NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
在 Datagen,我目前担任 AI 研究负责人,我们创建常见 3D 环境的合成逼真图像,用于训练计算机视觉算法。 例如,如果你想教一个家庭机器人在像下面这样凌乱的卧室里导航,你将需要相当长的时间来收集足够大的训练集的真实图像 [人们通常不喜欢外人进入 他们的卧室,他们绝对不会喜欢拍下他们乱七八糟的照片]。

我们使用图形软件生成了上面的图像。 一旦我们(在软件中)构建了环境和其中所有内容的 3D 模型,我们就可以使用它的光线跟踪渲染器在我们想要的任何光线条件下从我们喜欢的任何相机视角生成场景图像。 我们有完全的控制权。
现在,如果你认为收集真实图像很困难,请等到你尝试标记这些图像。 你需要启动一项耗时长且成本高昂的标记操作,以教人们如何根据你的标准标记这些像素。 当然,对于合成图像,我们可以轻松地为图像的任何方面生成像素完美的标签,包括人类无法评估的东西,如深度和表面法线贴图。

1、收集3D资产
为了帮助我们的用户训练她的机器人,我们需要像上面那样生成数万间卧室,我们需要在里面装满东西:家具、布料、书籍、用过的杯子、遥控器等。因此, 我们维护着大量艺术家制作的 3D 对象(我们称之为资产)。 我们的目录涵盖超过一百万件物品,我们为此感到自豪。
每个资产对象都包含一个详细的 3D 网格(由三角形组成的多边形结构,它定义了对象的形状)和一个纹理贴图(一个图像,它定义了对象的外观,就好像它是用来 覆盖网格表面)。

