送到冻结的 LLM 以解码准确的文本描述。
4.2 BLIP-2的架构
当然,BLIP-2 有助于在查询转换器的帮助下从 冻结的图像编码器(第 1 阶段)引导视觉语言表示学习,并从 冻结的LLM(第 2 阶段)引导视觉到语言生成学习( 或Q-former)。
Q-former 是可训练的模块,它弥补了冻结图像编码器和冻结 LLM 之间的模态差距。
让我们详细看看这两个预训练阶段:)
第一阶段:从冻结图像编码器引导视觉语言表示学习:
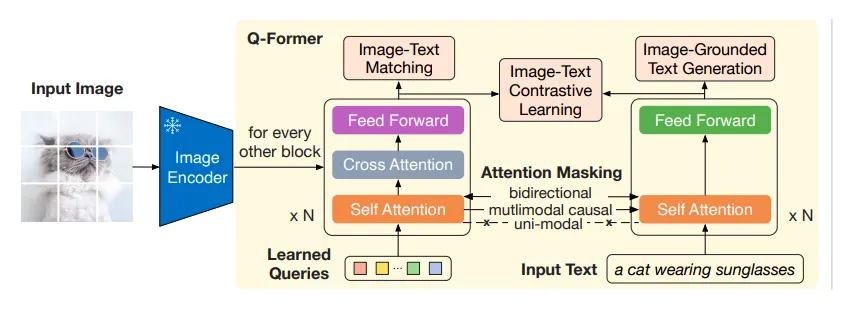
BLIP-2 中的第一个预训练阶段是从冻结编码器中学习丰富的视觉语言表示,这有助于更好的生成学习(在第 2 阶段)。
本质上,流程如下:
- 输入图像通过冻结图像编码器(任何预训练的视觉变换器)。
- Q-former 与冻结图像编码器交互并生成与文本最相关的视觉表示。 Q-former 由图像转换器和文本转换器组成,它们使用与 BLIP 中相同的一组目标/任务(ITC、ITM 和 LM 损失)进行训练,
看待 Q-former 的一种直观方法是提出这样的问题:“如何从已经训练好的视觉编码器中提取视觉特征,以一种通用且计算有效的方式与给定的文本标题更多相关?”
轻量级图像+文本转换器(即 Q-former)通过交叉注意力层和共享自注意力层(跨图像和文本转换器)与冻结图像编码器的特征进行交互,可以过滤出与给定最相关的丰富视觉特征 文本。
第二阶段:从冻结的LLM中引导视觉到语言的生成学习:
现在我们有了一种有效的方法(在计算和准确性方面)从冻结的图像编码器学习视觉语言表示,现在让我们看看生成学习的第二个也是重要的阶段,同时保持(冻结的)LLM的能力。
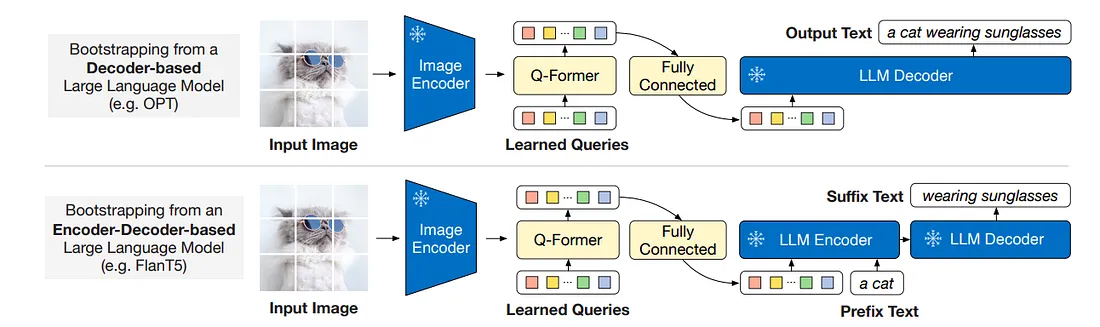
在第二阶段,Q-former 的视觉表示被传递到 FC 层,该层将其投影到与 LLM 输入文本嵌入维度相同的维度。
流程如下,
- 输入:图像,输出:图像的文字描述
- 输入图像通过冻结图像编码器,然后通过 Q-former 的图像转换器输出输出视觉表示 Z。
- 输出图像嵌入被投影到与LLM的文本嵌入相同的维度。
- 然后将投影的查询嵌入添加到输入文本嵌入之前。 它们起到软视觉提示的作用,使LLM以 Q-Former 提取的视觉表示为条件。
- 训练两种LLM:A - 基于解码器生成以 Z 为条件的文本(使用语言建模损失);B - 基于编码器-解码器——视觉嵌入被添加到文本嵌入之前,然后进行调节以生成文本(使用前缀语言建模损失)。
在第 2 阶段,Q-former 与投影层一起进行端到端训练(保持图像编码器和 LLM 冻结)。
现在出现了一个关键问题:“引入整个 Q-former 模块是为了利用预训练图像编码器和 LLM 的泛化能力。 他们有帮助吗?
