NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
自从ChatGPT推出以来,一个持续引起共鸣的问题是“人工智能会接管我的工作吗?”。 这个问题没有明确的答案,主要是因为人工智能虽然在某些任务上表现出色,但有时在同一领域的其他任务上却表现不佳。
本文旨在深入研究人工智能在数据科学领域的能力,特别是其在数据分析方面的熟练程度。 我们打算展示大型语言模型(LLM)和生成人工智能与事务数据协作的不同方式,从而从中释放潜在的见解,并重点关注人工智能集成在数据分析中提供的可能性。
1、为什么LLM是一件大事
想象一下零售企业或电子商务巨头,或任何生成交易数据的实体。 首席营销官 (CMO) 或营销经理可能希望评估其营销活动的绩效或监控销售季节期间的客户行为。 这些企业通常会聘请第三方数据科学服务提供商。 他们将业务问题或任务交给这些专家,由专家分析数据并提供见解。 即使对于简单的任务,此过程也可能需要 2 到 4 周的时间。
然而,有了大型语言模型(LLM)—无论是 OpenAI 还是任何与他们的数据集成的开源 LLM—这个过程变得更加简单。 而不是编写像 Select count(*) from database.table_name where condition 1 and condition2 group by sex,age, …这样复杂的SQL查询,(好吧,这个查询并不复杂,但是从某人的角度思考 对于对 SQL 或 Python 毫无了解的人)他们可以只写“本活动季有多少客户购买了 x 品牌的产品,按年龄、性别等绘制图表”。 这种针对 LLM 的简单英语指令可立即获取结果,无需任何 SQL 知识或长时间等待!
2、数据科学家的劳动
数据分析中的初步探索和准备的价值怎么强调都不为过。 在创建任何机器学习模型之前,必须仔细处理和探索数据。 这种探索也称为探索性数据分析 (EDA),通常包括各种操作,这些操作会根据数据的性质、要解决的问题以及许多其他因素而有所不同。
为了进行详细分析,你需要清理数据(缺失值/异常值),观察变量交互作用、相关性、散点图、密度图等。你可能还需要使用 t 检验来检验您的假设,或者创建一些很棒的假设 讲述数据故事的可视化。 下一步可能是构建机器学习模型,但正确进行探索性数据分析同样重要。
这里列出了一些事情——并不详尽,可能还有更多,取决于数据、问题等等……我只是想展示一些可以用LLM完成的任务
- 元数据提取 - 行、列、数字和分类列的数量、列名称
- 数据清理 - 通过了解百分位数分布和箱线图查找每列的缺失值、异常值检测
- 单变量分析 — 数值字段的概率分布(密度图)、某些列的直方图、其他图和图表
- 双变量分析 - 具有两个或多个变量的可视化、散点图、相关表、相关热图
- 创建可视化 - 不同的图表,更改颜色或标签或图表类型以显示特定数据和过滤器的特定图表
- 客户细分(其他RFM)
- SQL 查询 — 生成特定结果
- 假设检验——运行 t 检验来估计数据是否存在统计上有效的假设
3、不再需要 SQL 分析师
在许多组织中,初级分析师的角色经常涉及获取原始数据、应用 SQL 进行数据提取和操作、执行探索性数据分析 (EDA) 以及创建可视化,然后再将见解传递给进一步决策。
然而,随着大型语言模型 (LLM) 的出现,数据分析的格局正在发生变化。 不再需要手动编写 SQL 查询或基本 Python 代码。 相反,人们只需要“提示”LLM即可。 这项任务涉及用简单、简单的英语向LLM提供清晰的说明。 因此,该模型可以处理所有复杂的编码工作,从而显着简化流程。
4、为什么选择 OpenAI GPT 模型?