除了视觉上定义对象的网格和纹理贴图之外,为每个资产存储的其余信息是 3D 艺术家决定放入文本元数据文件的任何信息,例如对象的类型(“餐椅”) ,以及当时看起来相关的任何标签。
因此,只能使用它们的元数据属性来搜索目录(例如,“给我所有有 3 条腿的表”)。 如果艺术家没有写出每张桌子的腿数,那么要知道哪些桌子是三条腿的唯一方法就是一张一张地打开他们的 3D 模型文件看。
2、Asset-2-Vec
我们建议在嵌入空间中对每个资产进行编码,这将封装整个资产的形状和外观。 很像 Word2Vec,它给字典中的每个词一个“代码”向量,对应于 n 维空间中的一个位置,这样语义相似的词彼此靠近,我们想为我们的每个资产分配一个向量 ,这样我们就可以通过查看向量来判断资产的所有视觉属性。
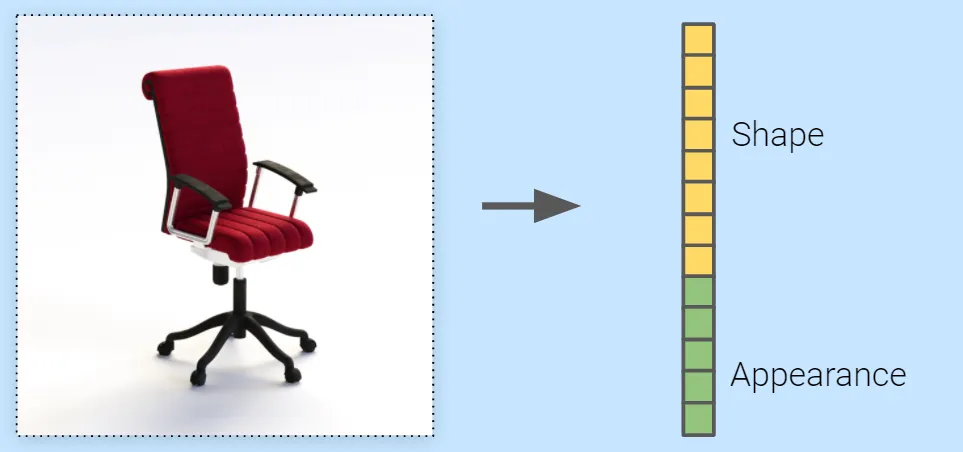
理想情况下,我们还希望将形状属性(例如,腿的数量)与外观属性(如颜色或材料)分离。 我们怎么知道向量确实捕获了对象的全部本质? 最终的方法是能够从矢量返回到资产的 3D 模型。
你可以想象一个神经网络,它将学习读取矢量作为输入,并输出资产的原始网格和纹理贴图。 然而,这将很难。 每个资产的网格都有完全不同的拓扑结构:不同数量的三角形,每个节点的不同含义,纹理贴图和网格之间的映射格式不同。 我们还需要其他东西,一种适合所有资产的替代 3D 表示。
3、NeRF
