
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
经典的空间查询是查找空间要素的最近邻居。 我们之前的文章“你愿意做我的邻居吗?快速找到附近的人”从 PostgreSQL 的角度讨论了这个功能。 Postgres 的 PostGIS 空间数据扩展还可以高效地执行最近邻查询。
在这篇文章中,我们将更深入地研究 Postgres 和 PostGIS 的内部结构,以了解其实际工作原理。 当我们浮出水面时,你将更好地了解 Postgres 的先进技术能力和无与伦比的可扩展性。
1、准备潜水
回顾一下,问题是从一组空间特征中找到给定目标特征的最近特征或 K-最近特征。 这样做的明显方法是计算每个候选特征到目标特征的距离,然后选择 K 最小距离。 同样显而易见的是,如果候选者的数量很大(对包含数百万个特征的数据集运行查询是很常见的),这将非常缓慢。
在 PostGIS 中,空间要素作为记录存储在表中,要素位置存储为几何或地理类型的列。 ST_Distance 函数计算几何之间的距离。 因此,使用上面的朴素方法,查询可以写成:
SELECT name, ST_Distance(ST_MakePoint(-118.291995, 36.578581 ), geom) AS dist
FROM geonames
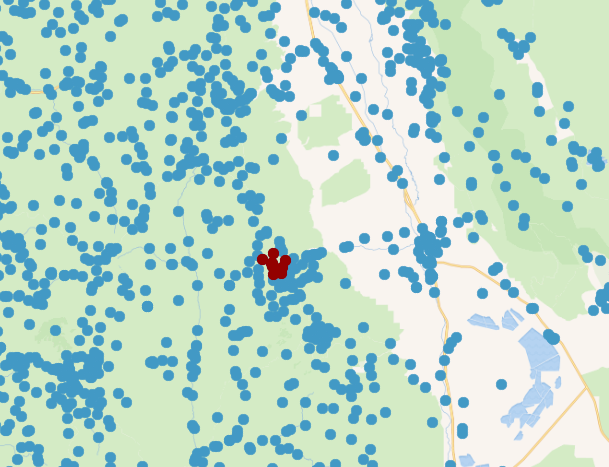
ORDER BY dist LIMIT 10;此查询针对包含超过 200 万个要素的地理名称位置表执行。 它正在搜索距离加利福尼亚州惠特尼山顶峰最近的 10 个名字。 正如预期的那样,它不是特别快,大约 14 秒即可完成。 下表和地图显示了查询结果(距离以米为单位):
name | dist
----------------------+--------------------
Mount Whitney | 11.247614731387534
Sierra Nevada | 127.29084391848636
Keeler Needle | 467.97664454275554
Crooks Peak | 482.3234106159308
Mount Russell | 1267.654254211147
Pinnacle Ridge | 1414.1558235265738
Arctic Lake | 1475.471505754701
Mount Muir | 1549.5739171031566
Upper Boy Scout Lake | 1684.333541189354
Wotans Throne | 1760.0677063194435
(10 rows)
查询计划确认了性能低下的原因:查询引擎正在执行表扫描和排序以找到最近的特征。
Limit (cost=56032553.10..56032553.12 rows=10 width=28) (actual time=14252.326..14252.330 rows=10 loops=1)
> -> Sort (cost=56032553.10..56038147.05 rows=2237580 width=28) (actual time=14252.324..14252.325 rows=10 loops=1)
Sort Key: (st_distance('0101000020E61000001DE6CB0BB0925DC0228B34F10E4A4240'::geography, geom, true))
Sort Method: top-N heapsort Memory: 26kB
-> Seq Scan on geonames (cost=0.00..55984199.80 rows=2237580 width=28) (actual time=3.719..13135.246 rows=2237580 loops=1)
Planning Time: 0.243 ms
Execution Time: 14252.413 ms在存在空间索引的情况下,PostGIS 最近邻支持允许将查询编写为:
SELECT name, geom <-> ST_MakePoint( -118.291995, 36.578581 ) AS dist
FROM geonames
ORDER BY dist LIMIT 10;这提供了相同的结果,但性能要好得多。 它在 7.8 毫秒内执行 - 几乎快 1800 倍! 查询计划确认正在使用 GIST 索引 geonames_gix:
Limit (cost=0.41..3.85 rows=10 width=28) (actual time=5.896..7.533 rows=10 loops=1)
-> Index Scan using geonames_gix on geonames (cost=0.41..769145.06 rows=2237580 width=28) (actual time=5.893..7.523 rows=10 loops=1)
Order By: (geom <-> '0101000020E61000001DE6CB0BB0925DC0228B34F10E4A4240'::geography)
Planning Time: 0.184 ms
Execution Time: 7.768 ms对于这种看似很小的 SQL 更改,这是一个显着的改进。 但它提出了一些问题:
- 什么是“<->”语法? (它看起来肯定不像标准 SQL!)