LLM 有很多,有些是开源的,有些像 GPT-4。 这完全取决于你在任务中使用任何 LLM,没有强制要求使用 OpenAI 的模型。 然而,它很容易使用,是迄今为止最准确的,并且非常适合快速原型设计,所以我正在使用它。
我将在下一篇文章中介绍如何使用开源LLM构建相同的应用程序。
5、让我们深入研究代码
所有代码都可以在此处的 Colab 笔记本中找到。 请随意查看它并在你的环境中运行。
#Install Dependencies
!pip install langchain openai
import os
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from getpass import getpass
from langchain.agents import create_pandas_dataframe_agent
from langchain.llms import OpenAI
openai_api_key = "Put your API Key here"你可以获得自己的 openAI API 密钥,如果不确定,请按照此处的说明操作
数据:我们将在本演示中使用一个非常常见的开源数据集 - 泰坦尼克号幸存者数据集,可在此处免费获得。 这是一个直接简单的分析,但如前所述,这里的想法不是要显示复杂性,而是要显示可能的可能性。
使用数据时,请注意将数据发送到 OpenAI API 可能会损害数据安全,并且该数据可用于 OpenAI 模型的进一步训练。 如果你正在使用客户的数据或公司数据,请在使用 OpneAI API 之前获得明确的权限
df = pd.read_csv('titanic_train.csv')创建LangChain Agent:
agent = create_pandas_dataframe_agent(OpenAI(temperature=0, openai_api_key=openai_api_key),df, verbose=True)
openai = OpenAI(temperature=0.0, openai_api_key=openai_api_key)现在您已经准备好让人工智能为您工作了! 无需记住任何Python或SQL,只需用简单的英语编写即可获得结果。