这就是 NeRF 的用武之地。你还记得,在我之前的帖子中,我展示了如何使用从不同角度拍摄的 40 张左右的物体图像,我们可以训练神经网络来学习物体周围的整个空间。 经过训练的神经网络将空间中的一个点 (x, y, z) 作为输入,并返回该点材料的颜色 (r, g, b) 和不透明度 (α)。 网络对空间的了解非常好,以至于渲染器可以拍摄对象的“照片”,只需在模拟“相机”发出的光线沿线的点上查询该网络即可。
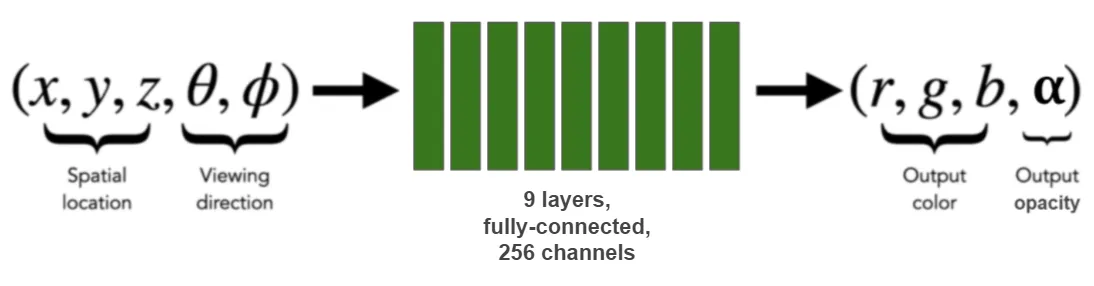
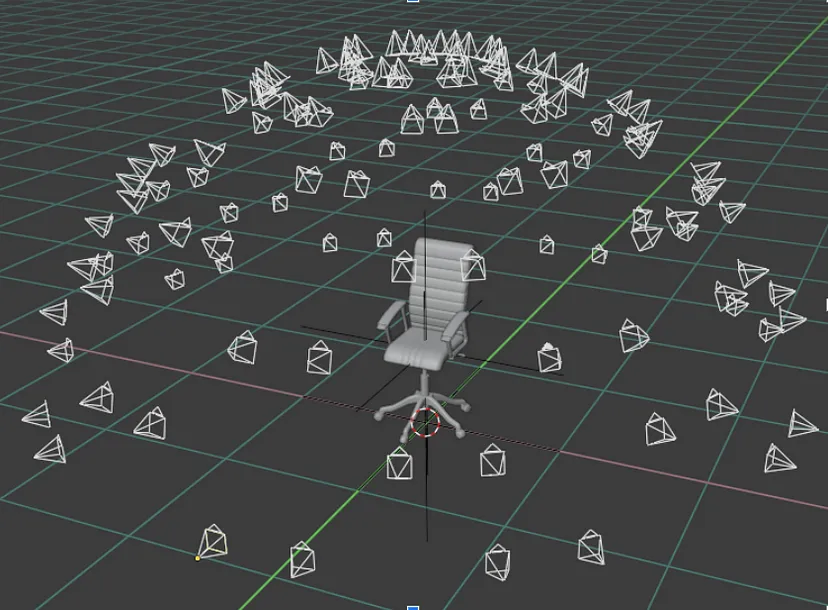
我们可以轻松获得涵盖目录中每项资产的 40 张图像。 我们只是使用来自其原始网格模型的图形软件渲染它们(所以我们不妨渲染 80)。 然后我们可以使用这些图像来训练 NeRF 网络来编码物体周围的空间。 网络训练完成后,我们可以生成一段短片,从各种新角度展示物体,其中每一帧都是通过查询训练好的 NeRF 网络来渲染的。
我们在Blender中从各个方向渲染资产的 80 个合成图像(每个金字塔都是一个模拟相机),用于训练 NeRF 网络
通过查询经过训练的 NeRF 网络,对象从 80 个新视点渲染,跨越 360 度:

我们接下来要做的是使用单个 NeRF 网络来编码,不仅是单个资产(如上面的椅子),而是我们目录中的所有椅子。 这个单一网络将具有与 NeRF 网络完全相同的架构。 唯一的区别是它将有一个额外的输入:分配给每把椅子的(潜在)向量,它将在训练期间学习。 我们将像训练 NeRF 网络一样训练这个网络,除了我们将使用从我们目录中的所有椅子上拍摄的照片。
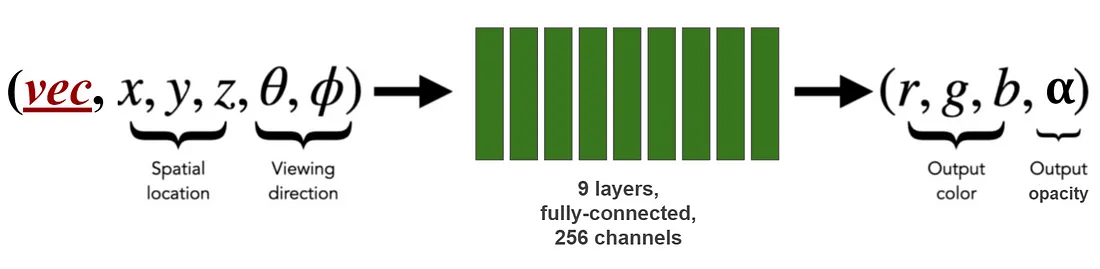