- 显然“<->”计算了两个几何之间的距离,但这如何使用索引来使最近邻搜索更快?
- 如何在 ORDER BY 子句中使用带“<->”的表达式?
- 像 PostGIS 这样的扩展如何能够使用 Postgres 提供的最近邻搜索?
在接下来的部分中,我们将深入探究以回答这些问题并揭开最近邻搜索机制的神秘面纱。
2、继续前进
首先,“<->”语法是一个运算符。 可以将运算符视为“速记函数”,用于从具有一个或两个参数的表达式计算新值。 我们熟悉许多不同类型的运算符,主要来自算术。 Postgres(和所有其他 SQL 数据库)提供了这些运算符,使编写计算表达式变得容易和熟悉。
一些操作符不仅仅是计算值——它们被查询规划器识别并触发索引系统的使用。 一个明显的例子是比较运算符,例如“=”、“>”和“<”。 查询计划器识别何时在 WHERE 子句中使用这些运算符,并且可以构建使用索引来提高性能的查询计划(如果存在合适的索引(通常是 B 树))。 请注意,这些运算符都返回一个布尔结果。 Postgres 调用这些搜索运算符,因为它们确定如何搜索索引以确定给定行(或在连接情况下的行组合)是否包含在查询结果集中。
3、进入深处
到目前为止,每个 SQL 数据库都以类似的方式工作。 但是 Postgres 从一开始就被设计成几乎在每个方面都是可扩展的。
最常见的扩展是定义新的数据类型来表示不同种类的数据。 由于关系数据库的一个关键任务是使用索引来高效地查询数据,因此 Postgres 提供了多种用于数据访问的索引方法。 其中包括著名的 B 树索引,以及特殊用途的索引,如 GIST、GIN 和其他几个。
查询规划器需要知道何时以及如何在针对新数据类型的查询中使用索引。 这是通过允许为给定的数据类型和索引方法的组合定义新的运算符来实现的。
运算符绑定到计算运算符表达式值的函数。 它们还提供元数据,帮助查询规划器在更多情况下应用索引。 一个数据类型和索引方法的运算符集合称为一个运算符类(通常缩写为opclass)。注意,这意味着一个运算符符号(如“=”)可能被重载,即映射到许多运算符 不同的opclass; 规划器使用参数的数据类型来确定调用哪一个。
Opclasses 还定义了支持例程。 这些例程是索引方法和数据类型之间的接口。 它们由索引实现调用以返回有关数据类型值的信息。 在评估多个不同的运算符期间可能会调用单个支持例程,因此每个运算符都分配有一个策略编号,该编号将传递给支持例程以指示正在使用哪个运算符。 性能是这里的关键,所以这些例程是用 C 语言编写的,C 语言是 Postgres 的核心语言。
至此,我们已经展示了 Postgres 扩展框架如何支持定义新的数据类型和运算符,并将它们绑定到索引方法。 在 2010 年之前,只有搜索运算符可用,只允许标准布尔过滤。 一个聪明的开发团队发现了一种增强框架以支持最近邻搜索的方法。 他们提议修改 GIST 索引方法以允许这样做。 GIST(Generalized Index Search Tree)本身就是一个可扩展的索引方法框架。 它支持为需要超过一维B树索引的数据创建多种不同类型的索引。 因此,这一更改可能会使许多不同的数据类型受益。
修改包括添加使用最佳优先搜索查询索引的搜索策略,以及称为距离的新支持例程。 索引树中的节点按照它们与搜索值的潜在距离的顺序进行搜索。 主动搜索节点保存在按距离排序的优先级队列中,以便首先找到附近的节点和值。 Roussopoulos 等人在 1995 年题为最近邻查询的论文中对此进行了详细描述。 这种策略提供了出色的性能,因为可以快速找到附近的值,而通常永远不会检索到远处的值。
为了允许查询使用这种新的搜索策略,创建了排序运算符的概念。 “<->”等排序运算符计算数据类型值之间的距离。 当排序运算符出现在 ORDER BY 子句中时,规划器知道使用为该运算符定义的数据类型调用最近邻搜索。 与所有基于索引的查询一样,最近邻搜索从索引中读取值流。 多亏了最佳优先搜索,这些值是按距离递增的顺序提供的。 因此,当提供 LIMIT 子句时(通常是这种情况),实际上只会检索所需数量的值。
最近邻增强功能于 2011 年在 Postgres 9.1.0 中发布。 由于它基于 GIST,因此初始版本能够为几种不同的数据类型提供最近邻支持,包括内置点类型和用于使用三元组进行文本匹配的 pg_trgm 类型。
4、提升 PostGIS
综上所述,我们可以展示 PostGIS 扩展如何使用此框架。 PostGIS 定义数据类型来表示空间数据。 下面我们讨论几何数据类型; 地理类型以类似的方式工作。 geometry 数据类型使用称为 R 树(“范围树”)的空间索引。 R 树允许索引在 2 个(或更多)维度中定义的数据值。 PostGIS R 树索引是使用 GIST 框架定义的,因此能够利用 GIST 支持的最近邻搜索功能。