事实上,作者做出了一个有希望的观察,即更强的图像编码器或更强的 LLM 都会带来更好的性能,并且实际上在多项任务上击败了之前的 BLIP 架构。
这太酷了! 这使得其他人能够重用大规模训练的开源模型(无论是视觉还是语言模型),并在特定领域的数据上对其进行微调,从而保留以前模型的泛化能力。
那么,如果第二阶段是生成预训练(这就是我们想要的),那么为什么首先要有第一阶段呢?
正如论文中提到的,第一阶段表示学习对 QFormer 进行预训练,以学习与文本相关的视觉特征,这减轻了 LLM 学习视觉-语言对齐的负担。 没有表示学习阶段,Q-Former 仅依靠视觉到语言的生成学习来弥合模态差距,这类似于 Flamingo 中的 Perceiver Resampler。
5、Instruct-BLIP
让我们从 BLIP/BLIP-2 方法退后一步,看看由LLM支持的聊天机器人的最新趋势。
5.1 Instruct-BLLIP的动机
我们看到LLM在纯文本数据(输入和输出)方面表现出零样本泛化,而指令调整则大大提高了其零样本能力。 例如:GPT3.5、GPT-4、LLaMA-2 等。
当涉及视觉任务,特别是视觉语言任务时,到目前为止,我们看到了两种主要方法:
- 一种使用联合表示学习的方法
- 另一个将LLM与 ViT 结合使用,例如 BLIP-2、Flamingo。
因此,需要一个处理多种模式的指令调整框架:文本和图像。 这是构建通用视觉识别模型的关键步骤。
什么是指令调优? 这与包含图像、文本对的图像字幕或视觉问答有何不同?
指令调整(在 VLP 中)是关于以类似对话的方式构建图像文本数据(无论是图像字幕还是 VQA)。 InstructBLIP 列出了一组指令模板,这些模板是为涉及预定义格式的问题和答案的每个任务制定的。
InstructBLIP 使用与 BLIP-2 相同的架构,因为它由冻结图像编码器、冻结 LLM 和 Q-former 组成,用于提取信息丰富的视觉特征。 文本——这里的文本是指令格式,而不仅仅是简单的标题。
如果仔细观察 BLIP-2 的工作原理,就会发现它的行为有点类似于接收图像并生成一些说明文字的聊天机器人,但是如何才能使其行为像可以读取图像的实际聊天机器人呢?