这种训练不同于普通训练,因为除了自身的权重之外,网络还学习了一组与每把椅子相关的特殊变量——它的潜在向量(类似于嵌入层的学习方式)。 当我们反向传播从渲染椅子图像中获得的错误时,不仅 NeRF 网络的权重会更新,还会更新分配给该特定椅子的潜在向量中的值(例如 vec 输入)。
一旦我们训练了这个网络,我们就可以用它来制作目录中所有椅子的电影! 要渲染任何特定的椅子,我们只需要在查询时将该椅子的潜在代码作为 NeRF 网络的输入。
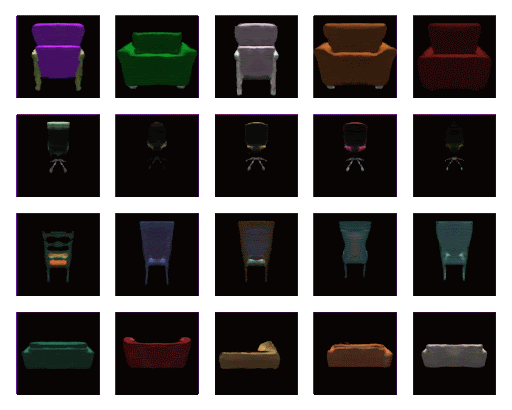
下图是通过查询单个 NeRF 网络呈现的椅子资产样本。
4、探索隐空间
我们不需要将自己局限于为当前目录中的资产学习的向量。 我们还可以探索当我们任意更改潜在向量或混合匹配来自两种不同资产的潜在向量时会发生什么。 也许在不久的将来,我们将能够以这种方式用新资产丰富我们的目录:

在上图中,当 NeRF 网络的输入将椅子 i 的潜在向量的形状部分与椅子 j 的外观部分相结合时,就会生成位置 (i, j) 的椅子。
为了直观地了解资产潜在空间的样子,我们可以使用 TSNE 算法将我们的资产放置在二维平面上(根据它们的隐向量):
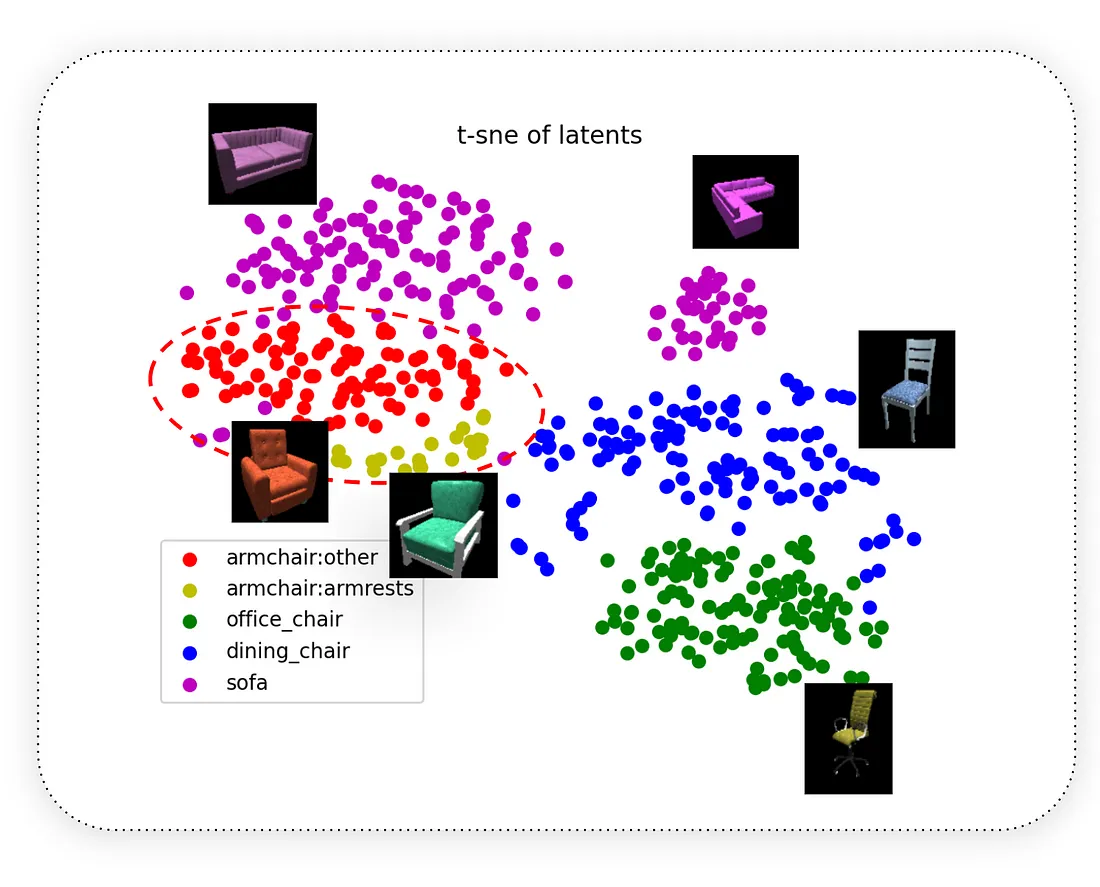
上图是我们 522 个资产的向量的 T-SNE 图。 明确区分对象类和子类。
我们可以看到椅子的不同子类之间的分离是明显的,即使在一个子类(即扶手椅)中,我们也可以很容易地找到椅子共享视觉属性的区域(即带木制扶手的扶手椅与带软垫扶手的扶手椅) .