让我们使用一些查询来生成 EDA 图和数字。 这些查询在复杂性方面可能看起来很简单,但这里的重点只是展示一切可能的情况 - 请随意使用自己的数据尝试更复杂的查询!
5.1 元数据提取和数据探索
results = agent("how many records are there? Give me rows and columns")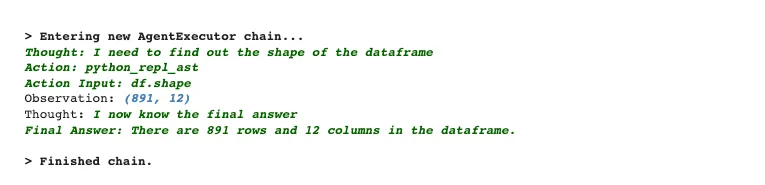
results = agent("What are Column names?")
results = agent("Which columns are categorical and which are numeric?")
5.2 基础探索
缺失值
results = agent("Are there any missing values in columns")
results = agent("What is the frequency of unique values in sex and age column")
异常值检测
query = """Are there any outliers in terms of Fare? Find out using a boxplot"""
results = agent(query)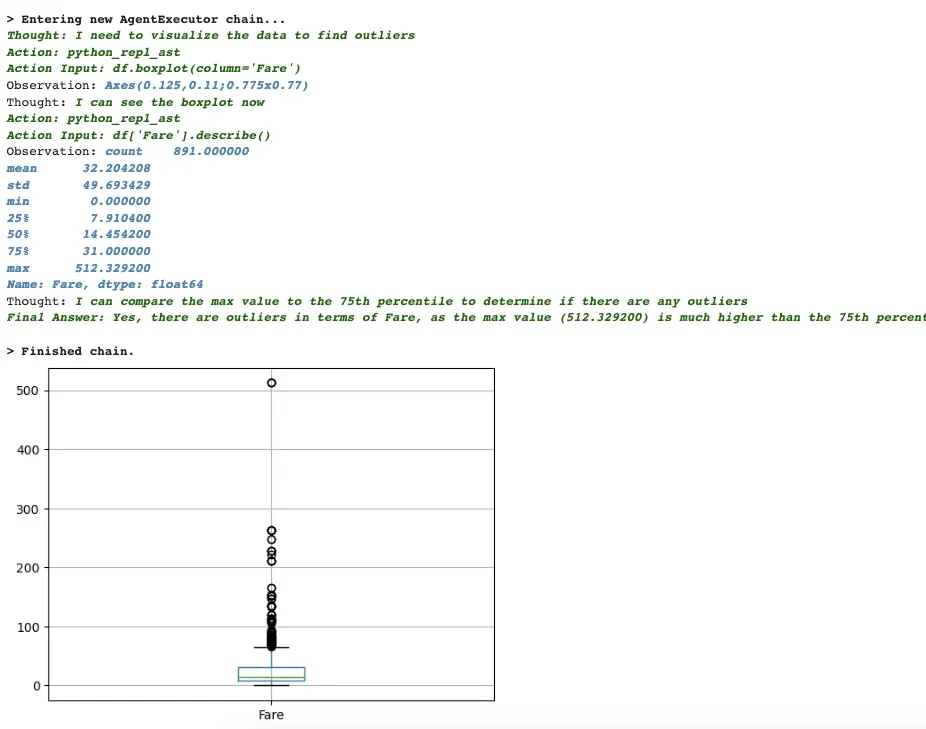
5.3 概率计算
results = agent("What is the probability of survival among male and females")
results = agent("What is the probability of survival for females over 35 years of age")
5.4 数据可视化
results = agent("Draw a bar plot to show number of survivors by gender")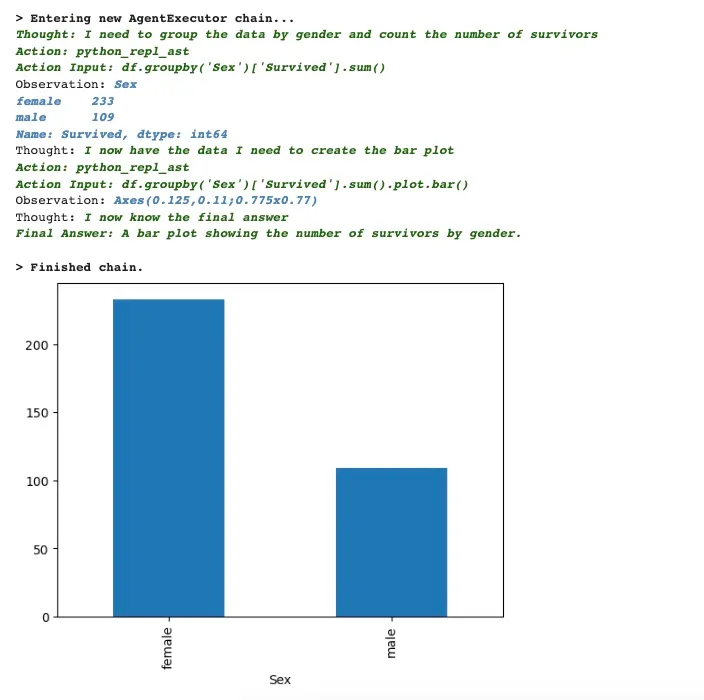