第一个定义是 <-> 运算符。 它绑定到函数 geometry_distance_centroid 以计算几何之间的距离值:
CREATE OPERATOR <-> (
LEFTARG = geometry, RIGHTARG = geometry,
PROCEDURE = geometry_distance_centroid,
COMMUTATOR = '<->'
);名称 geometry_distance_centroid 是遗留的 - 该函数实际上计算几何值之间的精确距离。运算符定义提供元数据以帮助规划者构建计划 - 在这种情况下,距离函数是可交换的(因此参数可以 在不改变答案的情况下被逆转)。
为了允许几何数据类型使用 GIST 索引方法,PostGIS 定义了一个名为 gist_geometry_ops_2d 的操作类。 opclass 包含各种操作符。 最常用的是 && 运算符,这是一种允许使用 R 树索引定位空间对象的搜索运算符。 所有这些都在 DDL 中为 opclass 定义指定,它的开头如下:
CREATE OPERATOR CLASS gist_geometry_ops_2d
DEFAULT FOR TYPE geometry USING GIST AS
STORAGE box2df,
OPERATOR 1 <<,
OPERATOR 2 &<,
OPERATOR 3 &&,
...<-> 距离排序运算符在 opclass 中定义如下:
OPERATOR 13 <-> FOR ORDER BY pg_catalog.float_ops所需的 GIST 支持例程也在 opclass 中定义,包括最近邻居的例程:
FUNCTION 8 geometry_gist_distance_2d (internal, geometry, int4)8 是 GIST 距离支持例程的 ID,geometry_gist_distance_2d 是计算几何之间距离的 PostGIS C 函数。 为运算符指定的 float_ops 数据类型指示距离函数返回值的排序语义。
这就是所有需要的。 Postgres 查询规划器现在可以识别当 <-> 用于 ORDER BY 子句中的 PostGIS 几何值时,查询计划可以使用使用 GIST R 树索引的最近邻搜索策略。
最近邻搜索还有另一方面。 使用单个目标数据值执行搜索。 这意味着 NN 搜索本身并不是一种连接表的方式。 那么如何指定一个查询来从另一个表中找到一个表中许多要素的最近邻域呢? 这就是最近对 LATERAL 子查询的支持可以派上用场的地方。 它本质上充当一个循环,允许查询许多特征以寻找它们最近的邻居。 使用 LATERAL 的典型查询如下所示:
SELECT loc.*, t.name, t.geom
FROM locations loc
JOIN LATERAL (SELECT name, geom FROM geonames gn
ORDER BY loc.geom <-> gn.geom LIMIT 10) AS t ON true;5、回到表面
这完成了我们对 PostGIS 中最近邻搜索深度的探索。 这是下降的潜水笔记:
- Postgres 扩展通过定义一个带有运算符和支持例程的操作类来通知查询规划器如何使用索引,绑定到数据类型和索引方法
- 从 Postgres 9.1 开始,添加了一个框架来为索引方法提供执行最近邻查询的能力
GIST 索引方法使用最佳优先搜索策略高效地执行最近邻搜索 - PostGIS 使用此框架和 R 树空间索引为其空间数据类型的最近邻查询提供出色的性能
- 将 Postgres 与其他关系数据库中最近邻的实现进行比较很有趣。 一个数据库在 WHERE 子句中使用一个特殊函数 SDONN 来触发最近邻搜索。 另一个在 WHERE 子句和 ORDER BY 子句中使用特殊函数 STDistance。 由于代码未公开,因此只能推测,但可以推测查询规划器已被特别修改以识别这些功能。
这与 Postgres 有很大的不同,在 Postgres 中,最近邻搜索是一种通用机制,使用标准扩展框架实现。 因此,许多其他类型的数据可以使用相同的方法,包括尚未设想的数据类型和索引方法。
原文链接:A Deep Dive into PostGIS Nearest Neighbor Search
BimAnt翻译整理,转载请标明出处