相对于 BLIP-2 的又一改进是以指令的形式构建数据,并且还使 Q-former 能够生成指令感知视觉提取,这有助于它根据输入指令进行泛化和适应。
5.1 Instruct-BLIP的架构
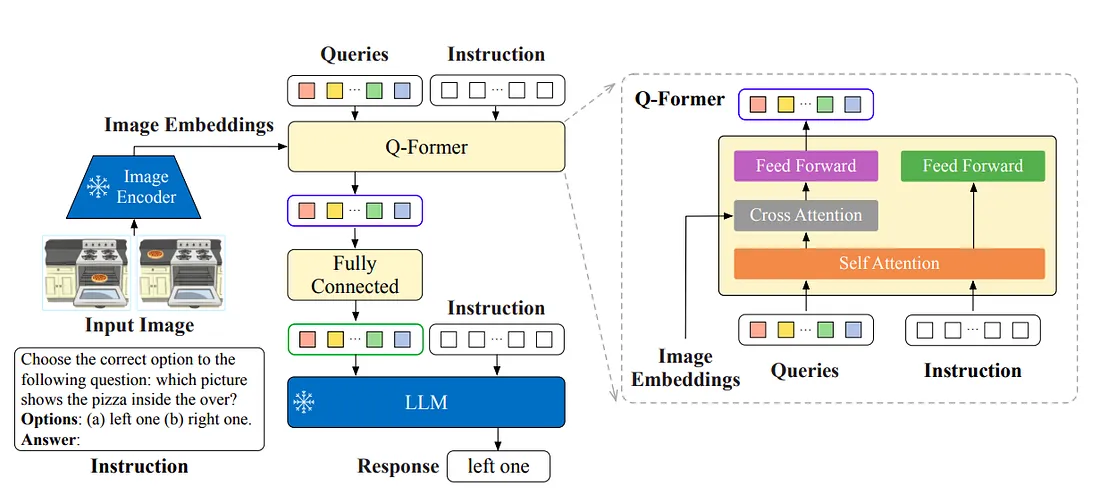
正如我们所看到的,InstructBLIP 与 BLIP-2 非常相似,但数据集被构建为基于指令,并且相同的指令也被输入到 Q-former 以产生指令感知的视觉表示。 具体来说,文本指令不仅提供给冻结的 LLM,还提供给 Q-Former,以便它可以从冻结的图像编码器中提取指令感知的视觉特征。
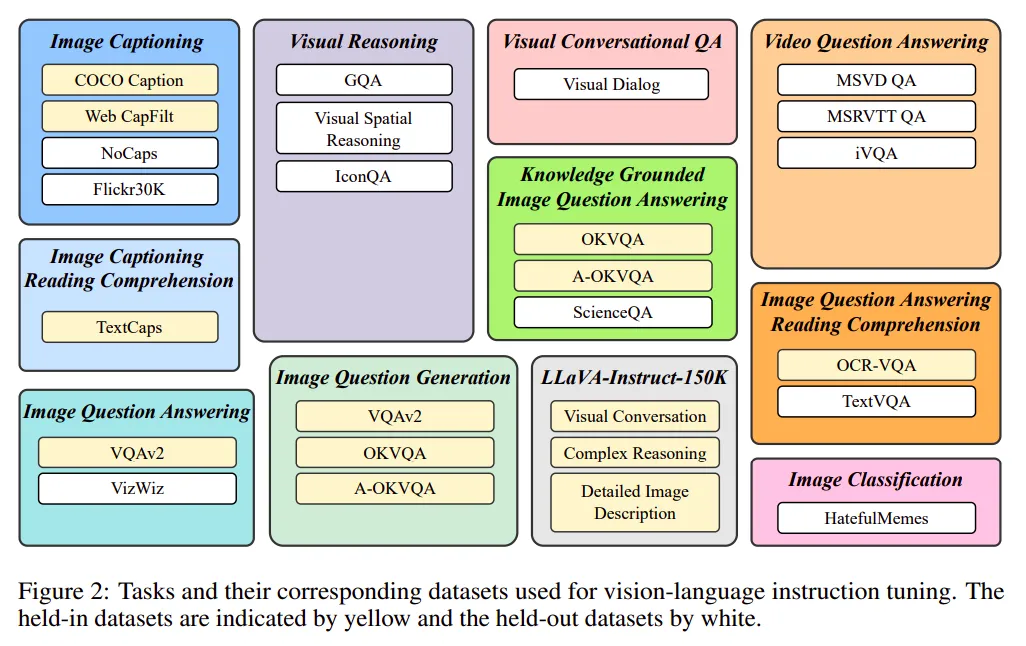
5.2 使用的数据集
5.3 与BLIP-2和Flamingo的比较
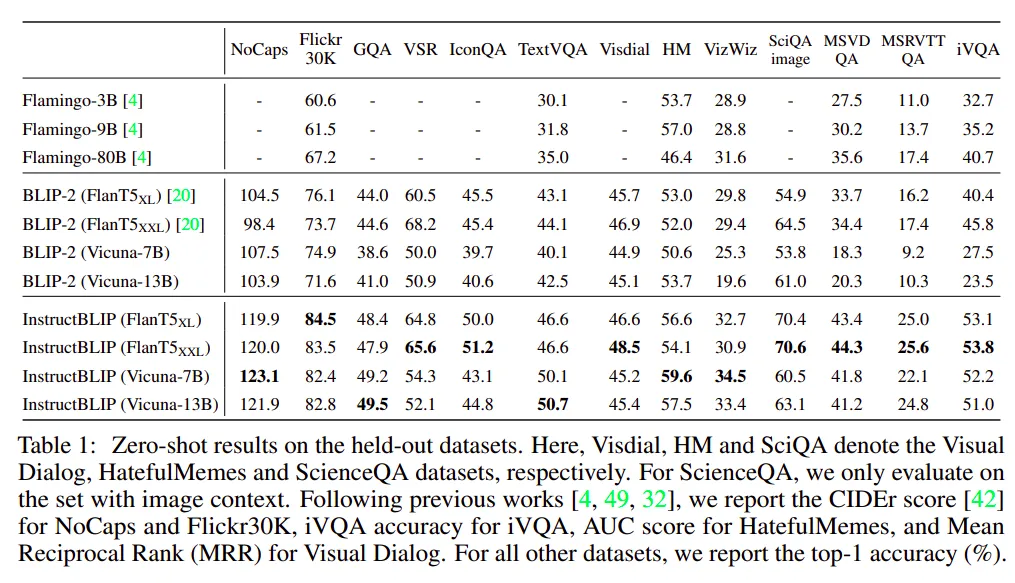
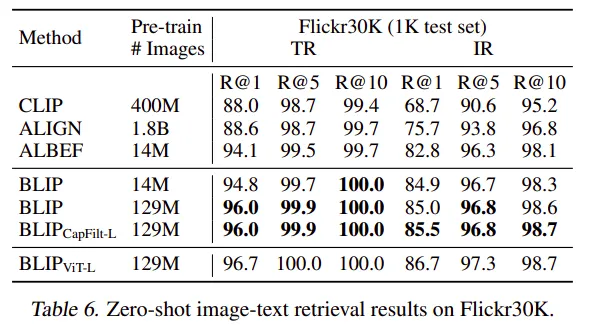
正如我们在上表中看到的,指令调优肯定有助于提高零样本泛化能力。
5.4 其他使用指令调整的LLM
该论文还引用了几种指令调整的视觉语言模型,例如 MiniGPT、LLaVA、mPLUG-owl、MultiInstruct,它们也产生了与 InstructBLIP 相当的结果。
6、结束语
BLIP/BLIP-2/InstructBLIP 在图像文本检索任务上显示了一些强大的结果,特别是在零样本设置下的性能。
根据 BLIP 下的系列论文,我想强调的两件事是,
- 使用语言和侧面图像来推动通用视觉算法的发展。
- 重要的不仅仅是数据的规模,还包括数据的清洁程度(CapFilt)以及以指令的形式向其提供数据(InstructBLIP 中的指令调整)。
正如我们所看到的,不仅像 VLM 这样的模型帮助我们转向通用视觉算法,而且围绕图像修复的一些有趣的研究(例如:Painter、SegGPT、PersonalizeSAM)也在兴起。
原文链接:Neural Networks Intuitions: 17. BLIP series — BLIP, BLIP-2 and Instruct BLIP— Papers Explanation
BimAnt翻译整理,转载请标明出处