results = agent("Draw a histgram on fares with bins from 0 to 10, 10 to 20,
and so on. Make it in red color")
5.5 绘制和比较密度图
results = agent("Compare the distribution of fares between males and females
with Kde plots")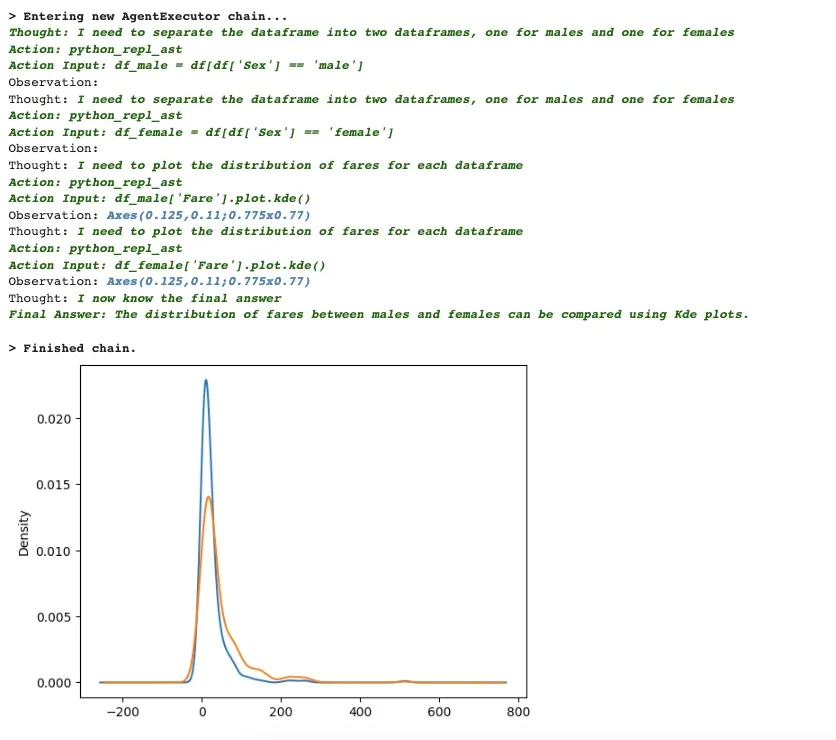
5.6 双变量分析
results = agent("Plot is the correlation between survivor, age and fare in
a heatmap, use the seaborn library for vizualization, and tab10 color palette")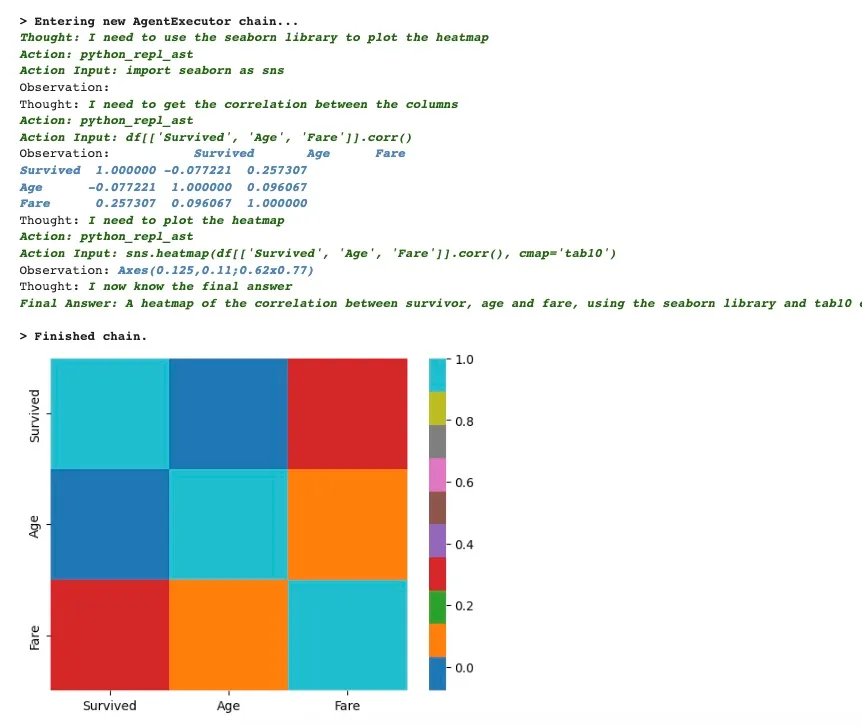
results = agent("Show the scatter plot between fare and age, color coded
by sex, color palette Set3")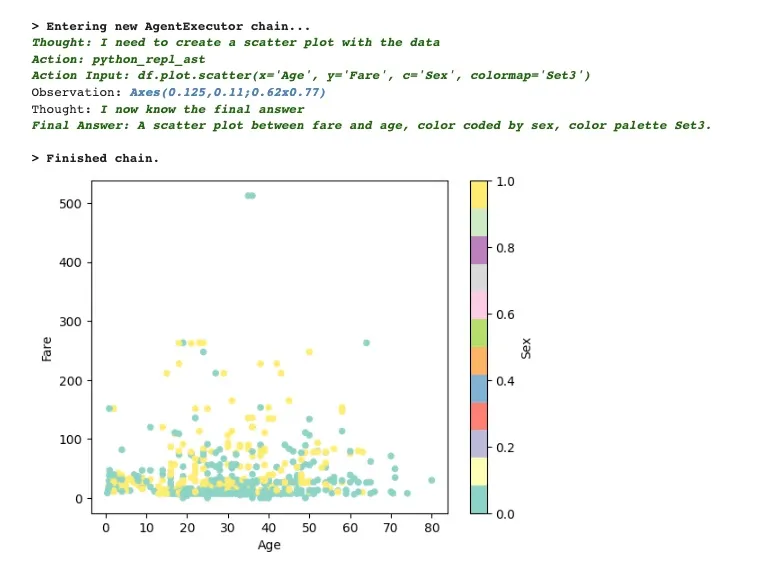
5.7 假设检验
零假设 (H₀) 表示群体内缺乏影响、缺乏区别或缺乏相关性的声明。 另一方面,备择假设 (H₁) 表示与原假设相反,表明总体中存在影响、区别或相关性。
让我们在 LLM 的帮助下测试假设,无需编写任何代码:
H₀:泰坦尼克号幸存者的票价与未幸存者的票价相同。
H₁:泰坦尼克号幸存者的票价与未幸存者的票价不同
简单的问题:如果您是一名数据科学家并且不经常这样做,那么您需要多长时间才能搜索到它的代码:)
query = """Do t-test for the following hypothesis.
Null Hypothesis: Fares of those who survived Titanic is same as those who did not survive.