这就是重点,不是吗? 因为这意味着我们可以轻松地训练一个线性分类器(如 SVM)来识别我们关心的任何视觉属性,只需为其提供一些正负资产的向量,然后用它来标记其余的 1M 资产 目录,而无需加载这些资产。 这种临时分类可以为我们节省大量时间!
5、隐空间是未来
最后,这种分析不仅适用于椅子,也适用于我们目录中的所有其他资产系列。 我们可以想象一个未来,我们渲染的每个场景都将由这些潜在因素完全描述:每个资产的潜在因素、背景的潜在因素、姿势、相机角度和灯光的潜在因素。 如果我们敢于尝试,我们可以想象一个未来,传统的网格和纹理贴图将不再用于渲染合成但逼真的图像,如上图凌乱的卧室场景。

6、解耦形状及外观
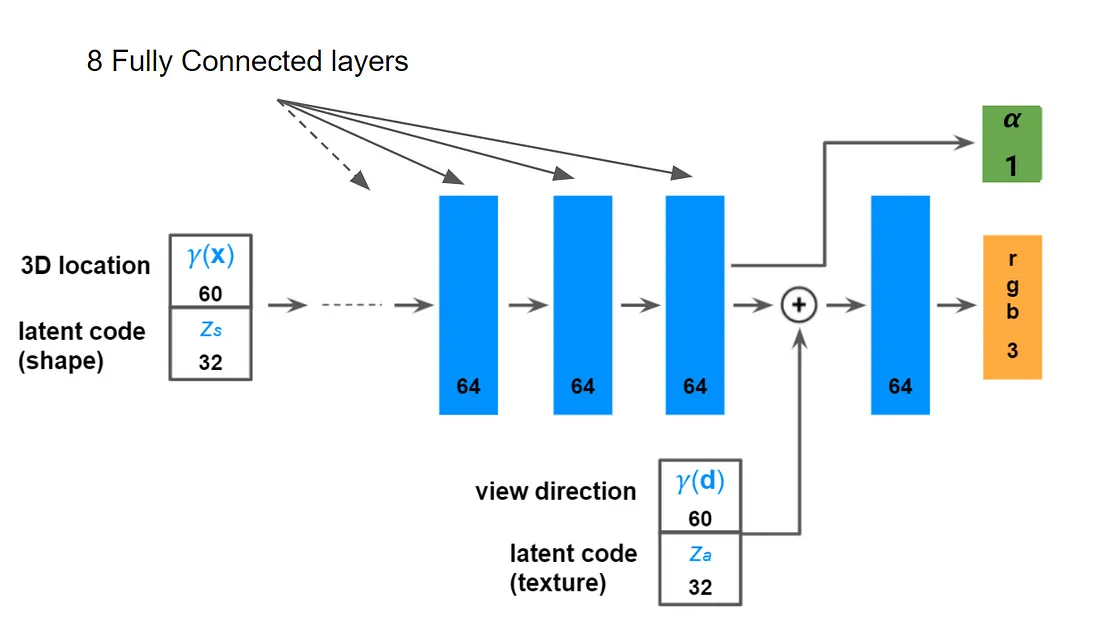
NeRF 网络有两个分支,一个用于不透明度 (α),另一个用于颜色。 为了解耦潜在向量中的形状和外观部分,我们将输入的潜在代码一分为二,并将外观部分仅显示给颜色分支,如下图所示。 这个技巧是从最近的 GIRRAFE 论文(Niemeyer 和 Geiger,CVPR 2021)中采用的。
为了更好地理解形状和外观子空间,我们对隐向量的相关部分进行了 PCA 分析:

下图是形状空间(顶部)和外观空间(底部)的前 10 个 PCA 组件的图示。

我们可以看到它们如何控制椅子的各个方面,例如座椅的大小、宽度、靠背的高度等。在外观空间中,我们可以看到 PCA 方向如何控制颜色以及它们的饱和度、亮度、 和光照条件。
原文链接:Asset2Vec: Turning 3D Objects into Vectors and Back
BimAnt翻译整理,转载请标明出处