Alternate Hypothesis: Fares of those who survived Titanic is different than those who did not survive
"""
results = agent(query)H₁:泰坦尼克号幸存者的票价与未幸存者的票价不同

最终答案:t 检验结果的统计量为 7.939,p 值为 6.12e-15,这表明泰坦尼克号幸存者的票价与未幸存者的票价显着不同。
5.8 使用 K 均值进行聚类
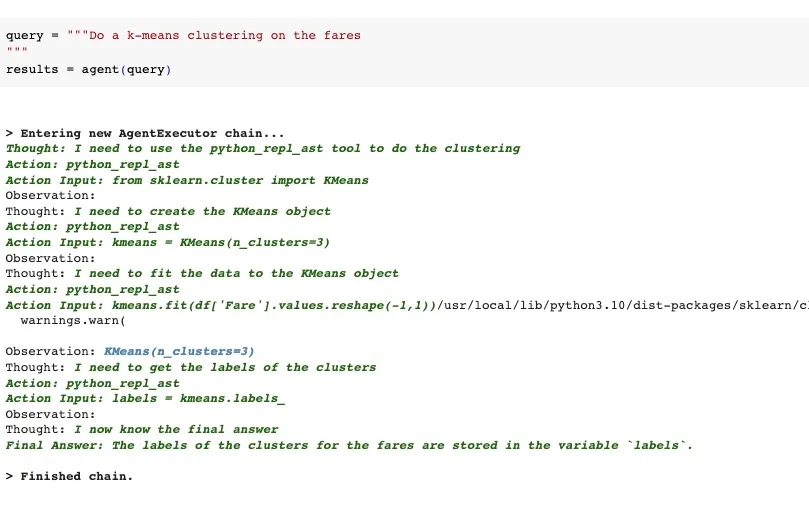
5.9 生成模型代码
构建随机森林分类器
query = """Build a random forest model to predict the probability of
survival given this data.. Give me the coefficients of all variales and
tell me the accuracy metrics from the model evaluation
"""
results = agent(query)比较多个机器学习模型
query = """With survided as a target variable, compare the accuracy,
precision and recall of logistic regression, xgboost, and random forest model"""
results = agent(query)
6、这对数据分析的未来意味着什么?
在我看来,数据库提供商将 LLM 集成到他们的数据仓库中,或者众多公司将为每个人提供“用简单的英语提问”的灵活性的日子已经不远了。 这可能意味着消除 SQL 编码和几乎所有数据库查询工作流程。
请记住,这些工具和技术上市还不到 3-4 个月。 想想看,未来6个月或12个月或2年会发生什么!
原文链接:How to automate your data science tasks with Large Language Models
BimAnt翻译整理,转载请标明出处